NeuralPath AI Investor Data Room Development
Oshingbesan Ademola
NeuralPath AI - Investor Data Room
Overview
Most data rooms show documents. This one has a conversation with them.
NeuralPath AI's Investor Data Room is a private, AI-powered web application that allows founders to share curated company documents with investors through a controlled invite system and allows investors to ask natural-language questions and receive accurate, cited, streaming answers without the founder needing to be in the room.
Built entirely solo using AI-assisted development (Claude Code), the product replaces the traditional static data room, a folder of PDFs shared via Google Drive or Notion, with an intelligent conversational interface backed by a full Retrieval-Augmented Generation (RAG) pipeline. Designed, coded, deployed, and iterated without a dedicated engineering team.
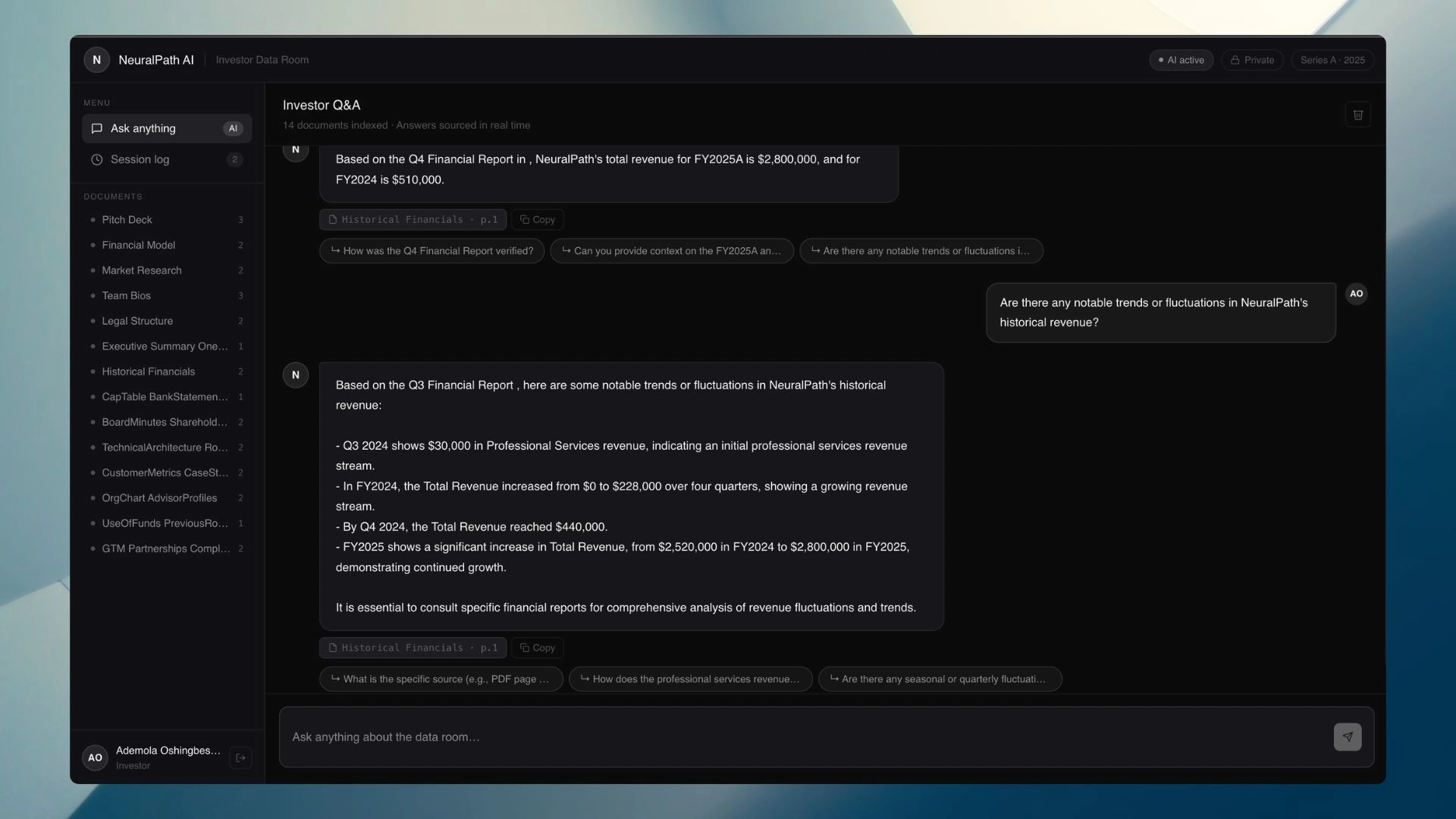
The investor experience—ask any question about the company and receive a precise, cited answer in under three seconds
The problem
Founders answer the same 40–80 due diligence questions across 10–30 investor conversations. That's weeks of avoidable repetition.
Fundraising involves dozens of investor conversations. Each investor works through the same documents at a different pace and asks largely the same questions. Answering each question takes 5–20 minutes, locating the relevant section, drafting a reply, and citing the source, and investor momentum is lost every time a question sits unanswered for 24–48 hours.
Traditional data rooms (Docsend, Google Drive, Notion) are passive; they show documents but provide no way for investors to interrogate them. Finding a specific metric buried in a 40-page financial model takes 10–15 minutes of manual reading. There is no way to ask a clarifying question without waiting for the founder to respond.
"An investor can ask, 'What is the LTV:CAC ratio?' and get a precise, streamed answer drawn from the financial model, cited to the exact document, in under three seconds without the founder being online."
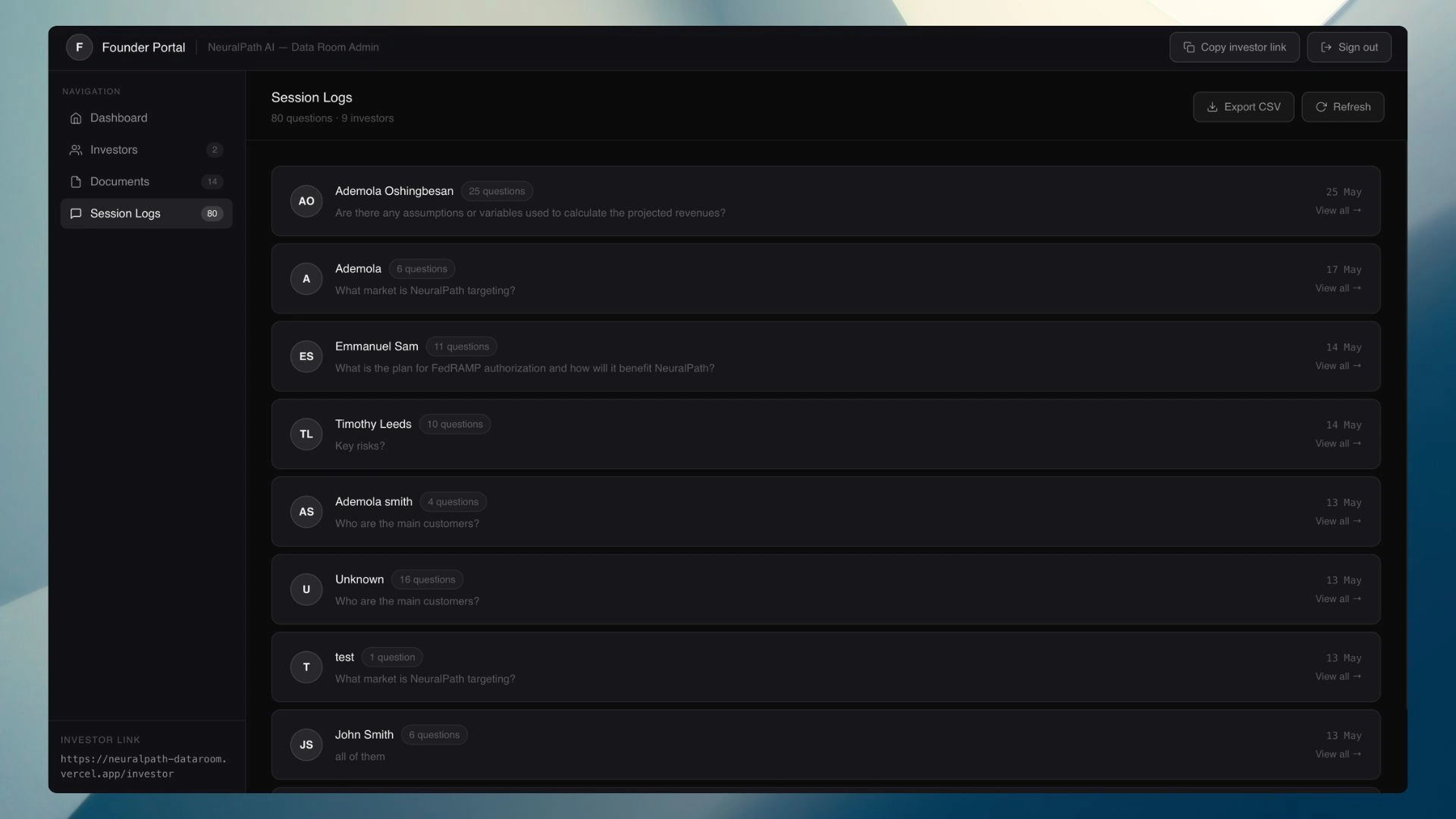
The founder control layer — per-investor visibility, access management, and full question audit trail
How it works
A full RAG pipeline from question to cited answer designed to be structurally incapable of hallucinating.
Documents are pre-processed into overlapping chunks, embedded into 384-dimensional vectors using fastembed (all-MiniLM-L6-v2, ONNX runtime), and stored in Supabase pgvector. At query time, the investor's question is embedded and matched against the stored vectors via cosine similarity search. The top five most relevant chunks are passed to Groq (llama-3.1-8b-instant) as the only context the model receives, making it structurally impossible for the AI to introduce facts not present in the uploaded documents.
The pipeline:
Question → vector: Investor's question embedded into a 384-dim vector via fastembed ONNX.
Vector search: Cosine similarity search in Supabase pgvector returns the top 5 relevant document chunks.
Grounded generation: Groq LLM synthesises a cited answer from retrieved chunks only, no external knowledge.
Streaming + logging: Answer delivered as SSE token stream; full Q&A stored in Supabase per investor.
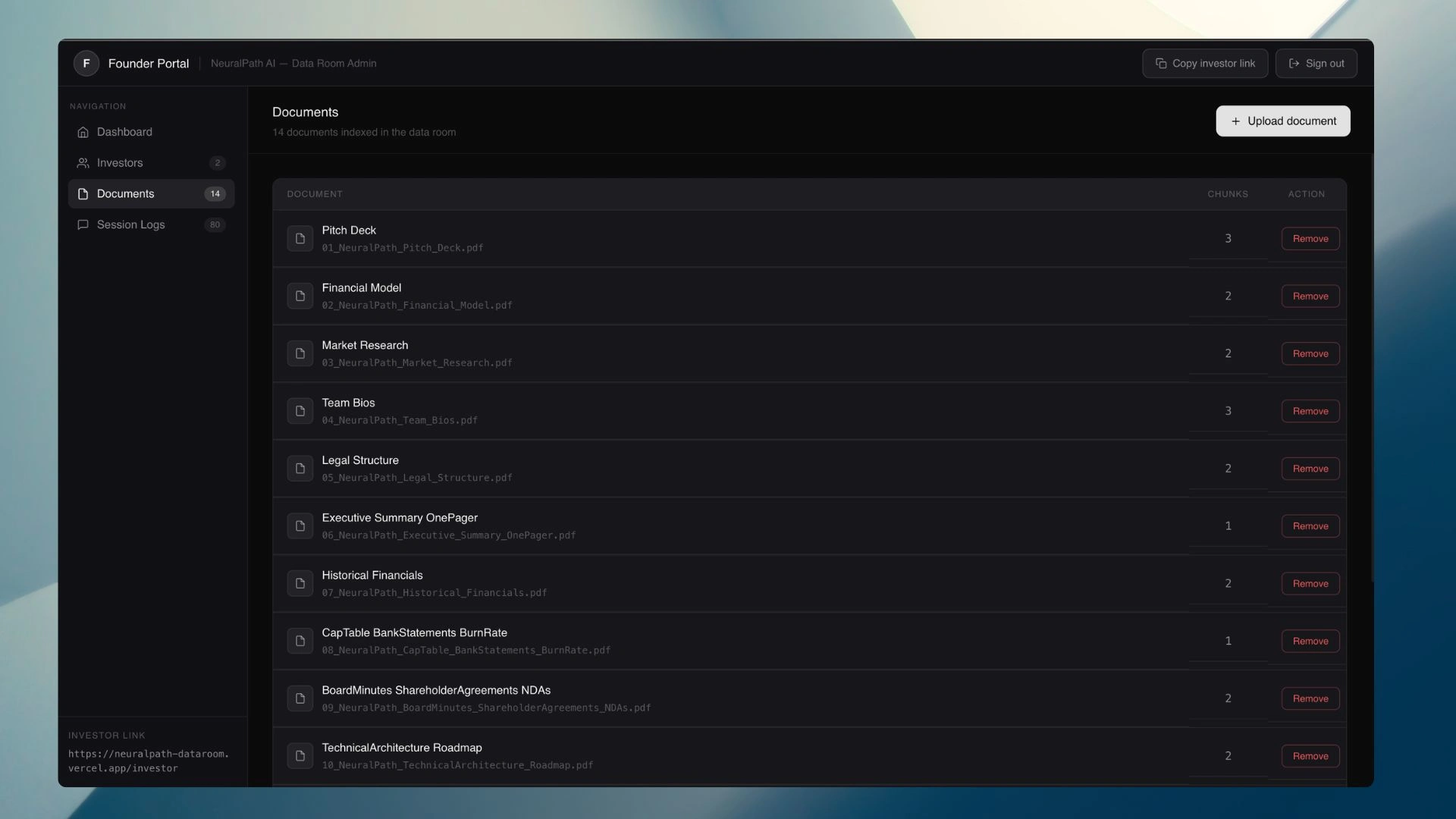
The document management layer—founders upload materials, the pipeline handles chunking, embedding, and indexing automatically
Key engineering decisions
Solving real production constraints from 1.5 GB memory limits to per-investor access control.
Render's free tier has a 512 MB RAM limit. The original sentence-transformers implementation consumed ~1.5 GB during model loading, three times the limit. The solution was switching to FastEmbed, which uses the ONNX runtime to serve the same all-MiniLM-L6-v2 model at ~150 MB peak memory bitwise-identical vectors, a fraction of the cost.
Access control was rebuilt from a shared password to a Google Docs-style token model. Each investor gets a unique, named invite link generated with a cryptographically secure token. The founder can revoke any investor instantly from the dashboard; the investor is locked out on their next page load. No shared secret that gets forwarded and loses control.
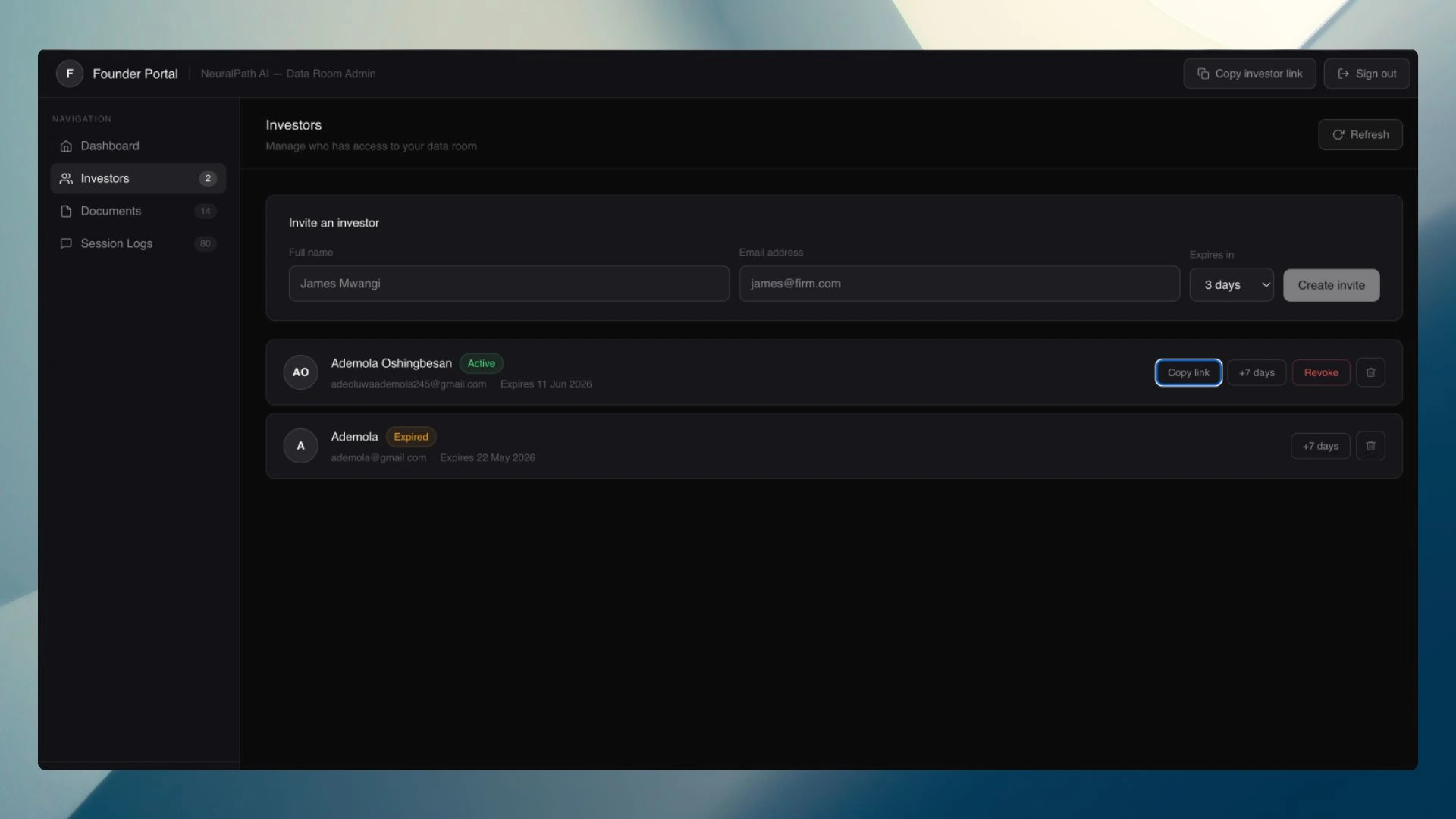
Per-investor access control—the URL is the password, but it's a per-person password with per-person controls
Outcomes
Live: Full-stack RAG application in production on Vercel + Render
< 3s: Question-to-cited-answer response time via Groq streaming
Zero hallucination: Architecture makes out-of-document answers structurally impossible
Skills:
RAG Architecture · AI Engineering · Next.js · Groq API · Supabase pgvector · Vector Embeddings · Vercel · Claude Code
If you're building an AI product, fundraising, or just want to talk about what went into this—my DMs are open.
Like this project
Posted Jun 4, 2026
Built a RAG-powered investor data room where founders share documents and investors get instant, cited AI answers — no founder presence required.
Likes
0
Views
2
Timeline
May 18, 2026 - May 25, 2026