Essential Tools for Data Fluency
Paolo Perrone
Welcome to the grand finale of our deep-dive, where we unravel the mysteries of the modern data stack for the uninitiated business leader without a technical background.
In our first article, we provided an introduction to the modern data stack, highlighting its evolution over time and emphasizing the distinctions between modern and legacy systems.
In the second article, we introduced the Three Layers Framework, which provides a conceptual understanding of the interplay between each component of the data stack and their role in transforming raw data into organizational intelligence.
In this final piece, we are going to take things down one level further. As a business leader, understanding the work of your data team and effectively communicate with data professionals is a challenge. The tech world is so vast and deep, that staying up-to-date is a struggle even for those immersed within it.
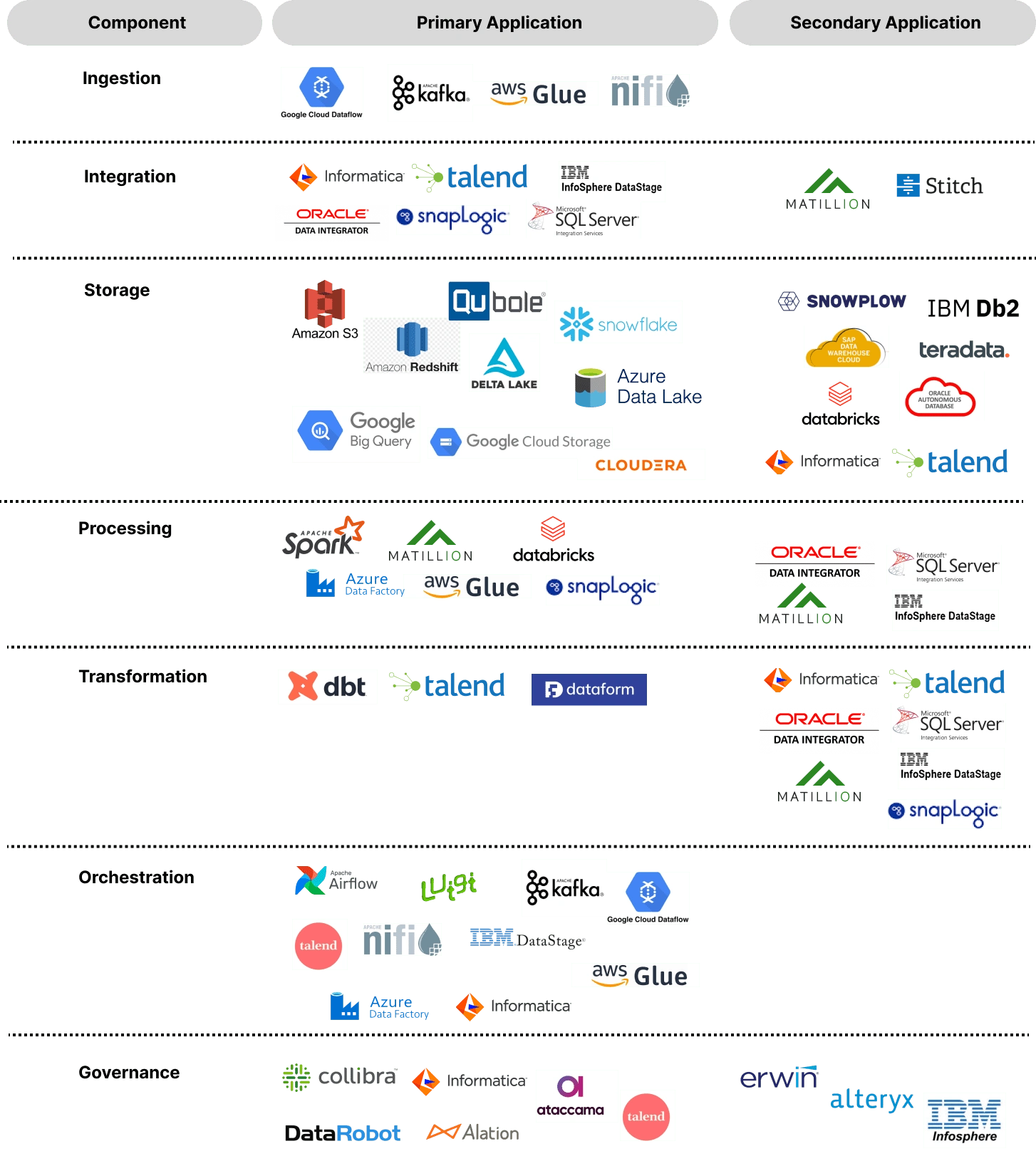
That's why, in this article, we will introduce you to the key players for each component of the data stack. Consider this article as your reference guide of essential tools you need to navigate the data landscape with confidence. Keep this guide handy, because it will help you decipher the data lingo and enhance your ability to engage in more effective communication with your data team. Ready to unlock a new level of data fluency?
Let's dive in.
The tools powering the modern data stack
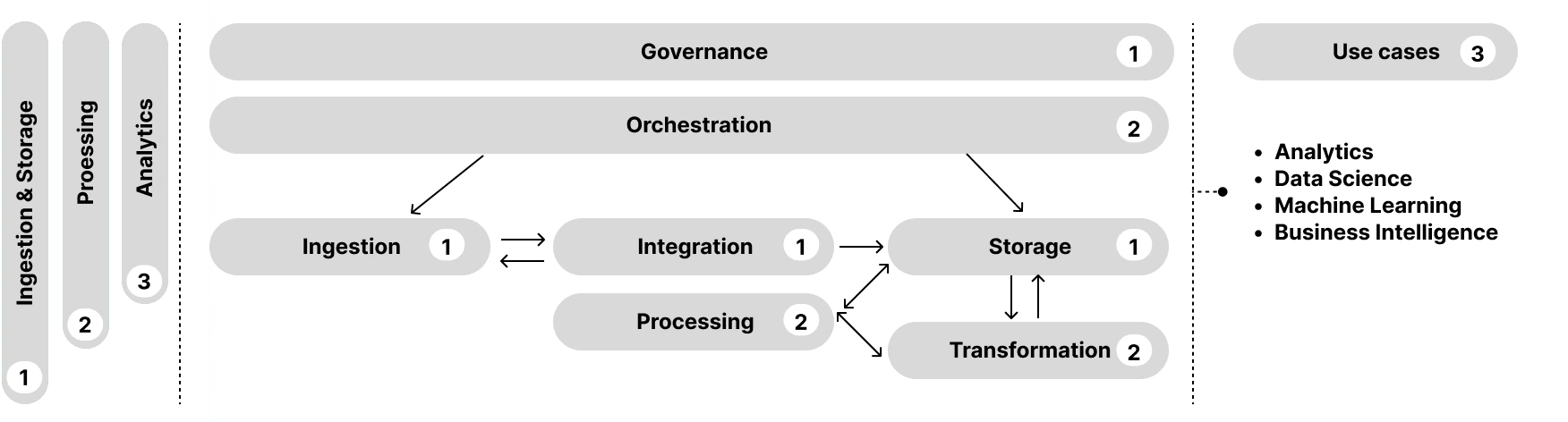
Data Ingestion
Data ingestion is the first step in any data-stack. Data ingestion tools collect, process, and prepare data for transformation into a data storage location. There are two types of data ingestion methods that organizations can use to transfer data from sources to storage.
ETL (Extract, Transform, Load) is a traditional data integration approach where data is extracted from various sources, transformed to specific business requirements, and then loaded into the storage target destination.
ELT (Extract, Load, Transform) is a data ingestion approach that has gained significant traction in recent years. In ELT, data is extracted from diverse sources and loaded directly into the target storage destination, where transformations are then applied by leveraging the cloud processing capabilities.
The main downside of ETL (Extract, Transform, Load) is the potential for increased complexity and time required for data transformation. As data is extracted from various sources and transformed separately before loading, the process can become intricate and time-consuming, especially when dealing with large volumes of data. Additionally, ETL processes may introduce delays as the transformation step is performed before loading, potentially delaying the availability of up-to-date information.
On the other hand, the main downside of ELT (Extract, Load, Transform) is the potential strain it can put on the target system's resources. Since data is loaded into the destination first, it may require significant processing power and storage capacity to handle the transformation tasks within the target system. While cloud data warehouses can effectively handle this process, it may result in increased infrastructure costs and require careful resource management to ensure optimal performance. In addition, ELT may not be suitable for all scenarios, particularly when extensive data transformations are required before analysis or when source data quality issues need to be addressed before loading.
ELT gained popularity in the early 2000s and is currently the common standard for data ingestion, because companies already store their data in the cloud and modern data warehouses are powerful enough to perform transformations at scale.

Data Integration
Organizations work with an average of 400 data sources[^6] and over 20 percent of the companies uses more than 1,000 data sources. Data lives everywhere, and data integration tools address the challenge of cleaning and normalizing data collected from various sources into a consistent format that can be stored and analyzed for future use.

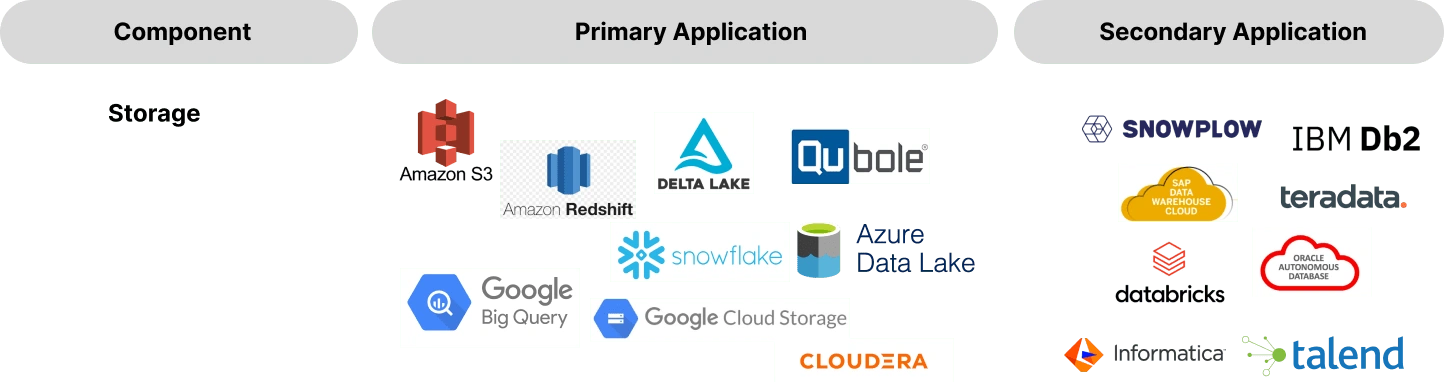
Data Storage
Data storage is the heart of the modern data stack, acting as the central repository where data from various sources is centralized and saved for future use. This central repository provides businesses with a unified view of their data, facilitating effective data management, analysis, and decision-making. This hub can take the form of a data warehouse or data lake, and is essential for supporting data-driven initiatives and ensuring the integrity and accessibility of stored information.
Data warehouses are designed for structured data analysis of large volumes of data from various sources. The data is organized into predefined schemas[^2] which ensures data consistency and accuracy. Data warehouses typically use a relational database management system (RDBMS)[^3] such as Oracle, MySQL, or SQL Server. This RDBMS use SQL[^4] for data querying and manipulation and are optimized for analytical processing and reporting.
A data lake allows storing structured, semi-structured, and unstructured data in its native format. Data lakes are a central repository where data from various sources can be ingested without upfront transformation or schema requirements. Data lakes can be implemented using various technologies, including both SQL and NoSQL databases[^4] [^5] such as Apache Cassandra, Apache HBase, or MongoDB. Data lakes enable flexibility for exploratory analysis, making it possible to derive insights from diverse and unprocessed data sources.
Data Processing and Transformation
Data transformation is the process of converting raw data into a format that is suitable for analysis. This process encompasses tasks such as cleaning, filtering, aggregating, merging, and enriching. These manipulations ensure that data is ready for further down-stream analysis.

Data Orchestration
Data stacks are complex. Orchestration is the process of managing and coordinating data workflows within an organization, to keep everything running seamlessly. This involves determining the right sequence of operations, automating repetitive processes and movement of data across various stages of the pipeline, managing dependencies and coordinating the different data tasks. Orchestration ensures a smooth flow throughout the entire data pipeline. As such, orchestration provides the backbone for data integration, transformation and, analysis.

Data Governance
Data governance encompasses the overall management and control of an organization's data assets. It involves the development and enforcement of policies and processes to ensure the reliability, security, and accessibility of data. The primary objective of data governance is to define roles and responsibilities for data management and to adhere to regulatory requirements. Data governance tools are typically introduced later in the data lifecycle.

Conclusion
In its simplest form, a data stack might only include: an ingestion tool, a storage tool, a transformation tool, and a business intelligence tool. These four components are the foundation for managing and deriving insights from data.
As organizations grow and their data needs evolve, additional tools can be introduced to enhance the data stack. The modularity of the modern data stack enables organizations to accommodate changes and integrate new technologies with a plug-and-play approach. Each organization can make technology choices based on its unique business objectives and available resources.
The versatility of a single tool to serve multiple purposes within the data stack brings a whole new level of flexibility and customization to the data process. By leveraging a tool that can perform various functions, organizations can streamline their data operations, simplify their tool set, and optimize resource utilization.
In the end, the size and scope of the organization's requirements determine the structure of the data stack and whether a component is a single tool or a combination of several ones.
Well folks, we've made it to the end of our deep dive into the modern data stack! It's been quite a journey, but we've uncovered some valuable insights along the way. From talking the history, to understanding the different layers to getting to know the key players, we've covered it all. Our goal has been to break down the technical jargon and to make this key information accessible for everyone, regardless of background. So, take a moment to pat yourself on the back for joining us on this data-driven ride.
If you have any lingering questions or need clarification on any topic discussed, don't hesitate to reach out. We're here to help you harness the power of data, and we're excited to assist you on your data-driven journey.
Thanks for joining us, and until next time, keep exploring the potential of data!
[^1]: Integration in the ingestion and storage layer and transformation in the processing layer have some similarities but serve different purposes in the data stack. Integration prepares data for storage, while transformation prepares data for analysis and insights.
[^2]: A database schema is the framework that outlines the structure and rules for organizing data in a database. It determines the fields that make up each table, the relationships between tables, and the constraints that ensure data integrity. Defining the schema provides a blueprint for how data is organized and how it can be accessed and manipulated.
[^3]: A Relational Database Management System (RDBMS) is a software system that manages relational databases. An RDBMS uses a structured approach to store and manage data, where data is organized into tables with predefined schemas and relationships. One of the key advantages of using an RDBMS is the ability to enforce data integrity and maintain consistency through features such as primary keys, foreign keys, and constraints. It's important to note that RDBMSs are just one type of database management system. Other types include NoSQL databases, which are designed for handling unstructured or semi-structured data and provide greater scalability and flexibility in data modeling. The choice between an RDBMS and other database systems depends on the specific requirements of the application and the nature of the data being managed.
[^4]: SQL (Structured Query Language) is a standard programming language used for managing and manipulating relational databases. It allows users to create, read, update and delete records in a database, as well as retrieve and manipulate data stored in tables. SQL is widely used in business and web applications for data management and analysis.
[^5]: NoSQL databases, also known as "not only SQL" databases, are a category of databases that differ from traditional relational databases in their data model and storage approach. Unlike relational databases, which organize data into tables with a predefined schema, NoSQL databases are designed to handle large volumes of unstructured, semi-structured, and structured data without the need for a fixed schema. NoSQL databases offer flexible data models that can adapt to changing data requirements and evolving application needs. They are often chosen for their ability to scale horizontally across multiple servers, providing high performance and scalability for handling massive amounts of data.
[^6]: Matillion and IDG Research: https://www.matillion.com/resources/blog/matillion-and-idg-survey-data-growth-is-real-and-3-other-key-findings,
Like this project
Posted May 25, 2023
This article introduces the key players for each component of the data stack, providing a reference guide to navigate the data landscape with confidence 🛠️
Likes
1
Views
51
Clients
Contra