Scalable Azure Data Engineering Solution Implementation
Devowise Studios
Verified
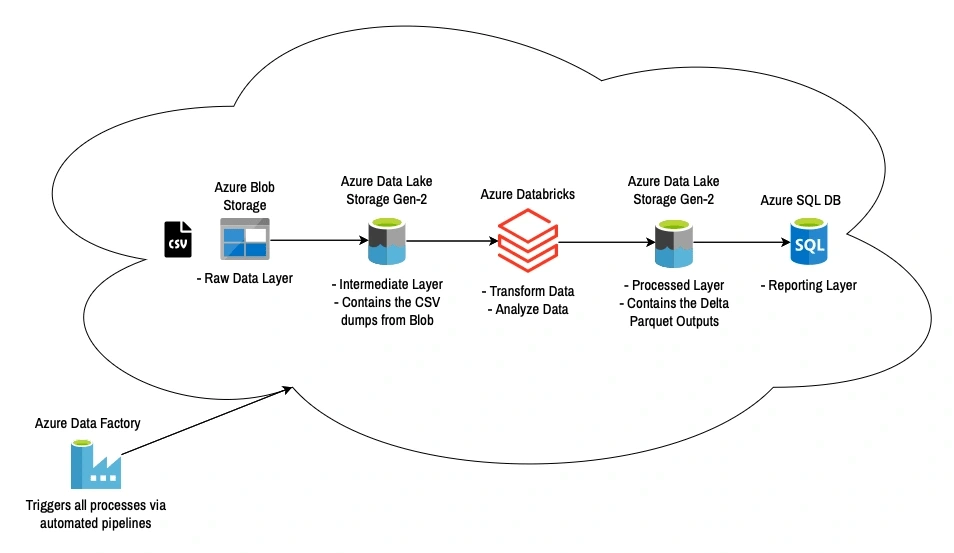
Designed and implemented a scalable end-to-end Azure data engineering solution to ingest, process, transform, and serve enterprise data for analytics and reporting. The solution leverages Azure's cloud-native services to automate ETL workflows and deliver reliable reporting datasets.
Architecture
The solution follows a modern medallion-style data pipeline:
Azure Data Factory (ADF)
Orchestrates and automates the complete data pipeline.
Schedules data ingestion and transformation workflows.
Monitors pipeline execution and handles failures.
Azure Blob Storage (Raw Layer)
Stores raw CSV files received from source systems.
Acts as the landing zone for incoming data.
Azure Data Lake Storage Gen2 (Intermediate Layer)
Transfers raw files from Blob Storage.
Maintains historical copies.
Serves as the staging layer before transformation.
Azure Databricks
Performs data cleansing and validation.
Applies business transformation logic using PySpark.
Handles joins, aggregations, deduplication, and data quality checks.
Optimizes processing using Spark.
Azure Data Lake Storage Gen2 (Processed Layer)
Stores transformed data in Delta/Parquet format.
Provides optimized datasets for downstream analytics.
Azure SQL Database
Loads curated data into reporting tables.
Supports BI dashboards and analytical reporting.
Technologies Used
Azure Data Factory
Azure Blob Storage
Azure Data Lake Storage Gen2
Azure Databricks
PySpark
Delta Lake
Parquet
Azure SQL Database
SQL
Git
Key Features
Automated end-to-end ETL orchestration
Scalable cloud-based architecture
Incremental data processing
Data validation and cleansing
Delta Lake implementation
Optimized Spark transformations
Reporting-ready SQL data warehouse
Automated scheduling and monitoring
Fault-tolerant pipeline execution
Business Impact
Reduced manual data processing by over 90%
Improved data availability for reporting
Enabled near real-time analytics
Increased pipeline reliability through automation
Established a scalable data platform capable of handling growing data volumes
My Role
As the Azure Data Engineer, I was responsible for:
Designing the overall architecture
Developing Azure Data Factory pipelines
Building Databricks notebooks using PySpark
Implementing Delta Lake transformations
Loading curated datasets into Azure SQL Database
Testing and optimizing pipeline performance
Monitoring production workloads and resolving issues

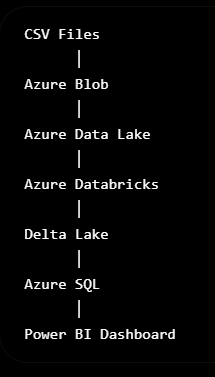
Files System
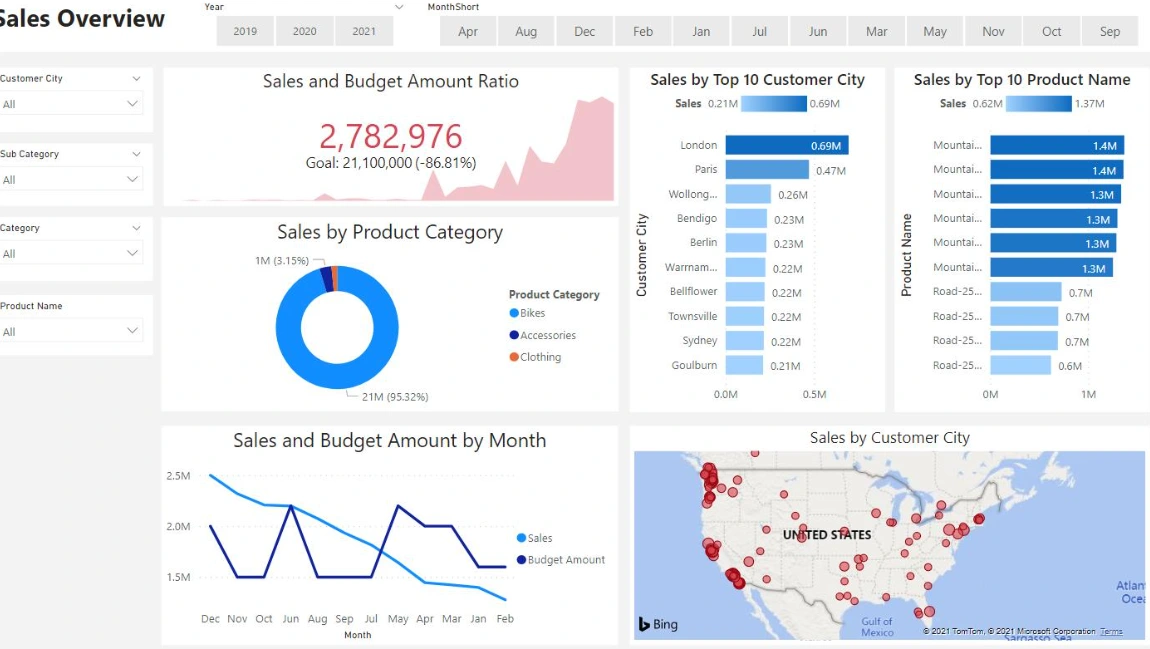
Dashboard Reporting
Process
Like this project
What the client had to say
Nabeel delivered exceptional results, building efficient ETL pipelines and optimising our data infrastructure with precision. He was proactive and aligned the work perfectly with our business goals. A highly skilled and reliable partner!
Raheel Farooq
May 26, 2025, Client
Posted Jul 3, 2026
Built an end-to-end Azure data pipeline using ADF, Databricks, ADLS Gen2, Blob Storage, and Azure SQL for automated ETL and reporting.
Likes
1
Views
5
Timeline
May 21, 2025 - May 26, 2025