RefereeIQ: Conversational AI for Rugby Referees
Justin Hale

Overview
I designed and built RefereeIQ, a conversational assistant that helps rugby referees reason through the Laws of the Game using natural dialogue. Instead of paging through PDFs, referees ask questions and get grounded answers with relevant clarifications and links, delivered by “Sofia,” an AI referee coach.
Why it matters: This project explores how to design reasoning‑centric UX around LLMs — blending open‑ended conversation with grounding, citations, and fallbacks to earn trust in decision‑heavy contexts.
Problem & Users
Rugby referees contend with hundreds of laws, frequent clarifications, and nuanced edge cases. Guidance is often fragmented (forums, mentors, PDFs), making it hard to develop consistent judgment quickly.
Design challenge: Build a conversational experience that:
Feels like a mentor, not a generic chatbot
Handles multi‑turn reasoning without losing context
Shows relevant citations/clarifications to build trust and teach judgment
My Role
I led the project end‑to‑end — product thinking, UX, and implementation:
Conversational flow design and UI (Flutter, chat‑first patterns)
Backend on Cloud Functions with the OpenAI API
Firestore for state/config and scheduled content
Lightweight retrieval pipeline for official World Rugby Law Clarifications
Field testing with referees and coaches; iteration on prompts, tone, and safety
Truth in Delivery (What’s Real vs. Exploratory)
Implemented & live
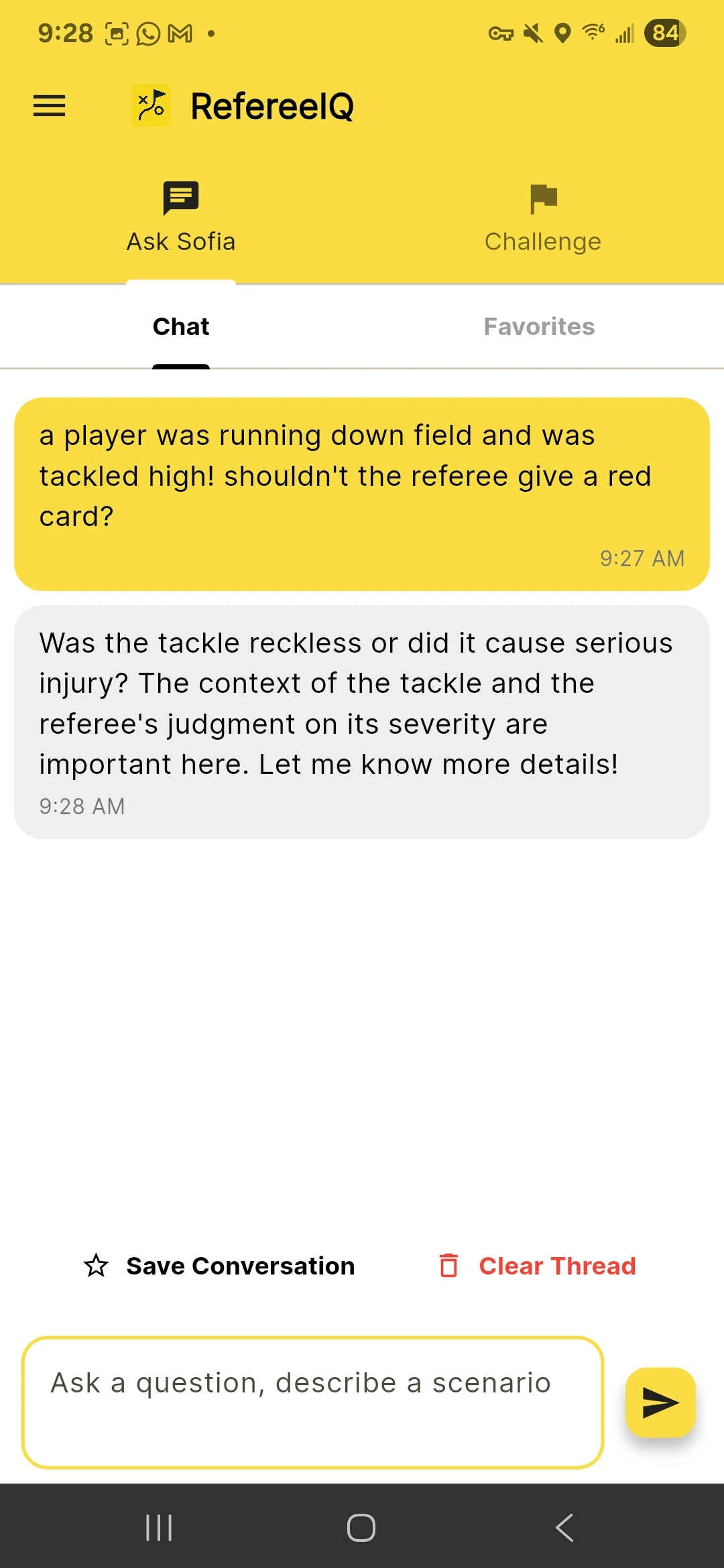
Chat → Cloud Function → OpenAI round‑trip with a focused Sofia system prompt and recent‑turn context.
Moderation pass over recent user text prior to model calls.
Grounding via targeted retrieval of World Rugby Law Clarifications: the backend scrapes the official clarifications index and can detect/fetch specific clarification pages. When useful (e.g., user requests a summary or the model signals uncertainty), the server parses sections (title + headings) and injects excerpts/URLs into the context for Sofia to cite.
Configurable AI behavior: default model/temperature and Sofia’s system prompt are centralized and can be overridden via Firestore for live tuning without redeploys.
Daily Challenge generator: a scheduled task produces 5 law questions (5 points each) with strict constraints (official law wording, one correct answer), stored in Firestore for in‑app use.
Flutter chat UI with markdown rendering and in‑app link launching.
Exploratory / future‑facing
A generalized document ingestion & vector search pipeline (classic RAG) is not yet implemented. The system performs targeted retrieval for official clarifications (domain grounding with citations) — but it is not a full vector store or multi‑corpus retriever.
The Sources surface is currently a static representation for UX demonstration.
System Architecture (Simplified)
App (Flutter)
Chat‑first UI (messages, markdown, link handling)
Daily Challenge and History tabs
Push notifications scaffolded for challenge drops
Backend (Cloud Function + Services)
chat handler:
moderation → 2) build Sofia system prompt → 3) detect when a law clarification would help → 4) fetch & parse official clarification page(s) → 5) assemble messages → 6) OpenAI chat completion → 7) return grounded answer with links
Configuration: default model/temperature in code; Firestore overrides for runtime tuning
Scheduled content: daily challenge task writes official‑aligned MCQs to Firestore
Conversation Design & Reasoning UX
Tone & trust
System prompt frames Sofia as a coach: patient, law‑accurate, explicit when uncertain.
Citations as trust cues: answers include links to official clarifications; Sofia can pull short excerpts (title + sections) on request.
Fallbacks & uncertainty
If unsure, the backend pivots to clarification lookup and says, for example: “Let’s check the latest clarification on this topic,” then shows a concise excerpt and link. This keeps the conversation moving without hallucinating a law.
Multi‑turn coherence
Recent context (user + Sofia turns) is preserved and sent server‑side; the system prompt consistently enforces terminology and citation standards aligned with official law language.
Safety, Cost & Performance Considerations
Safety: moderation pass on recent user text prior to model calls; guardrails enforced server‑side.
Cost control:
Compact, reusable system prompt
Temperature tuned per task (lower for Challenges; slightly higher for conversational coaching)
Bounded max tokens for concise, source‑linked answers
Latency: retrieval triggers selectively for clarifications to avoid unnecessary network and parsing overhead.
Outcomes
Cross‑platform release: shipped to Android with a working chat experience and daily challenges.
Early usage: referees and coaches used Sofia for scenario‑based learning.
Feedback themes:
“Seeing the exact clarification link is faster than hunting PDFs.”
“When it checks the clarification instead of guessing, I trust it more.”
What I’d Improve Next
Full RAG pipeline: ingest laws + clarifications + competition regulations into an embeddings‑backed store with section‑level citations to improve recall and coverage.
Scoped sources: user‑selectable corpora by competition/region to reduce ambiguity and increase relevance.
Evaluation harness: prompt + expected source snippets as a regression suite to protect quality across prompt/model changes.
Telemetry: structured signals on when/why retrieval fires, uncertainty rates, and what gets cited — to guide corpus and UX improvements.
Why This Maps to AI/Data Tooling
Reasoning‑centric UX: the assistant shows how it reasons (citations, fallbacks), not just what it answers — critical for analysis, forecasting, and data prep agents.
Grounding over gloss: verifiable references preferred over confident but vague answers — a pattern that carries to data science workflows (datasets, transforms, assumptions).
Live configurability: model and temperature can be tuned from Firestore without redeploys — enabling rapid iteration with stakeholders.
Generalizable pattern: architecture extends to domain copilots (legal, policy, ops SOPs) where guidance must anchor to authoritative sources.
Implementation Pointers (for technical reviewers)
Retrieval: clarification index & page parsing (server) with excerpt injection into model context
Config & prompts: centralized defaults with Firestore overrides
Scheduled content: daily MCQs with strict rules (official wording; one correct answer)
Client: Flutter chat UI with markdown and link handling; challenge UI with simple scoring
Welcome Screen
Question Follow-Up
Ask Sofia
Challenge History
LLM Generated Questions

Like this project
Posted Feb 23, 2026
AI coach helping rugby referees learn Laws of the Game through conversational chat. Grounded answers with citations.