Have You Got What It Takes to Be a Good Data Engineer? [+Resour…
Amit Phaujdar

Data Engineering Skills(Data Engineers!)
If there’s something strange
In your Data Pipeline
Who you gonna call?
(Data Engineers!)
If your data quality’s poor
And you don’t got time
Who you gonna call?
(Data Engineers!)
- A poorly modified bit from The Original Ghostbusters Theme Song
You’ve heard of them. You’ve built fancy images of them in your head, and you can’t wait to become one and bring home the big bucks.
The elusive “data engineer.”
Some of you joined the bee-line because it allows you to “swim in the green.” Maybe it just sounds so much cooler than “data scientist.” So, here’s a guide to what it takes to make it as a data engineer today.
A data engineer allows you to bridge the gap between your data producers and data consumers. They focus on drawing up the data infrastructure that holds your enterprise’s analytics capacities together. If this sounded a tad fancy, here’s Monica Rogatin’s “Hierarchy of Needs” pyramid to make this clearer:
The Data Science Hierarchy of Needs: Data Engineering Skills
A data engineer is the “hero” in the first three foundational rows of the pyramid:
Collect
Move/Store
Explore/Transform
The jobs of data scientists, data analysts, and machine learning engineers are all built on top of the foundation that a data engineer creates. So, a data engineer handles everything from data ingestion to operations and enrichment.
Now that you are somewhat familiar, let’s go deeper to understand what are the data engineering skills required to break into this space in an attempt to become a good data engineer.
What’s the Demand Like for a Data Engineer?
Amid widespread claims calling “Data Scientist” the “sexiest job of the 21st century”, data engineering saw a dramatic 40% YOY rise after the pandemic, while the growth of data science slowed down.
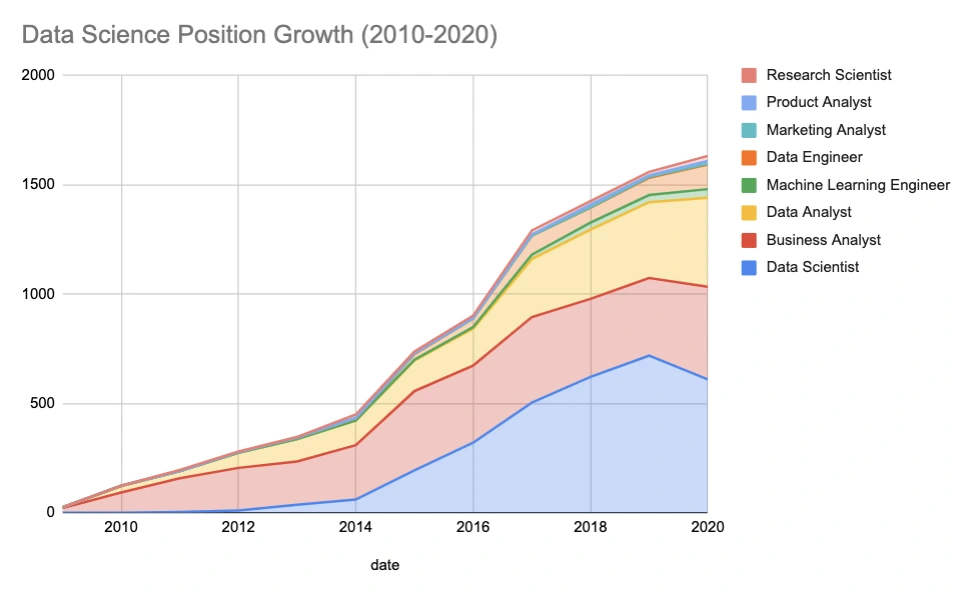
Growth in Data Positions –
So much for historical figures. But is this role future-proof, or will “another one bite the dust”?
This is a pretty straightforward question to answer.
The rapid evolution of the modern data stack has made it evident to companies that without proper data quality and data infrastructure in place, their “dreamy” data science projects will quickly fall apart. The cherry on top of this sundae bar is the fact that the supply of quality data engineers is extremely low at the moment, while the demand is monumental.
And what happens when the supply cannot match the demand?
The prices shoot up. Staggeringly.
“Data is the new currency/oil”– is probably the most overused statement over the last five years. But, if that is the case, the people with the skills to extract this “oil” have an incredible opportunity beckoning them.
On top of this, the restrictions and lockdowns post-COVID-19 have sped up the on-prem to cloud migration for various enterprises. This has led to massive spending on moving business operations and data to the cloud. Despite “cloud” and “big data” being buzzwords since 2015, they became much more tangible in 2020–21 when large-scale transformations took place, and job profiles for data engineers started flooding the market.
Open Positions for Data Engineers on LinkedIn
And that’s just in the USA.
So, at the moment, there’s a high demand for big data engineers and cloud data engineers to help enterprises move from on-prem to the cloud while developing a scalable data infrastructure.
How Easy is it for a Beginner to Break Into this Space?
The role of a data engineer can be broken down into three categories:
Database-Centric: In enterprises, where managing the flow of data is a full-time job, data engineers focus on analytics databases. Database-centric data engineers dabble in data warehouses across multiple databases. They are responsible for making table schemas.
Database-centric data engineers are primarily tasked with designing and building data warehouses. They also work on integrating data warehouse access tools (designed to facilitate interactions with data warehouses for business users) for the enterprise’s data warehouse. For instance, data mining tools can be used to automate the process of finding correlations and patterns in large amounts of data based on sophisticated statistical modeling techniques.
Pipeline-Centric: Mid-sized and larger companies are way more likely to use pipeline-centric data engineers. They work alongside data scientists to help make use of the data they collect. On top of carrying out ETL jobs on the data pipeline, data engineers also need to update the system by deleting/adding fields, repairing failures, or adjusting the schema to the changing needs of the business.
Generalist: A generalist data engineer usually works in small teams, executing end-to-end data collection. Generalist data engineers possess more skills than other types of data engineers and take responsibility for every step of the process. So, they handle everything that the database-centric and pipeline-centric data engineers take care of.
As a beginner, you only need to concern yourself with mastering the fundamentals. Once you’ve built a strong foundation, you can move on to understanding more complex softwares. But for now, we’ll stick to the basics.
Here’s what you would need as a beginner to dip your toes in the water:
Data Engineering Skills: Programming
This involves having a clear idea of the following programming languages:
Backend languages
Specialized languages for statistical computing
Query languages
Python, SQL, and R are some of the most popular languages for data engineering, according to the TIOBE index and the Popularity of Programming Languages Index. R is the pivotal software environment and programming language for statistical computing. So, it makes sense that statisticians and data miners have a soft spot for it.
TIOBE Index for September 2022
Python
Python is a core programming language that continues to be highly sought-after even in 2022. Data engineers can write reusable, maintainable, and complex functions like data ingestion in Python.
Python supports a vast array of modules and libraries like Pandas. With Pandas, you can read data into “Dataframes” from a bunch of formats like CSV, JSON, TSV, XML, LaTeX, etc. It also supports column-oriented formats like Apache Parquet. This allows you to optimize querying that data down the road with tools like Amazon Athena.
Python is versatile, efficient, and offers a robust basis for big data support.
Learning Python is fairly easy today with the flurry of resources available at your disposal. Here are a few resources you can go through to get a head start on mastering Python from scratch:
Courses
Books
Interactive Tools
Blogs
SQL
SQL is one of the primary tools used by data engineers to pull key performance metrics, model business logic, and create reusable data structures. You’ll be using SQL extensively for in-house ETL jobs. For instance, the COPY INTO SQL command can come in handy to load raw data into your destination. Similarly, common operations that you might run into while transforming your data are as follows:
GROUP BY, Aggregate functions, UNION, ORDER BY, etc.
Window functions
CTEs
Stored procedures, functions, and sub queries to name a few.
You can also use it to model end-user table(s). Usually, you can do this with fact and dimension tables (which requires in-depth knowledge of JOINS). This is a small example of where SQL comes in handy in the ETL process. You can dive deeper and find more examples on this.
Thus, having a solid foundation in SQL is crucial for putting your best foot forward as a data engineer. Here are a few resources to get you started:
Courses
Books
In addition to these two widely used programming languages, you must be conversant with the two key concepts of the data space if you want to succeed as a data engineer. These are well-known and understood by all data professionals, including data scientists and business analysts, making them ideal and indispensable concepts for anyone new to data engineering.
Data Warehouse Concepts
Data lakes and data warehouses are large, complex datasets that organizations use as central repositories for business intelligence. In business-driven information engineering, business analysts manage these datasets via computer clusters.
This network of computers comes in handy while solving problems. Having a clear understanding of the benefits, features, and shortcomings of the various data warehouses in the marketplace will allow you to choose a solution best suited for your needs. After deciding on a data warehouse, you can dive into other data engineering frameworks like Apache Kafka and Airflow to migrate your data from your sources to your data warehouse.
ETL
ETL stands for Extract, Transform, and Load. ETL tools are mainly used for data integration purposes, ingesting data from disparate sources and loading it into a central repository: your data lake or warehouse.
At the start of the data pipeline, data engineers are dealing with raw data from various disparate sources. They write code snippets, aka jobs, that run on a schedule, extracting all the data collected during a certain period. Next, data engineers execute another set of jobs that transforms the inconsistent data to meet the specific requirements of the format. Finally, the data gets loaded to a destination to be used for further analysis and business intelligence operations.
The advent of low-code platforms has largely absorbed the role of the traditional ETL tools today, but the increasing complexity of the data stack and the ushering in of new tools regularly means the ETL process is still a fundamental aspect of data engineering.
Keep in mind the following best practices when implementing ETL as well:
Setting fair processing times
Preventing errors
Ensuring transaction security
Using data-quality measurement jobs
Considering dependency on other systems
Hadoop Ecosystem
Data engineers leverage Apache Hadoop to analyze and store massive amounts of information. Hadoop is an open-source suite that supports data integration, making it pivotal for Big Data Analytics. It allows data engineers to leverage data from multiple sources and in different formats (unstructured and structured data). On top of this, you don’t have to clean or archive the data before loading it.
If you make it as a data engineer, you’re likely to be using Kafka with Hadoop for real-time data monitoring, processing, and reporting. Engineers dabbling with Hadoop are responsible for creating repositories for the storage of big data.
They formulate, differentiate, inspect, and maintain large-scale data processing systems, databases, and other similar architecture. Next, they need to install continuous pipelines to and from large pools of filtered information. This will then allow data scientists to extract the necessary information for their analyses.
Spark is another well-known big data framework that you can leverage to process and prepare big data sets.
Apache Spark in more demand than Kafka and Snowflake!? Recently asked this on LinkedIn. I thought Snowflake would be a lot higher, because it's so popular. Spark could be higher there also for the reason of the popularity of Databricks#dataengineer #bigdata #datascience pic.twitter.com/XiUH4wR7B3
Both of these data engineering frameworks rely on computer clusters to perform tasks on vast amounts of data, ranging from data analysis to data mining. Spark is still one of the top contenders among Data Engineers for running ETL jobs:
3/4 people use Spark mainly for ETL jobs.. To me that seemed crazy at first. Although when you look at how most data comes in as files it's logical. Too many data sources still can't offer a streamed output.#dataengineer #datascience #bigdata #apachespark #learndataengineering pic.twitter.com/2uIxiTYUnn
For more insights into the basics required to break into this role, you can refer to the Data Engineering Simplified article.
Holistically Speaking, What’s Up?
If you think you’ll nail the next data engineer interview you lay your eyes on, armed with just the basics…
Your training isn’t complete, young Padawan. Since you most likely won’t be working in isolation, you’ll need skills to meaningfully interact with others. Being technically proficient can only take you so far in your career, so you need “something” to have an edge over the competition.
That something is “soft skills,” as you might have guessed by now. Soft skills can be described as the ability to gain the knowledge, skills, and mindset to be an effective and productive member of the team.
Problem-Solving
As more and more companies join the quest for innovation, the need for data specialists that have exceptional problem-solving skills has skyrocketed. This skill allows data engineers to perform an objective analysis of business problems. It allows them to ask the right questions when collating requirements.
Here’s what Dustin Vannoy had to say about problem-solving as a core skill for a good data engineer:
Data engineers are not often handed detailed specs of what needs to be built so it’s key that they can understand the goals and find solutions. Understanding the problem and driving to solutions is expected from a data engineer while sitting back and asking how to implement the request is a burden to the team.
Here are some strategies you can keep in mind to sharpen your problem-solving skills:
When faced with a complex problem- don’t try to break through that brick wall. Do what creative thinkers do, give up. (cue crickets chirping)
Yep, you heard that right.
When problem solvers and creative thinkers are faced with a daunting problem, they understand that it doesn’t make sense in wasting energy on this complicated problem. Instead, they can fruitfully devote energy to simpler cases that will teach them how to tackle that complicated problem.
George Polya put it beautifully, “If you can’t solve a problem, then there is an easier problem you can solve: find it.”
So, find a simpler problem to solve, resolve that issue thoroughly and study it with laser focus. The insights you get from this will bring you closer to resolving the original problem.
As a data engineer, you must embrace accidental missteps on your problem-solving journey. A specific mistake is a great source of direction and insight since a mistake gives you something to think about- “This approach is wrong because ___.” By filling in the blank, you force yourself to identify what’s wrong with that approach. So, instead of stressing out over finding the right solution, that you don’t know at the moment, solve the problem- pretty badly. Next, look for problems and fix them to nudge you in the direction of the right answer.
Curiosity
Alexandra Levit said in her book, Humanity Works: Merging Technologies and People for the Workforce of the Future, “For someone to be successful 10 years down the road, they need to be resilient and be able to reinvent themselves in various learning environments.”
Curiosity is one of the key skills that’ll allow you to do just that. Although there’s no mystical formula for creativity, you can try out the following strategies to shake things up:
As a data engineer, you need to know something before you can ask “good” questions. This goes without saying that curiosity as one of the pivotal traits for success as a Data Engineer.
Who needs to use the data? What questions do they have? What is hard for them to do that I can make easier? Someone who asks these types of questions will make a bigger impact than a person who feels like they are just moving data from one system to another.
Since good questions serve as the fodder for curiosity, it can be slightly challenging to be curious about something if you can’t pose these questions. Since knowledge about a topic leads to curiosity for new knowledge, you need to know more. Read more to generate a positive feedback loop of learning. The deeper you dive into a topic, the more likely you are to have unanswered questions that foster curiosity.
Secondly, rephrase what you’re learning in terms of the mysteries it was developed to solve. You can start doing that by questioning the obvious.
For instance, think back to the time when photographs were not in living color. During that time, people referred to pictures as “photographs” instead of “black-and-white photographs” as done today. No one had thought of the possibility of color back then, so it was unnecessary to inject the adjective “black-and-white”.
Pretty obvious.
However, suppose you did include the phrase “black-and-white” before the existence of color photography. By shedding light on that reality, you’d become conscious of your current limitations and open your minds to new possibilities. Not so obvious anymore, right?
Is the Grass Greener on the Other Side?
The picture we’ve painted looks rosy so far, but it’s not all sunshine and rainbows on the other side either. Time to round off the discussion. Here are some aspects that might not make it into the job description of this “lucrative” position:
Boredom: Two quotes that’ll put this point into perspective:
Watching paint dry is exciting in comparison to writing and maintaining ETL logic
There is nothing more soul-sucking than writing, maintaining, modifying, and supporting ETL to produce data that you yourself never get to use or consume.
Generally, ETL jobs take a long time to execute. Issues and errors tend to either happen at runtime or show up as post-runtime assertions. Repeated iterations of developing pipelines for the new set of connectors will eventually set you on the path to panting on the hamster wheel of mediocrity as your job gets reduced to a glorified “Big Data plumber.”
There’s so much more you could be doing with your time, fellow! But more on that later.
Operational Creep: A large portion of data engineering is a high maintenance burden. Technically modern tools are supposed to make the lives of data engineers more productive, which might not always be the case. Sometimes, the same tools meant to reduce their burden end up introducing more technical debt over time.
Although the role of data engineers is becoming more specialized, operational creep hasn’t quite gone away. It’s just been distributed to these new roles.
Prone to Chaos: Data tools rely heavily on software engineering for inspiration. However, there are a few elements of data that make dabbling with ETL pipelines different than a codebase. For instance, you can’t edit your data like your code. Changing trivial things like column names is much harder to do because you have to rerun your ETL and modify your SQL first.
These new data structures and pipelines affect your system, making it more challenging to deploy a change, especially in the event of breakage. As long as data continues to evolve, the threat of data chaos will continue to loom over your head. Data engineering tools aren’t that effective, especially for differential data loads. Backfilling (the process of retroactively processing historical data in a data pipeline) can help reign in the data chaos, but it drops data debt in your lap.
Stuck between a rock and a hard place?
Final Thoughts
That’s it for this one, chief.
Data Engineers design the Lego blocks that Data Scientists put together in unconventional ways to create something new, helping businesses get an inch closer to their customers.
Having a deep understanding of the fundamentals is the stepping stone to becoming a “good” data engineer. Couple it with handy “soft skills” and you’ve got a seat at the table. For the people that might not be satisfied with just keeping all the plates spinning, I’m sure there are a few questions you’d want answers to:
Is there a level beyond “good?”
How about “kickass?”
If there is a level beyond “kickass,” what does that look like? We also highlighted a few aspects of data engineering that can be downright frustrating to deal with at times.
Do “kickass” data engineers also deal with these issues? Or have they found a way to circumvent them?
All these questions and much more will be answered in the next installment of this series, “Got What It Takes to be a Kickass Data Engineer.” Stay tuned!
References
Like this project
Posted Feb 5, 2024
The complete guide for data engineers entering the field. Contains resources, trends, statistics, and pop culture references :)