Supply Chain Optimization using AWS Services
Devowise Studios
A leading merchandise distributer named as Vendermac, wanted to harness the power of their retail data to gain insights and make data-driven decisions. They approached me to design and implement an end-to-end data engineering pipeline on AWS to streamline data processing, storage, and analysis.

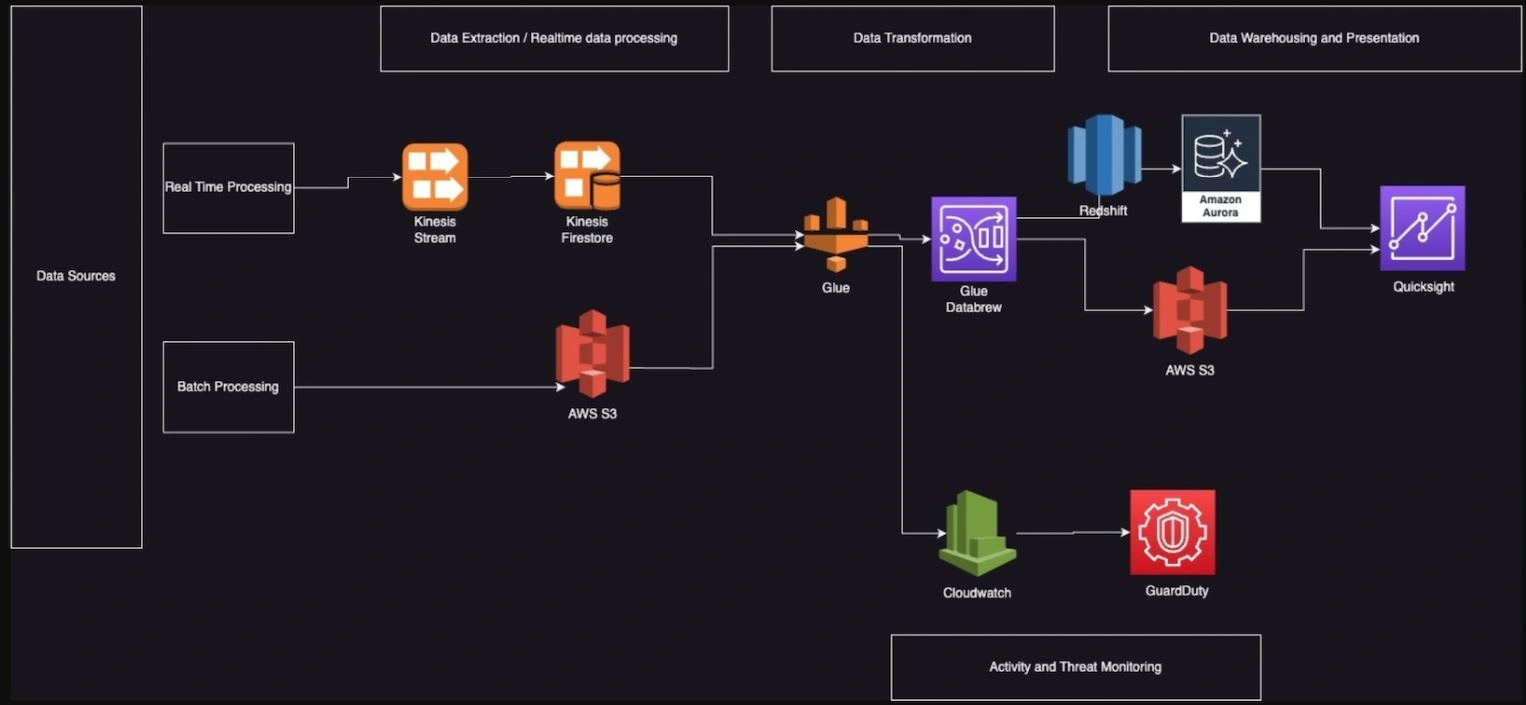
Data Ingestion:
I utilized AWS Glue for data extraction from various sources, such as MySQL databases, S3 buckets, and API endpoints. AWS Glue allowed us to automate the discovery, cataloging, and transformation of the data, ensuring a seamless and scalable ingestion process.
Real-time Streaming:
To achieve real-time processing, I leveraged AWS Kinesis Data Streams. The streaming service enabled us to capture and process data from web logs and customer interactions in near real-time. I implemented Kinesis Data Analytics for data enrichment and applied business rules for immediate insights.
Data Storage:
For efficient and scalable storage, I chose Amazon S3 as the data lake. It provided cost-effective, durable, and highly available storage for both structured and unstructured data. Additionally, I utilized AWS Glue Data Catalog to maintain metadata and facilitate data discovery.
Data Processing:
To transform and cleanse the data, I utilized AWS Glue for automated ETL (Extract, Transform, Load) processes. AWS Glue allowed us to create and manage serverless Apache Spark jobs, enabling efficient data processing and transformation.
Data Warehousing and Analytics:
For advanced analytics and reporting, I implemented Amazon Redshift as the data warehousing solution. Redshift provided high-performance querying capabilities, allowing business analysts to run complex SQL queries on large datasets and generate insights quickly.
Data Visualization:
To empower business users with intuitive dashboards and visualizations, I integrated Amazon QuickSight. QuickSight allowed us to create interactive and insightful visualizations, enabling stakeholders to explore data and gain valuable insights.
Like this project
Posted Jul 17, 2024
Implemented an end-to-end data engineering pipeline on AWS to streamline data processing, storage, and analysis to optimize supply chain of a merchandizer.