ML Evaluation Infrastructure for Fraud Detection
Ugo Chukwu

IOS Risk Eval Harness
ML Evaluation Infrastructure for Fraud Detection
Domain: Fintech / Risk Intelligence
Stack: Python, scikit-learn, XGBoost, imbalanced-learn, Pandas, NumPy
Duration: 7 days
Result: 21% improvement in fraud detection performance across three model architectures
The Problem
Credit card fraud detection sounds simple until you look at the data.
In a real-world dataset of 284,807 transactions, only 492 are fraud. That is 0.17%. A model that predicts "not fraud" for every single transaction would be correct 99.83% of the time — and completely useless.
This is the class imbalance problem, and it breaks every standard machine learning metric. Accuracy tells you nothing. You need precision, recall, F1, average precision, and threshold analysis to understand whether your model is actually working.
Most fraud detection projects jump straight to building models. This project started differently: build the measurement infrastructure first.
The Approach
Phase 1 — Build the Evaluation Harness
Before training a single model, I built
metrics.py — a reusable evaluation module with three functions:compute_core_metrics(y_true, y_pred, y_prob)
compute_core_metrics(y_true, y_pred, y_prob)Calculates every relevant metric from the confusion matrix up:
Precision, Recall, F1, and FPR from raw TP/TN/FP/FN counts
ROC AUC and Average Precision from probability scores
Zero-division guards throughout for production safety
evaluate_threshold_range(y_true, y_prob)
evaluate_threshold_range(y_true, y_prob)Sweeps thresholds from 0.0 to 1.0 in 0.05 steps and returns a full DataFrame showing how precision and recall trade off at every cut point. This is how you make an informed threshold decision instead of defaulting to 0.5.
find_optimal_threshold(y_true, y_prob, metric='f1')
find_optimal_threshold(y_true, y_prob, metric='f1')Automatically selects the threshold that maximises a given metric. It is parameterised, so it can optimise for F1, recall, or any other metric in the output dictionary.
Why build this first: Every model trained in this project, and every model trained in future projects, runs through the same evaluation functions. Results are comparable by design.
Phase 2 — Data Pipeline
Built
data_loader.py with a single function, load_and_prepare_data(), that handles:Dropping the
Time column (a recording artifact, not a transaction property)StandardScaler on the
Amount column to match the scale of PCA-transformed features V1–V28Stratified train/test split to preserve the 0.17% fraud ratio in both sets
Returning clean NumPy arrays ready for any scikit-learn compatible model
Critical detail: scaling happens after splitting. Fitting the scaler on the full dataset before splitting would leak test set information into the training process.
Phase 3 — Three Models, Increasing Sophistication
Model 1 — Logistic Regression (Baseline)
A simple linear model with
class_weight='balanced'. This establishes the performance floor. Every subsequent model must beat it.Model 2 — SMOTE + Random Forest
SMOTE (Synthetic Minority Oversampling Technique) generates synthetic fraud examples by interpolating between real fraud cases. This balances the training set from 394 fraud vs 227,451 legitimate transactions to 227,451 vs 227,451. A Random Forest was then trained on this balanced dataset with 100 trees and
max_depth=10.Model 3 — XGBoost
A sequential boosting model where each tree corrects the errors of the previous one. It uses
scale_pos_weight=577 (the legit-to-fraud ratio) instead of SMOTE, handling imbalance natively. Configuration: 200 trees, max_depth=6, learning_rate=0.1.The Results
What These Numbers Mean in Practice
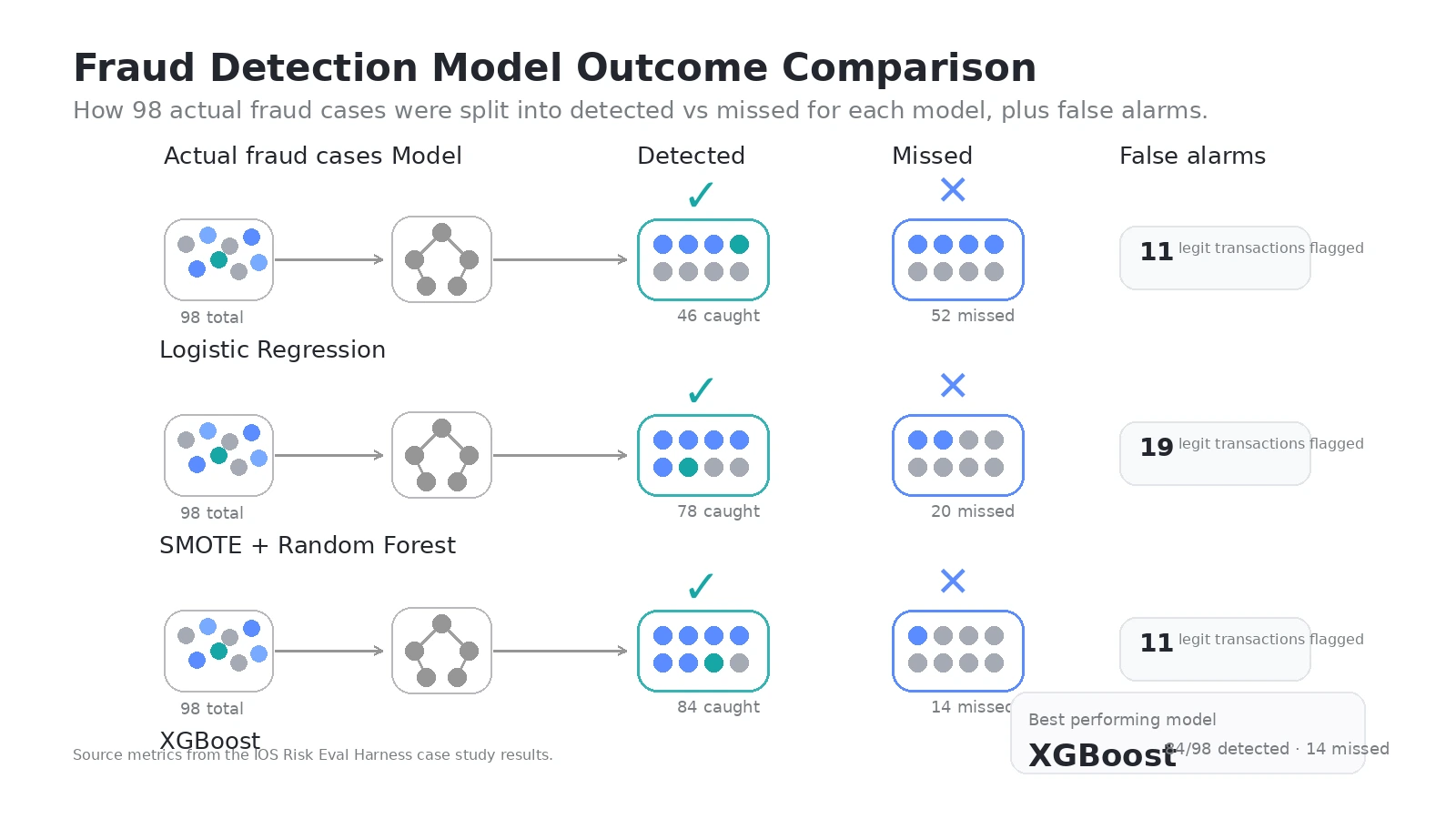
Across 56,962 test transactions, including 98 actual fraud cases:
Metric Logistic Regression Random Forest XGBoost Fraud caught 46/98 78/98 84/98 Fraud missed 52 20 14 False alarms 11 19 11 Avg Precision 0.716 0.829 0.869
XGBoost catches 84 out of 98 fraud cases while raising only 11 false alarms. That is 85.7% of all fraud detected, with a false positive rate of 0.019% — less than 2 in every 10,000 legitimate transactions flagged incorrectly.
The baseline Logistic Regression missed 52 fraud cases. XGBoost missed 14. That is 38 additional fraud cases caught — each one representing real financial loss prevented.
Key Engineering Decisions
Evaluation-first architecture
The evaluation harness was built before any model. This is the correct order: you cannot improve what you cannot measure, and you cannot trust improvement claims without consistent measurement.
Threshold as a business decision
The optimal threshold varies by model (
1.00 for Logistic Regression, 0.85 for Random Forest, 0.35 for XGBoost) and by business priority.A bank prioritising fraud prevention optimises for recall
A bank prioritising customer experience optimises for precision
The
find_optimal_threshold() function supports both by parameterising the target metric.Reproducibility by design
Every random operation uses
random_state=42. The stratified split preserves class ratios. The same data pipeline runs identically every time. Results are reproducible without notebooks or manual steps.Production-safe code patterns
Zero-division guards on every metric calculation
Python-native float and int casting before logging to avoid NumPy serialisation bugs
Modular functions with explicit type signatures
What This Enables
This evaluation harness is domain-agnostic. The same
metrics.py and data_loader.py pattern applies to:Insurance claim fraud
Anti-money laundering transaction monitoring
Credit underwriting risk scoring
Any imbalanced binary classification problem in fintech
The infrastructure built here is the measurement layer that every subsequent model, agent, or system gets evaluated against.
Services Available
ML Evaluation Framework Design — build measurement infrastructure before models
Fraud Detection System Development — end-to-end pipeline from raw data to evaluated model
Imbalanced Classification — SMOTE, threshold tuning, cost-sensitive evaluation
Model Comparison & Selection — systematic benchmarking across model families
Production-Ready ML Code — clean, documented, reproducible Python
Built as Project 01 of IntelligenceOS — a 12-project AI platform build across 12 months.
Like this project
Posted Mar 25, 2026
Developed ML evaluation infrastructure for improved fraud detection in fintech, boosting model performance by 21%.
Likes
0
Views
7
Timeline
Mar 15, 2026 - Mar 22, 2026