The journey from the data warehouse to the Modern Data Stack
Paolo Perrone
The journey from the data warehouse to the Modern Data Stack
The explosion of data in recent years has made the data stack an essential component for any business seeking to stay competitive. However, the ever accelerating rate of technological innovation and the proliferation of technical jargon make grasping the concept of Modern Data Stack challenging, even for those with a technical background.

What is a data stack?
In technology, the term stack is used to describe a group of components that work together to achieve a common goal. Software engineers leverage a technology stack to build products for various purposes. Likewise, a data stack, refers to an interconnected set of tools and technologies that enable businesses to gather, store, process, and analyze data in a scalable and cost-efficient way. The ultimate goal of a data stack is to transform raw data into valuable insights that inform decision-making.
By the end of this article, you will have a thorough understanding of the components of a Modern Data Stack, its evolution from the early days and how it differs from a traditional one.
Ready? Let's dive in!
The catalysts of the Modern Data Stack
The Rise of Hadoop and Horizontal Scaling
The year 2005 marked a significant turning point in the world of data. It was the year that Doug Cutting and Mike Cafarella launched Hadoop, an open-source framework for horizontal storage and processing of large data sets.
In computing, horizontal scaling is a method of adding more machines to a system to increase its processing power. Vertical scaling, on the other hand, requires increasing the resources of a single machine, like adding more memory or a faster CPU. Since horizontal scaling is typically more cost-efficient than vertical scaling, the introduction of Hadoop provided a cost-effective solution for storing and processing large volumes of data without the need for expensive infrastructure, which for the majority of businesses is still prohibitive today.
With the mass digitalization of the early 2000s, businesses faced the growing challenge of storing and analyze large volumes of unstructured or semi-structured data such as images, videos, social media posts, and other types of documents. While, traditional relational databases such as Oracle or MySQL were designed to handle only structured tabular data, Hadoop' capability to manage both accelerated its adoption.
Although Hadoop represented a significant improvement for the time, it was a complex system to handle. As data volumes grew, so did the challenge of managing and analyzing it with Hadoop, making it an unfeasible solution for organizations lacking the required technical resources and expertise.

AWS and the Revolution of Cloud Data Warehouses
In 2006, AWS came onto the scene as a solution to tackle the challenges presented by on-premise data warehouses. It revolutionized the landscape by introducing the capability to connect to virtual computers and leverage remote storage. Unlike traditional on-premise data warehouses that require significant investment in hardware and infrastructure, cloud data warehouses offer businesses on-demand access to scalable computing resources. By leveraging cloud data warehouses, businesses could offload the burden of infrastructure management to providers like Amazon Web Services, Google Cloud Platform and Microsoft Azure, allowing them to focus on analyzing their data instead.
The next breakthrough was the introduction of Amazon Redshift in 2012. Prior to this, managing and manipulating data, especially non-relational data[^1], remained cumbersome and error-prone. The advent of microservices architecture[^2] had popularized non-relational databases, but when this data was loaded into a Hadoop cluster[^3] it was difficult to process using SQL[^4].
The arrival of Redshift revolutionized data management, enabling organizations to store data on the cloud, eliminating the need for on-premise hardware. Before the introduction of Redshift, data belonged to IT. Teams and employees outside IT had to ask IT teams to query data for them. In turn, IT teams were constrained to using languages like Java, Scala, and Python, creating a barrier to data accessibility.
In addition, Redshift's native optimization for both relational and non-relational data enabled businesses to run queries using standard SQL language, which made it 10-1000x faster[^5] and 100x cheaper[^6] than existing solutions at the time. Although several data tools had emerged around the same time or even earlier, Redshift proved to be the true catalyst that propelled the data industry forward.
The Modern Data Stack
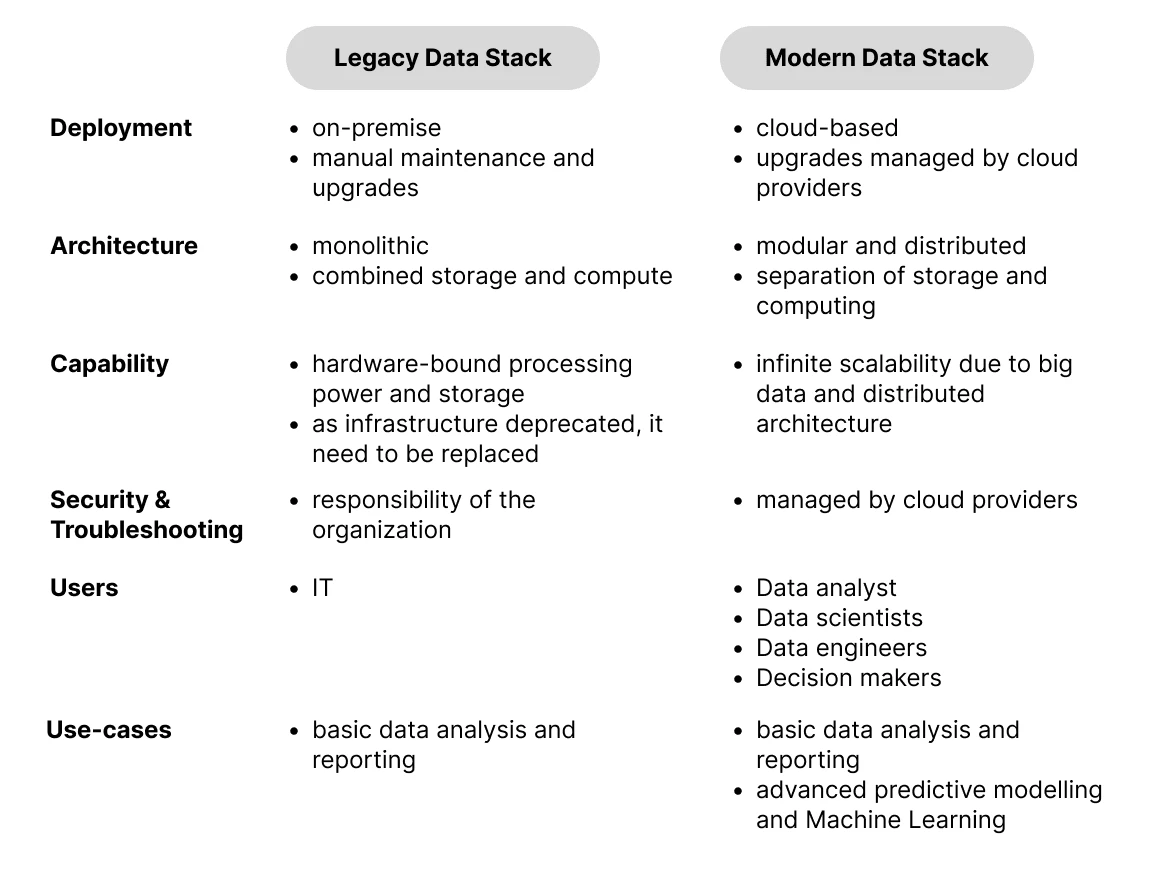
The legacy on-premises data stack was built in house and deployed on premise. These structures were based on monolithic architectures and custom-built components, that required significant IT infrastructure and personnel investments. Due to on-premise data processing, performance scalability was limited by the installed hardware capacity, making it overall a complex, rigid, and expensive structure to maintain and scale.
In contrast, the modern data stack leverage a cloud data warehouse for processing and integrates off-the-shelf components that focus on specific aspects of data processing/management. This modular approach makes the MDS highly scalable and easy to manage. Many MDS tools are actively supported by communities and offered as either SaaS or open-core. Modern data stack tools are designed to be easy to use, with low-code or no-code design and usage-based pricing models that make them accessible to businesses of all levels.
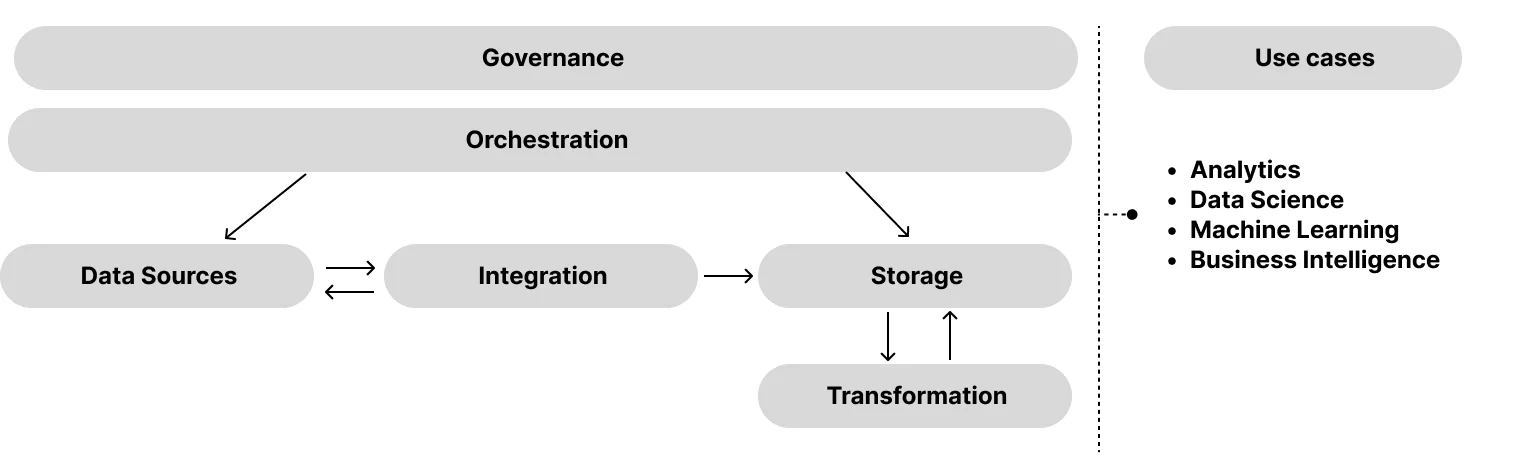
A modern data stack typically consists of six key phases, each incorporating a distinct set of technologies that work together to provide specific functionalities. This framework enables a range of use cases from analytics to business intelligence, data science and machine learning.
The composition of a modern data stack depends on the specific needs and scale of an organization, which determine whether a component is a single tool or a combination of multiple tools. In our forthcoming article, we will delve into each phase and explore the associated components in detail.
Notes
[^1]: Non-relational data, also known as NoSQL (Not Only SQL), refers to a type of database that is designed to handle unstructured or semi-structured data, such as documents, graphs, or key-value pairs, which cannot be easily stored in traditional relational databases. Unlike relational databases, NoSQL databases are often schema-less and don't require a predefined structure for data storage. This flexibility makes them well-suited for handling large volumes of unstructured data that may be too difficult or expensive to store in a traditional relational database.
[^2]: Microservice architecture is a software development approach where a complex application is broken down into a set of smaller, independent services. Each service is designed to perform a specific task, and the communication between services is typically through well-defined APIs.
[^3]: A group of computers that work together to store and process large datasets.
[^4]: SQL (Structured Query Language) is a standard programming language used for managing and manipulating relational databases. It allows users to create, read, update and delete records in a database, as well as retrieve and manipulate data stored in tables. SQL is widely used in business and web applications for data management and analysis.
[^5]: The reason for that is internal architectural differences. Redshift is designed for massively parallel processing (MPP) and online analytic processing (OLAP) as opposed to online transaction processing (OLTP).
[^6]: In 2012, the price to manage a terabyte of data was less than $1,000 per year with Redshift, as opposed to spending over $100,000 to build a comparable infrastructure.
Like this project
Posted May 17, 2023
This article introduces the modern data stack and traces its evolution from the early days, highlighting the differences between modern and legacy systems 🤖
Likes
1
Views
29
Clients
Contra