Custom Python Data Scrapers
Dylan Kitson
Manually searching the web can be a tedious task, especially when you need to scrape information from lots of pages in the least time possible. To mitigate this problem, I've taught myself how to create data scrapers in Python.
I have previously built a spider for crawling UK supermarket product listings. Simply type the name of an item (e.g. cucumbers) into the command line and within a few milliseconds, my program a new Excel file appears on the desktop, containing a unique row for every successful spider response. This allowed me to easily sort and filter the returned data, using Excel's built-in features. I'm rather proud of that scraper but I haven't posted it here - I may eventually turn it into something bigger and better before launching it publicly!
Shown below is a very simple data scraper, programmed in Python, by me, from scratch, over approximately an hour. I've played around with various web-scraping Python libraries; scrapy, requests and requests-file. I prefer using Scrapy: the documentation is abundant and projects can be easily and quickly set up.
About the Example Data Scraper
I chose a webpage at random. The page I selected to crawl features various individual profiles of the company's employees. I wanted to retrieve each individual profile's name, position, location, sector of employment and funding source. All of this data is readily available on the webpage, but there's no one-click solution to extract the information I want from the webpage's source code.
I built a simple web crawler to retrieve this information from within the page's code. It outputs the results in a .xml spreadsheet - it's nothing fancy but it does the job in adequate time. Compiling and executing the program takes less than 1 second.
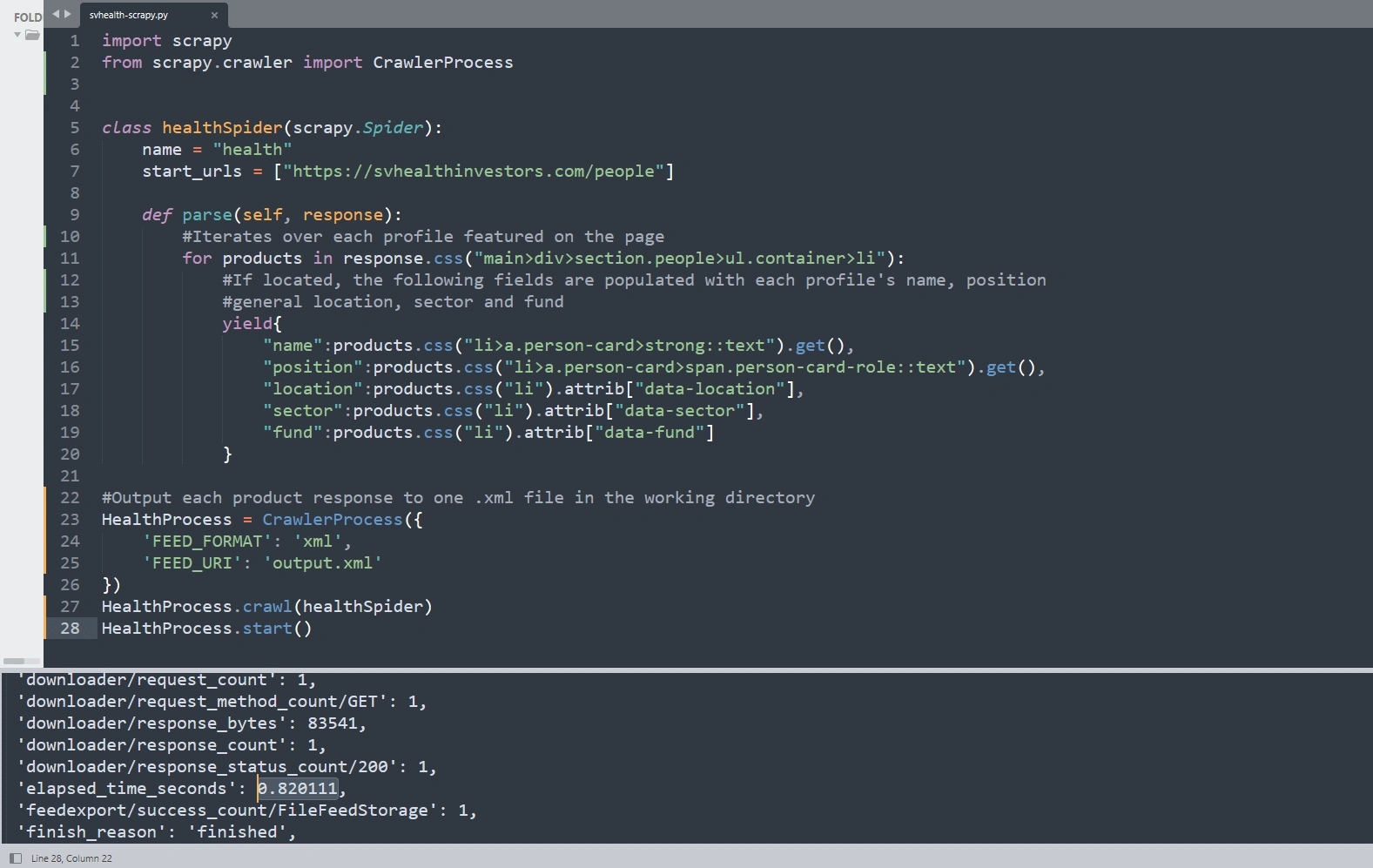
Additionally, the data scrapers I create can be fine-tuned to every situation. Bot-detection features, built-in to some websites to limit or prevent web scrapers from accessing them, can circumvented. I can transform and filter the data collected by my programs into any file type, for your convenience: PDF, Google Sheets, Microsoft Excel, XML, CVS or others.
Disclaimer: I am completely unaffiliated with the website featured in the example code.
Like this project
Posted Oct 1, 2023
Sometimes it's quicker, cheaper and easier to create a custom tool for a specific task. Data scrapers efficiently retrieve other website's content.