Created a Popular Spark Library for ETL
Murtada Ahmed
I discovered a need in the data science and engineering community that I addressed by packaging repetitive tasks in a Spark library that I later published into PyPI.
Interestingly I was right! The demand was huge for this package and it has much more downloads than I imagined till today.
This library helped my data team by reducing the time and complexity to code such ETL tasks by 80%.
Below you can see a snapshot of the daily downloads of my library.
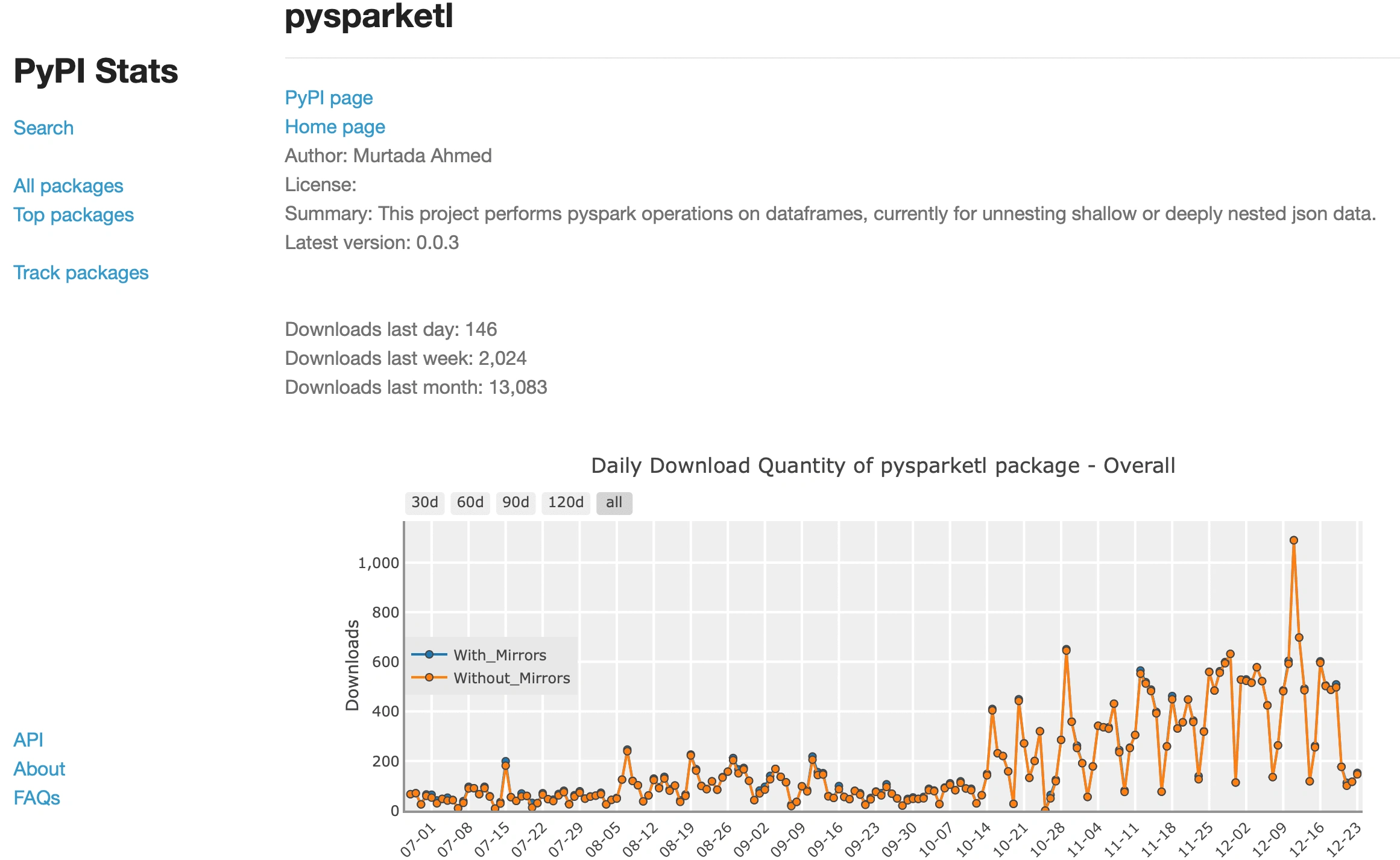
Daily Downloads of my ETL library
The package can be used in Databricks or any Spark environment that supports PySpark (Python).
I documented the library with clear instructions added to make it simple.
Check the reference here.
It's main uses are dealing with complex data structures e.g. JSON formats as is with data arriving from streaming and real-time events that need to be simplified into tabular-models for further analysis or ML tasks...etc.
The methodology is to analyse the structure of the incoming complex format and automatically make smart decisions to reach the leafs of each hierarchy.
Looking for a custom Python library to streamline your workflows? Let’s collaborate to create tools that simplify your processes.
Like this project
Posted Jan 11, 2025
I created a Spark ETL package that saves a lot of time, the downloads for this package reached up to 1000+ per day which reflects its value for the community.
Likes
0
Views
10