Exploring Vector Databases: Empowering AI Applications
Paolo Perrone
In the vast landscape of data management, vector databases have emerged as a game-changer, enabling efficient handling of complex data structures known as vector embeddings. These databases have revolutionized the way we process and query data, offering optimized storage and retrieval capabilities that traditional scalar-based databases struggle to match. To grasp the significance of vector databases, let's delve deeper into their inner workings and explore their benefits for various applications.
In this article, we will explore the workings of vector databases, the algorithms they employ, the importance of similarity measures, and how they enhance data processing for AI applications.
Understanding Vector Databases
Vector databases have revolutionized the way we handle complex data structures known as vector embeddings. These databases offer optimized storage and querying capabilities, addressing the limitations faced by traditional scalar-based databases. In simple terms, they provide efficient data processing for a wide range of applications involving large language models, generative AI, and semantic search.
At the core of a vector database lies the concept of indexing. Indexing involves mapping vectors to a data structure that facilitates faster searching. To achieve this, vector databases employ advanced algorithms such as Random Projection, Product Quantization, Locality-Sensitive Hashing (LSH), or Hierarchical Navigable Small World (HSNW). These algorithms transform high-dimensional vectors into a more manageable form, enabling efficient querying and retrieval of relevant information.
When a query is issued to a vector database, it undergoes a process known as querying. The database compares the indexed query vector to the vectors in the dataset, employing a similarity metric specific to the indexing algorithm used. Based on this measure of similarity, the database retrieves the nearest neighbors or the most relevant vectors that closely match the query. This querying process is the heart of vector databases, allowing for quick and accurate retrieval of data.
To enhance the precision and accuracy of search results, vector databases often employ post-processing techniques. These techniques involve additional operations on the retrieved nearest neighbors, such as re-ranking them using a different similarity measure. By refining the results through post-processing, vector databases can provide more accurate and meaningful information to the users.
To accomplish their tasks, vector databases utilize a variety of algorithms, each with its own strengths and characteristics. One such algorithm is Random Projection, which reduces the dimensionality of vectors by projecting them onto a lower-dimensional space using a random projection matrix. This transformation allows for faster searching by operating in a reduced-dimensional space rather than the original high-dimensional space.
Algorithms Used in Vector Databases
Vector databases employ a range of algorithms to facilitate efficient data processing. Random Projection, for example, projects high-dimensional vectors onto a lower-dimensional space using a random projection matrix. This reduction in dimensionality speeds up searching in the database.
Product Quantization (PQ) is another algorithm that aids in compressing high-dimensional vectors. By breaking the vectors into smaller segments, assigning representative codes to each segment, and reconstructing them, PQ strikes a balance between representation accuracy and computational cost.
Locality-Sensitive Hashing (LSH) maps similar vectors into "buckets" using hashing functions. Query vectors are then compared to vectors in the same bucket to find close matches. Although this method provides approximate results, it significantly speeds up the search process compared to exhaustive search.
Hierarchical Navigable Small World (HSNW) algorithms construct a hierarchical tree-like structure, where nodes represent sets of vectors and edges denote similarity. Navigating through this tree efficiently leads to finding nodes that likely contain the closest vectors to the query vector.
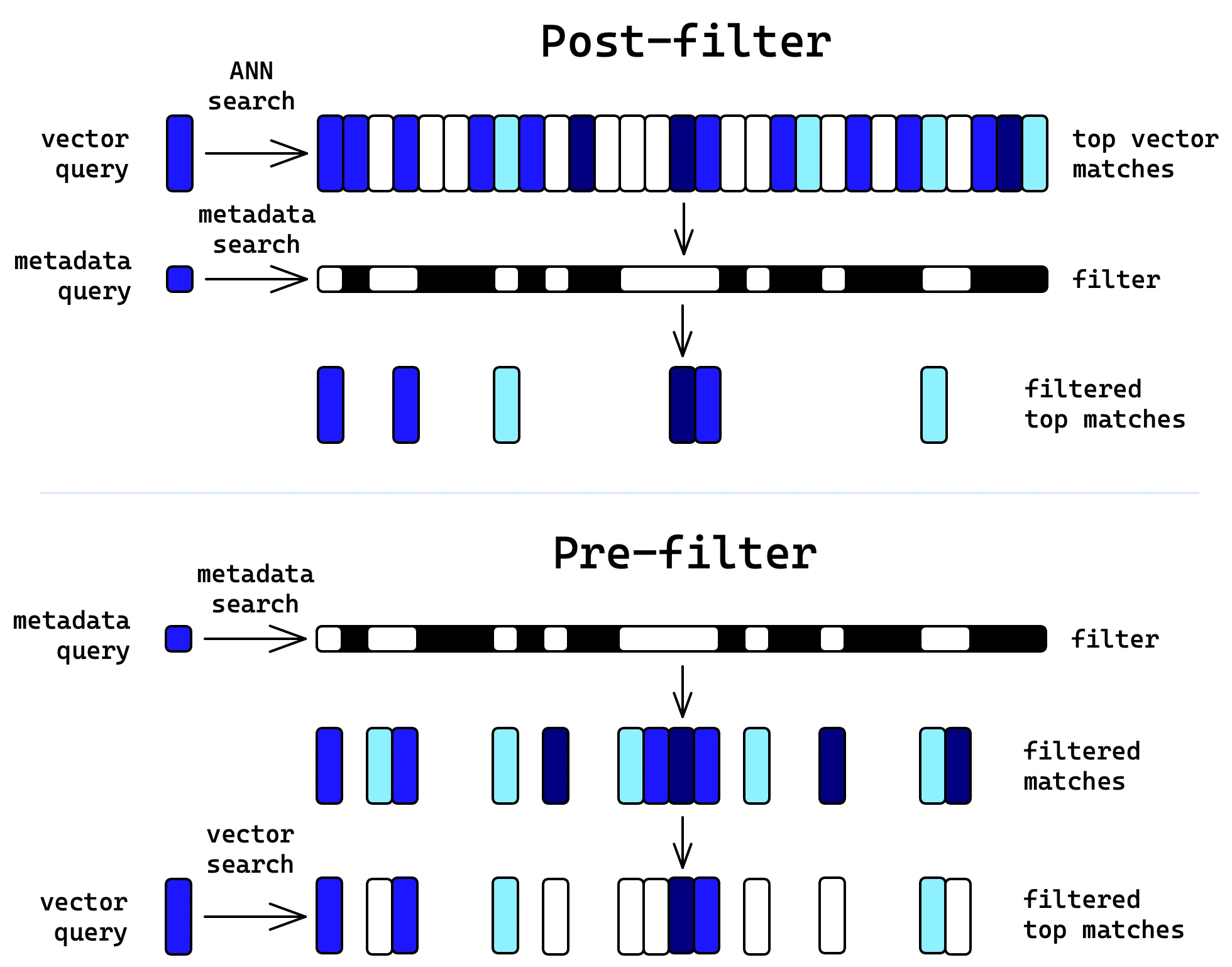
Importance of Similarity Measures
Similarity measures play a critical role in vector databases, as they determine the similarity between two vectors in a vector space. Common similarity measures include cosine similarity, which measures the cosine of the angle between two vectors; Euclidean distance, which calculates the straight-line distance between two vectors; and dot product, which measures the product of their magnitudes and the cosine of the angle between them.
These similarity measures assist in finding the most relevant vectors and refining search results. They enable vector databases to identify vectors that align closely with the query vector, ensuring accurate and meaningful data processing.
Advantages and Applications of Vector Databases
Vector databases offer several advantages and find application in various domains. By leveraging advanced indexing methods for metadata, parallel processing, and fault-tolerant storage, these databases ensure high performance and fault tolerance. They empower developers to handle vector embeddings effectively, providing scalability and flexibility required for AI applications.
The applications of vector databases are vast. They are instrumental in language modeling, enabling the creation of sophisticated AI systems that understand and generate human-like text. They also facilitate semantic search, improving

Unlocking the Full Potential of Vector Databases
Vector databases provide a comprehensive range of capabilities tailored to high-scale production settings. They ensure optimal performance and fault tolerance through advanced indexing methods for metadata, parallel processing, and fault-tolerant storage. These capabilities enable efficient and relevant query results, empowering developers to handle vector embeddings effectively.
In conclusion, vector databases have emerged as a revolutionary solution for handling complex data structures, particularly vector embeddings. These databases have paved the way for efficient and optimized data processing, transforming the landscape of data management. By understanding the inner workings of vector databases and their diverse algorithms, we can fully grasp their power and unlock their potential across a wide range of applications.
Like this project
Posted Jun 11, 2023
Vector databases: game-changers in data management. Efficiently handle complex vector embeddings. Optimized storage and querying. Revolutionizing AI application
Likes
1
Views
44
Clients
Contra