Navigating the Data Chaos A Guide for Non-Technical Founders
Paolo Perrone
In this article, we will explore the world of data operations in early-stage startups.
This article is specifically designed for non-technical founders who have limited to no experience with data tools like SQL and Python. Founders that primarily rely on spreadsheets for data-related tasks and live far away from data scientists and data engineers.
In what follows, we will paint a realistic picture of data operations in the early stages and provide guidance as to when is the right timing to invest in a data stack. Rest assured, we will steer away from overwhelming technical jargon and obscure acronyms, making this exploration clear and accessible to all.
Let the data chaos begins
In the early days, the founder's data stack typically consist of a single marketing and sales tool like Intercom and HubSpot. As the company grows and new team members join, additional tools are introduced to facilitate their roles.
For example, the marketing team brings in platforms like Mailchimp for email campaigns, Marketo for customer engagement analysis, HubSpot for lead management, WordPress for website maintenance, and Google Analytics for tracking website traffic.
Sales team adopt CRMs like Salesforce or Pipedrive, while customer support relies on Zendesk or Intercom. Product teams implement project management tools like Jira or Asana, and finance and accounting use software such as QuickBooks or Xero, along with spreadsheet tools like Excel or Google Sheets. Human resources teams leverage applicant tracking systems like Workday or Greenhouse and employee management platforms like BambooHR or Gusto. Meanwhile, the founding team still manually tracks some key metrics in a spreadsheet.
Dealing with this array of tools might already feel overwhelming. In reality, this rather modest stack barely scratches the surface of the complexity startups face.
The complexity of the data operations extends beyond individual departmental tools and intertwines with the very fabric of the startup's business model. Think of a company that is managing advertising campaigns on Facebook, LinkedIn, and Google or a marketplace that employs separate CRM systems for providers and buyers.

The ramifications of data chaos
Now picture this.
Data is generated and stored within disparate tools that were never designed to work together. Data cannot be easily accessed and analyzed, and even answering the most basic questions require a lot of frustrating back and forth. Downloading data from each separate tool, validating and reconciling data against different sources, and then combine the results back into a spreadsheet.
Each analysis is a 2+ weeks time-consuming endeavor that becomes outdated by the time it is completed. The static nature of the analysis demands its repetition every single time. Each manual step multiply the chances of making errors and divert valuable time from other essential business tasks.
Step in the world of data chaos, where the wild tangle of information cause teams to lose trust in their report and analysis.
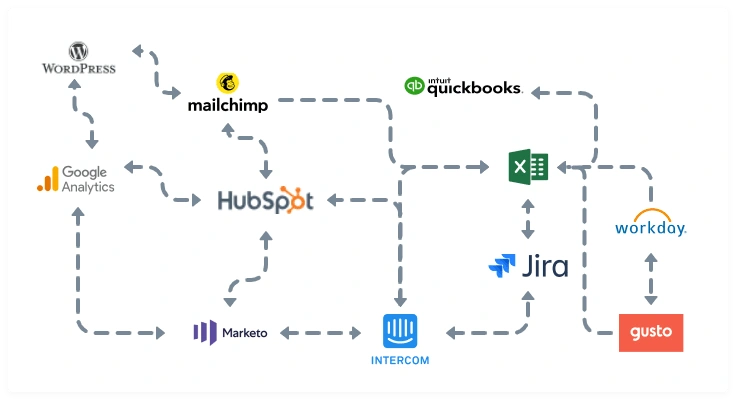
How to untangle the data chaos?
There are two different approaches here.
As we mentioned earlier, the tools were never designed to work together. Sure, you can make them talk to each other through point-to-point integration, but this fragmentation just adds to the chaos. Without a centralized control system to govern the flow of data across all these tools, troubleshooting or making necessary changes becomes an incredibly daunting task.
Moreover, the point-to-point integrations are built with custom code that is a nightmare to maintain over time. Pretty early on, automations and workflows will start to break down, sending the wrong email to the wrong person with the wrong personalized value. Incompatible IDs will spawn a proliferation of duplicate records, further exacerbating the chaotic state of data confusion. This situation is a true recipe for disaster prevent insights altogether.
Indeed, there is a straightforward solution here.
Centralize all the data in a single repository that harmonizes fragmented bits of information and establish a unified, shared view across teams. This centralized repository acts as a single source of truth for the entire organization, minimizing redundancy and preserving data integrity. In addition, it facilitates data synchronization across all tools, equipping everyone with consistent and reliable information while allowing individuals to continue using the tools they prefer.
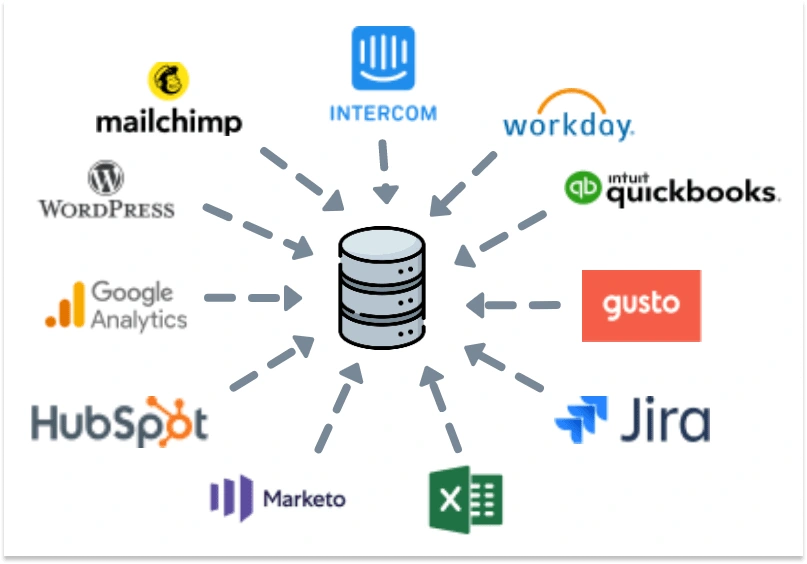
Once everyone in the organization is working from the same system, collaboration and decision-making are enhanced throughout the entire organization.
Just a few years ago, implementing this centralized data stack was impossible or prohibitively expensive endeavor. Nowadays, thanks to the progress of cloud-based computing, even early-stage businesses can deploy a flexible infrastructure that is easy to deploy and requires near-zero maintenance.
At this point you may find yourself wondering, where should I begin, and more importantly, what steps should I take?
Follow along in the next article in the series, where we will present the concept of Minimum Viable Data stack and provide practical recommendations on the essential tools you need to get started.
Join us on this journey to bring your data operations to life.
Like this project
Posted Jun 11, 2023
Data ops for startups: Simplifying complexity, optimizing workflows, and centralizing data for non-technical founders. Practical insights and recommendations
Likes
0
Views
32
Clients
Contra