IOS Risk Data Foundry — Domain-Specific Financial Risk AI
Ugo Chukwu
Overview
This project is the second component of IntelligenceOS Risk — a domain-specific AI system I am building from scratch for financial risk and fraud detection. The Data Foundry is the data infrastructure layer: it takes raw inputs from three sources and produces a clean, versioned, training-ready dataset for fine-tuning a language model.
Deliverable: 276,772 instruction pairs in Alpaca format, published to HuggingFace Hub, versioned with SHA256 fingerprints, reproducible with a single command.
The Problem
Training a financial risk AI on generic data produces a generic model. The data infrastructure — how you engineer features, what text you ingest, how you generate synthetic edge cases — is what makes a domain-specific model meaningfully better than a general one.
Three specific challenges had to be solved:
Class imbalance. The real fraud dataset is 99.83% legitimate transactions. A model trained on this as-is learns to predict "legitimate" always and scores 99.83% accuracy — useless for fraud detection.
Domain language. Regulatory risk language (AML, BSA, SAR filings, 10-K risk sections) is not in any standard training corpus. A model that can't read a regulatory filing is not enterprise-grade.
Reasoning, not just classification. Binary fraud labels teach a model to classify. Natural language risk explanations teach it to reason — to articulate why a transaction is suspicious in the language a risk analyst would use.
What I Built
Feature Engineering Pipeline (
foundry/features/tabular_features.py)11 fraud-signal features engineered from raw transaction data, each encoding specific domain knowledge about how fraud behaves:
Velocity features (transaction counts per 1h and 24h windows) — catches card testing
Amount z-score, round-number flag, micro-transaction flag, large-transaction flag
Time features: hour of day, off-hours flag (11pm–6am), day of week proxy
Result: avg_precision improved from 0.8510 → 0.8623 (+0.0114). Recall improved by +0.051 — the model detects significantly more actual fraud.
SEC EDGAR Ingestion Pipeline (
foundry/sources/sec_edgar.py)Fetches 10-K risk filings from the public SEC EDGAR full-text search API across five risk query categories (fraud, AML, credit default, cybersecurity, operational risk). Downloads, HTML-strips, and chunks into 512-word overlapping windows formatted as instruction pairs.
Synthetic Fraud Scenario Factory
(
foundry/sources/synthetic_generator.py)Four fraud type generators producing realistic transactions with natural-language risk explanations:
Card testing: micro-transaction velocity bursts
Account takeover: large off-hours purchases
Money mule: round-number structuring below BSA reporting threshold
Bust-out fraud: sudden high-velocity large purchases
Each record includes a
risk_explanation field — the LLM's training target for learning to reason about fraud, not just classify it.Pipeline Orchestration and Export
A fully orchestrated pipeline (
foundry/pipeline.py) processes all three sources, merges and deduplicates (276,772 final pairs after removing 18,035 duplicates), shuffles, and exports to HuggingFace Hub as a versioned Parquet dataset.Dataset versioned as
foundry-v1.0 with SHA256 hashes in dataset_manifest.json for full reproducibility.Results
MetricBase FeaturesEngineered FeaturesDeltaavg_precision0.85100.8623+0.0114f10.84150.8542+0.0126recall0.78570.8367+0.0510
276,772 instruction pairs published to HuggingFace
6 automated tests covering the full pipeline
Full reproducibility via
foundry-v1.0 git tag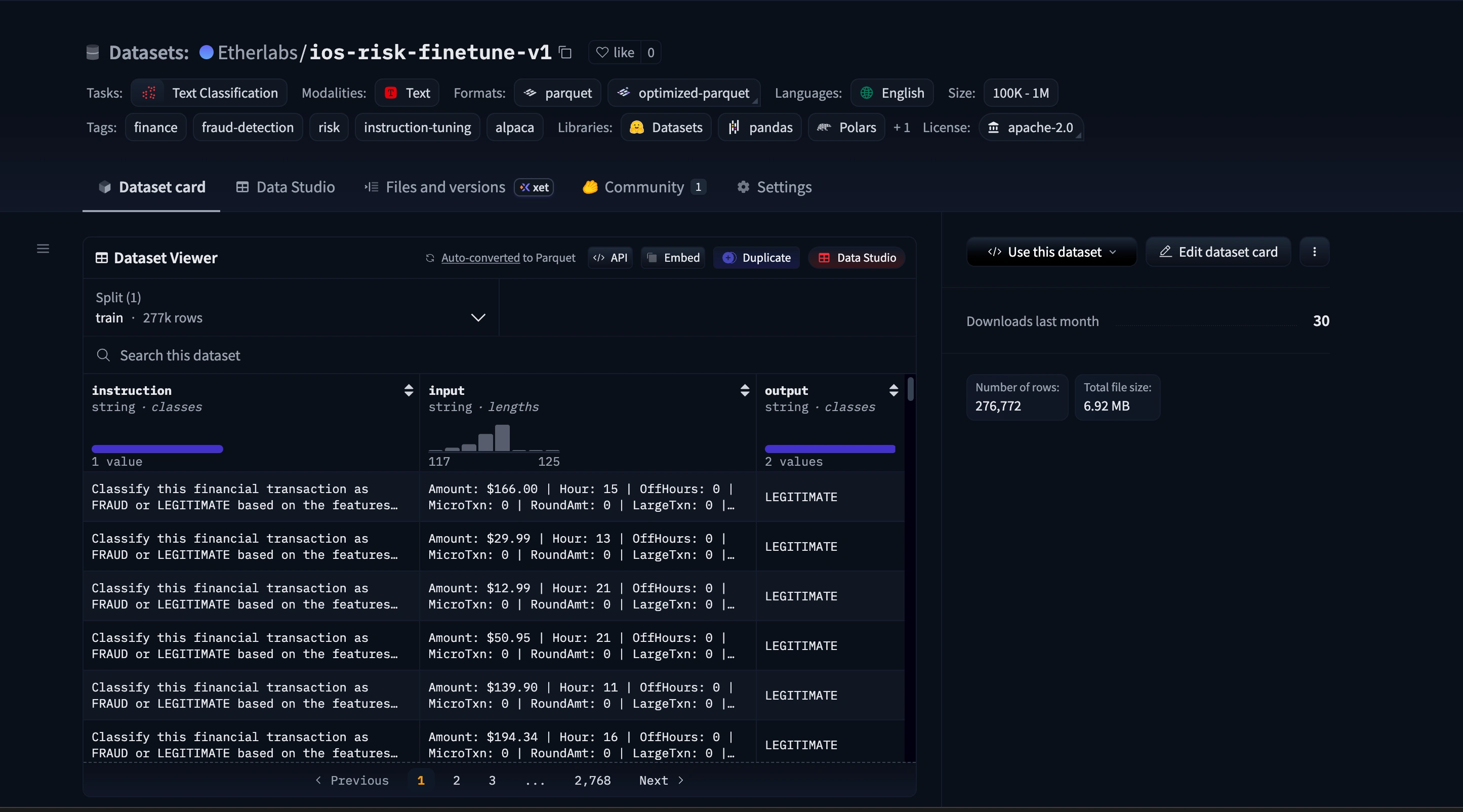
huuging face data
Technologies
Python · Pandas · NumPy · XGBoost · scikit-learn · HuggingFace Datasets · DVC · SEC EDGAR API · BeautifulSoup · PyTest · PyYAML
Links
Like this project
Posted Apr 12, 2026
A complete data engineering pipeline: feature engineering, regulatory text ingestion, synthetic fraud generation, and LLM fine-tuning dataset export.
Likes
1
Views
7
Timeline
Mar 29, 2026 - Apr 3, 2026