A Guide to Snowpark in Snowflake[+4 Tips to Get the Most Value …
Amit Phaujdar
Traditionally, when working with Spark workloads, you would have to run separate processing clusters for different languages. Capacity management and resource sizing are also a hassle.
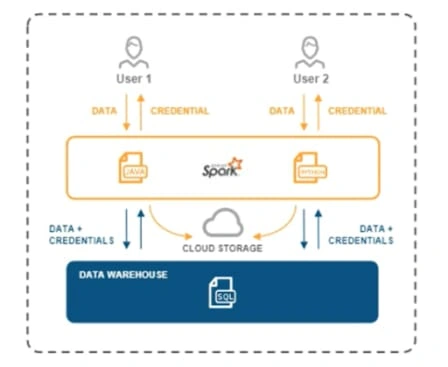
Snowflake addressed these problems by providing native support for different languages. With consistent security, governance policies, and simplified capacity management, Snowflake pulls ahead as a great alternative to Spark.

In this article, we’ll go over how Snowpark’s libraries and runtimes in Snowflake simplify the workload of a data practitioner.
What is Snowpark?
Snowpark provides a set of libraries and runtimes in Snowflake to securely deploy and process non-SQL code, including Python, Java, and Scala.
On the client side, Snowpark consists of libraries including the DataFrame API and native Snowpark machine learning (ML) APIs in preview for model development and deployment. Specifically, the Snowpark ML Modeling API (public preview) scales out feature engineering and simplifies model training while the Snowpark ML Operations API includes the Snowpark Model Registry (private preview) to effortlessly deploy registered models for inference.
On the server side, runtimes include Python, Java, and Scala in the warehouse model or Snowpark Container Services (private preview). In the warehouse model, developers can leverage user-defined functions (UDFs) and stored procedures (sprocs) to bring in and run custom logic.
Snowpark Container Services are available for workloads that require the use of GPUs, custom runtimes/libraries, or the hosting of long-running full-stack applications.

Here are a few benefits you enjoy when using Snowpark for your data transformations:
Snowpark provides libraries for interacting with data in Snowflake, specifically designed for different programming languages, without compromising performance or functionality.
You have support for authoring Snowpark code through VS Code, Jupyter, or IntelliJ.
With Snowpark, you don’t need a separate cluster outside of Snowflake for computations. Snowflake will manage all scale and compute operations.
Snowpark for Python Architecture
Snowpark for Python architecture consists of DataFrames, UDFs, and stored procedures that can be developed from any client IDE or notebook. Their execution can all be pushed down to Snowflake to benefit from the performance, elasticity, and governance of the Snowflake processing engine.

Snowpark DataFrame
Snowpark brings deeply integrated, DataFrame-style programming to the languages that data engineers prefer to use. Data engineers can build queries in Snowpark using DataFrame-style programming in Python, using their IDE or development tool of choice.
Behind the scenes, all DataFrame operations are transparently converted into SQL queries that are pushed down to the Snowflake scalable processing engine.
Because DataFrames use first-class language constructs, engineers also benefit from support for type checking, IntelliSense, and error reporting in their development environment.
Snowpark User Defined Functions (UDFs)
Custom logic written in Python runs directly in Snowflake using UDFs. Functions can stand alone or be called as part of a DataFrame operation to process the data.
Snowpark takes care of serializing the custom code into Python byte code and pushes down all of the logic to Snowflake, so it runs next to the data.
To host the code, Snowpark has a secure, sandboxed Python runtime built right into the Snowflake engine.
Python UDFs scale-out processing is associated with the underlying Python code, which occurs in parallel across all threads and nodes, and comprises the virtual warehouse on which the function is executing.
Stored Procedures
Snowpark stored procedures help data engineers operationalize their Python code and run, orchestrate, and schedule their pipelines. A stored procedure is created once and can be executed many times with a simple CALL statement in your orchestration or automation tools.
Snowflake supports stored procedures in SQL, Python, Java, Javascript, and Scala so data engineers can easily create polyglot pipelines.
Additional Snowpark Benefits
Snowflake + Anaconda
You can easily access thousands of popular Python open-source packages through the Anaconda integration. Here’s how you can use Anaconda-powered third-party libraries to build Python workflows:
Local Development: Just point your local Anaconda installation to the Snowflake channel. This’ll ensure that you’re using the same packages and versions present on the Snowflake server side.
Package Management: If your Python function depends on third-party libraries, you can just specify the Python packages it needs in a UDF declaration. Snowflake will resolve the dependencies on the server side and install the relevant packages into the Python UDF execution environment using the integrated Conda package manager. So, you don’t have to spend any time resolving dependencies between different packages in the future.
Unstructured Data Processing
Snowpark can process unstructured files in Java (generally available), Python (public preview), and Scala (public preview) natively in Snowflake. Users can leverage Python UDFs, UDTFs, and Stored Procedures to securely and dynamically read, process, and drive insights from unstructured files (like images, video, audio, or custom formats) from internal/external stages or on-premises storage.
Reduced Transfer
Snowpark operations are lazily executed on the server. This means you can use the library to delay running data transformation until as late in the pipeline as you want while batching operations. This’ll reduce the amount of data transferred between your client and the Snowflake database and improve performance.
How Does Snowpark Fare Against Its Competitors?
With Snowpark, Snowflake has jumped into competition with transformation technologies like Hadoop and Spark, to name a few. Here are a few advantages that allow it to stand out in the market:
Robust Security: In Snowflake, security is built-in, not bolted on. From end-to-end encryption for data at rest and in transit and dynamic data masking, Snowflake provides a set of advanced security features embedded within the platform and applicable across different compute and storage options.
Governance Friendly: Since the transformation happens in Snowflake, you can easily enforce governance policies from the platform. You don’t have to worry about unwanted network access or redundancies.
Support for Multiple Use Cases: Snowpark provides native support for Python, Java, and Scala on a single platform. Snowpark also supports structured, semi-structured, and unstructured data.
Zero Cluster Maintenance: You don’t need any additional infrastructure or service other than Snowflake. This means you can enjoy unlimited flexibility and scalability without worrying about maintenance.
More Collaboration: Data Scientists and ETL developers can now work on the same platform to bring predictability and homogeneity to the process. This’ll simplify your DevOps as well.
PySpark vs Snowpark: Key Differences
PySpark is a distributed processing engine that lets you process data efficiently. With PySpark you can write code that scales on a cluster, but it’s still difficult to manage. Here’s how Snowpark sizes up against PySpark:
Collecting Data: Priming your data for analysis is the most pivotal bit of any data analysis. Since PySpark is a distributed compute engine without a long-term storage medium, you’ll have to collect data from different sources. You’ll also need to store the result of your analysis in a target database or deploy your models with specific tools. You don’t face that problem with Snowpark since Snowflake serves as the single source of truth for all of your data.
Feature Engineering: PySpark provides various functions for feature engineering, including methods to transform and encode features. The Snowpark ML Modeling API (public preview) supports common pre-processing and feature engineering tasks directly on data in Snowflake using already familiar sklearn-style APIs and benefits from improved performance and Snowflake’s parallelization for scaling to large datasets with distributed, multi-node execution. Feature engineering in Snowpark reduces costs and simplifies data preparation through centralized access (everything’s done in Snowflake) unlike PySpark. This also keeps your data controlled and consistent for training and validation.
Exploring Data: To explore data with PySpark, you need to first collect it, and then use the PySpark DataFrame API functions of your choice. In Snowpark, you can use ANSI SQL to explore data inside Snowflake. For data lakes/repositories outside Snowflake, you can use materialized views or external tables to process and obtain results in Snowflake.
Infrastructure: All PySpark clusters have unique configurations, making it harder to optimize. Plus, provisioning and scaling them for concurrency is a tedious process. Another limitation of Spark is that new clusters need to be created for other languages, like Python. Snowpark runs on Snowflake virtual warehouses, which allows it to scale rapidly without needing complex maintenance. In Snowpark, the warehouses can start and resume in a few seconds, giving it an edge over PySpark clusters.
How are companies using Snowpark?
EDF
EDF, a leading energy supplier in the United Kingdom uses data science in multiple ways to serve its customers like:
Identifying financially vulnerable users and offering the appropriate support.
Improving energy efficiency across wind, solar, and nuclear power to cut out carbon emissions.
They went with a DIY approach and prepared an in-house platform, CAZ (Customer Analytics Zone) for developing and deploying machine learning (ML) models.
But an in-house platform brought a host of challenges with it.
EDF decided to switch up its approach in 2022 when a single ML model deployment set them back by a couple of months.
Recognizing that they needed a new customer data platform, EDF turned to the Snowflake Data Cloud to provide a central source of easily accessible data for its new Intelligent Customer Engine (ICE).
EDF now uses Snowflake and the Snowpark development framework to let its data scientists use Python and bring ML models into production on AWS SageMaker.
Rebecca Vickery, the Data Science Lead at EDF said, “With the Snowpark feature, the benefits of being able to run data science tasks, such as feature engineering, directly where the data sits, is massive. It’s made our work a lot more efficient and a lot more enjoyable.”
Armed with Snowpark, EDF was able to achieve astonishing results:
The migration has allowed EDF to consolidate multiple environments with different vendors. This has greatly simplified its IT landscape and reduced costs.
With Snowflake, EDF can deploy machine learning models within days instead of months. This has allowed the projected number of data products they can put out to jump 4x!
IQVIA
IQVIA integrates data and analytics with AI/ML strategies to improve human health and treatment.
The problem that IQVIA was trying to solve was of aggregation and management of the massive amounts of data that clinical trials generate. To help organizations spend more time getting insights from data, they came up with CDAS (Clinical Data Analytics Suite.)
CDAS aggregates data for clinical R&D (Research and Development) across the clinical trial lifecycles as shown in the figure below:

Snowpark in Snowflake: IQVIA CDAS Structure
While building CDAS, the primary problem that IQVIA faced was the complexity that came with tackling large volumes of heterogeneous data coming from many different sources across the globe.
IQVIA used multiple services initially to model and process their complex data sets. Since this architecture was largely dependent on Spark for processing, it limited the number of workloads the platform could handle.
All the intelligent application workflows sitting on top of CDAS generated a lot of data that would need multiple levels of infrastructure for end-to-end support.
Enter Snowpark.
Snowpark allowed these developers to execute Python, Java, or Scala custom functions to build efficient pipelines, data applications, and ML workflows. Snowpark handles everything from development to execution for these intelligent applications in a serverless manner.
Dataiku
Lots of predictive model scoring and data preparation functions were carried out in Dataiku or other engines. Before Snowpark, they couldn’t express these in SQL.
This also needed a lot of data movement in and out of Snowflake, which was affecting the performance. With Snowpark, Dataiku eliminated the need to move data out of Snowflake.
Since their core engine is Java, Dataiku benefited from repackaging data preparation functions and pushing them down to execute them inside Snowflake.

Snowpark in Snowflake: Dataiku Case Study
Total Economic Impact of Snowpark on Data Engineering
With Snowpark at the helm, data teams don’t have to manually copy and move files anymore. With Snowflake’s multi-cluster compute, data engineers can easily conform multiple data sets from different sources simultaneously.
Here’s a list of Snowflake benefits that have improved data engineers’ productivity by 66% (13,000 hours saved annually):
Pruning unnecessary data.
Micro-partitioning of data.
Managing storage capacity.
Support for unstructured data, which meant data engineers no longer had to write code to turn unstructured data into structured data.
The net benefit that you can enjoy by using Snowpark for your data needs is ~$11 million over 3 years.

Snowpark in Snowflake: Cash Flow Chart to demonstrate the benefit of buying Snowflake
Snowpark Best Practices for Optimal Performance
Use Vectorized UDFs for ML Scoring and Feature Transformations: You can use the Python UDF Batch API for third-party Python packages since it operates more efficiently on batches of rows. Vectorized UDFs come in handy for row-wise feature transformations and ML batch inferences.
Caching Data as Required: Due to lazy command execution on Snowpark, a transformation on a DataFrame might be used multiple times. In this scenario, you can cache this DataFrame. Snowpark will create a temporary table behind the scenes and load the transformed data into that table. So, the next time the base DataFrame is used, you can use the table instead of recalculating the transformations. However, you shouldn’t use caching if a query isn’t run multiple times.
Minimizing Fields: If the fields are not limited while converting the source code, all the fields will get copied from the source table. For larger tables, this could mean a lot of unnecessary data movement and reloading.
Keep a Finger on the Generated SQL: Since Snowpark creates an SQL query behind the scenes, it’s important to keep SQL best practices in mind like:
Use Snowpark-optimized Warehouses for Memory-Intensive Workloads: With Snowpark-optimized warehouses, you can run end-to-end ML pipelines in Snowflake in a fully-managed manner without using additional systems or moving data across governance boundaries. Compared to standard warehouses, the compute nodes of Snowpark-optimized warehouses have 16x the memory and 10x the local cache. You can use it when you run into a “100357 (P0000): UDF available memory exhausted” error during development. Avoid mixing other workloads with workloads that need Snowpark-optimized warehouses. If you need to mix them, call the session.use_warehouse() method to switch back to standard warehouses.
Accelerate Development to Production Flow with Anaconda Integration: Snowflake recommends using the Snowflake Anaconda channel for local development to ensure compatibility between client and server-side operations. You can build your code using the latest stable versions of third-party packages without specifying dependencies, thanks to the Conda Package Manager. If the desired package is a pure Python package, you can unblock yourself and bring it in stages.
Note: You might not enjoy the optimal performance when running Snowpark on Jupyter notebooks if your data volumes are low, and no one else consumes the functions out of Jupyter’s user base. Run ML or data engineering code against TBs of data to get the most out of Snowpark.
Key Takeaways
Snowpark in Snowflake for Python is a three-legged stool. Its major components are:
Snowpark API: Lets you write language-embedded queries to build powerful data pipelines
User-Defined Functions: You can bring your code to Snowflake with functions.
Stored Procedures: Let you operationalize and host that procedural code in Snowflake.
Snowpark has emerged as a handy alternative to PySpark saving up to 13,000 hours every year for data practitioners! It allows data practitioners to focus on lever-moving tasks while automating everything else.
All within Snowflake.
Occam’s Razor states that you should find the simplest solution that works.
When designing your ETL/ELT pipelines, the more tools you use in your workflow, the higher the chance of everything breaking. So, if your data is in Snowflake, using Snowpark will introduce greater simplicity to your architecture.
If you’re looking for an ETL tool that seamlessly replicates data from all your data sources to Snowflake, you can try out Hevo Data.
Hevo Data allows you to replicate data in near real-time from 150+ sources to the destination of your choice including Snowflake, BigQuery, Redshift, Databricks, and Firebolt, without writing a single line of code. We’d suggest you use this data replication tool for real-time demands like tracking the sales funnel or monitoring your email campaigns. This’ll free up your engineering bandwidth, allowing you to focus on more productive tasks.
For rare times things go wrong, Hevo Data ensures zero data loss. To find the root cause of an issue, Hevo Data also lets you monitor your workflow so that you can address the issue before it derails the entire workflow. Add 24*7 customer support to the list, and you get a reliable tool that puts you at the wheel with greater visibility.
References used throughout the article:
Content Marketing Manager, Hevo Data
Amit is a Content Marketing Manager at Hevo Data. He enjoys writing about SaaS products and modern data platforms, having authored over 200 articles on these subjects.
Like this project
Posted Feb 5, 2024
Snowpark in Snowflake for Python is a three-legged stool. Its major components are:
Likes
0
Views
45