Migration of ETL Pipelines to Apache Airflow
Aishwary Dhare

Migrating Client's ETL & Data Engineering Pipelines to Apache Airflow DAGs
As a retail-tech SaaS provider enabling shopping tils and other checkout solutions in the store, a part of the essential integrations is to ingest data like product catalogue, inventory, and promotions. Then also, export end-of-the-day reports like orders, transactions, customers.
The clients system needed to scale such multi gigabyte Data / ETL pipelines to 40+ retailers across 1000+ stores; the ingestion and export pipelines must run successfully as per the desired refresh-rate (frequency). This was time-sensitive and critical to business.
Initially the scheduled jobs were set up Cronjobs on self-managed linux servers.
In this case-study I address the pain-points and challenges with Cronjobs. The solutions I explored, and discarded; and the reasoning behind ultimately choosing Apache Airflow.
Cronjobs
cron is a shell command for scheduling a job (i.e. command or shell script) to run periodically at a fixed time, date, or interval. As scheduled, it is known as a cron job. Some great resources around cronjobs are crontab.guru, cronitor.io & cronboard.
While cronjobs are not broken, their intended usage is for local machine level operations rather than large scale ETL workloads. And it is not that the cronjobs are unreliable to run on schedule, the challenges with them are almost non-technical (since crazy engineers can scale anything to crazy lengths). The challenges are primarily operational and then technical.
The Challenges
Versioning
With a
crontab -l command you can print all the scheduled jobs, maintain a git file manually. In a large team, continue re-iterating about how keeping the git repo with latest crontab schedules up to date is a necessary part of the process, but to really enforce this – possible by crafting CI/CD pipelines around it.But still a challenge nonetheless because this is not a native feature of cron in linux to be managed remotely, the way around will be a long and puzzling road through orchestration tools like Ansible. Also, custom solutions require artists to develop them and a trained creative team to maintain them.
Collaboration
The vis-a-vis problem around versioning is collaboration between multiple members, the lack of a technically enforced git repo for all changes opens the gate to direct hot-changes without diff reviews and without a trace.
Overlapping modifications, and confusions; consequently causing operational instability, and daily drama on slack – "whodunnit?"
Distribution
The technical challenges start from here, load shedding or distribution of ETL pipelines and other scheduled jobs at scale.
Scheduled jobs at scale will start compressing together, fighting for their time-slot and their resource-share in the machine. And the largest of the machines are limited, vertical scaling increases cost in exponents rather than sums. So? Horizontal...with cronjobs?
If the operational issues so far did not seem big enough, then your inner techie might see these challenges and ponder for a workaround, rebelling against the idea to pick another fitting tool. In that case, I'd like to nudge towards the thought of tech maintainability as a large team rather than the ability of a singular self. Similar to the challenges of putting up a CI/CD pipeline and then layout out Ansible, Puppet etc around it, the idea of scaling-out Cronjobs across multiple instances is exciting – but messy beyond the initial estimate. You need a custom scheduler, agents, and other sidecar services to maintain it. The back-of-the-envelope architecture will resemble a wheel, re-inventing.
Observability
Best tech is the one which stays silent, except when it is mute or gagged. A lack of monitoring, logging or alerts, probably root from a lack of business.
My initial setup with cronjobs had slack alerts, cron dashboard, log files, a tooling for the log files, Datadog agents + infra monitoring. A good starting point, but in muddy waters – one or the other tooling would often require maintenance. Plus, it was not easily accessible.Whereas, a web dashboard to see the logs of a job filtered by datetime range would have been really great at the time. This was the first annoyance which led our ETL pipelines on the path to betterment.
Isolation
The overlapping jobs, running together, processing data from external clients' systems are vulnerable to resource starvation. On a usual day an unusually large amount of data from client side could cause your usually quick job to suddenly hog all of the memory and cpu. Bombing itself and all the rest.
Containerize the jobs with fixed resource allocation, but still scheduled as a cron; The wheel is finally complete, inventing a spaghetti'zed Kubernetes (K8) Cronjobs.
Recovery
A wrapper over the job execution command to retry it a few times in case of failure. And the execution is actually wrapped under an application framework which is also wrapped inside a container for isolation.
These wrappers and abstractions are age-old design patterns, not a problem as long as you don't have to peek under the layers. If it's a system of your own design, then you might have to debug all of your layers because the confidence hasn't developed yet. On the other hand, the confidence on battle-tested, highly-adopted tools with a wide community are unmatched.
Another challenge around recovery in ETL pipelines is to optimize them to recover on the particular stage of failure. These multi-stage pipelines perform heavy operations and if a latter stage fails, the former ones should not be required to process again. Also, the debuggability is a huge bonus in a multi-staged process where the state after each process stays idempotent.
Solution: The Candidates
The challenges and the problems I had with Cronjobs are quite standard in a heavy ETL workload system, with plenty of great solutions. But, instead of picking the first one from google search results, I evaluated them on multiple criterias, ie. –
Solves – Versioning, Collaboration, Distribution, Observability, Isolation, Recovery, Isolation
Supports containerization for the jobs which are tightly coupled with their underlying framework
Is open-source, to avoid vendor lock-in
Has wide community and support
Solution should ideally match skillset of the team (Python, Node.js, Go)
Has a simple learning Curve
Economical
I ruled out the proprietary AWS Glue, Google Dataflow, Azure Data Factory to avoid vendor lock-in. And the SaaS like Nexla, Fivetran either were too basic or their pricing didn’t suit our workload. Hashicorp Nomad passed most checks but the community was too small. I wanted to go ahead with Kubernetes (K8) Cronjobs because we could leverage our existing K8 knowledge and infra, but then I was introduced to Apache Airflow which offered the same plus more than K8 CronJobs.
Winner! Apache Airflow on K8s
"It is an open-source platform used to programmatically author, schedule, and monitor workflows, primarily for complex data engineering pipelines. It defines workflows as code (Python) using Directed Acyclic Graphs (DAGs) to manage task dependencies, providing features like a web UI for monitoring, retry mechanisms, and extensive integrations with cloud platforms."
The DAGs are composed of tasks in the form of a tree (Directed Acyclic Graphs, or DAG). Airflow remembers the inputs and outputs of each task in the DAG. The output from one task (parent node) can be forwarded ahead as input to one or many next set of tasks (children nodes). Also, on the other hand a task can also accept inputs from one or many tasks (parent nodes), waiting on to start execution once all, or some, or any of its parent finishes.
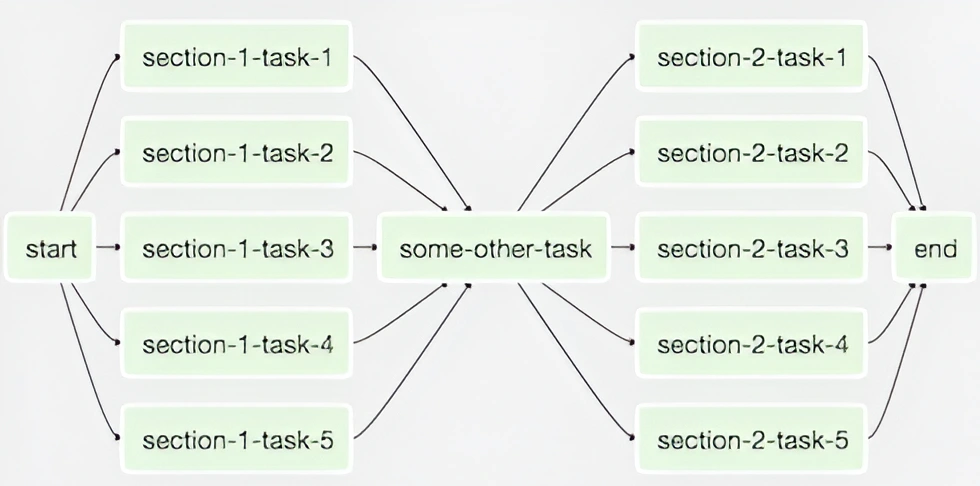
source: airflow.apache.org
The tasks can cross-communicate small data (like a file path or a database ID), as well as remember them for retry attempts and debugging.
Apache Airflow on Kubernetes (K8) unlocked the ability to parallelize both DAGs and their individual tasks. The Airflow's Kubernetes Executor creates a new pod for every task instance. Its configurations are similar to a K8 Deployment spec, for example they include– Docker image, CPU & memory requirements & limits, nodeSelector, taints & affinity considerations. Also, with Cluster Autoscaler, the system can automatically provision or terminate nodes based on demand. The pipelines are self-aware and intelligent, solving my technical challenges around distribution, observability, isolation, recovery while being cost-efficient.
Arflow’s Git integration allowed it to poll and pull new jobs while automatically updating DAG definitions as a diff is reviewed and merged to the main branch. This solved the versioning and collaboration dev-operations challenges.
We also implemented CI pipeline to prepare Docker images for the jobs that were tightly coupled with a framework (eg. Django management commands). And wrote some internal libraries to extract task specific metrics, raise alerts on slack, and more.
The team was also able to adopt this quickly as Airflow used Python and had a large community – huge bonus!
Like this project
Posted Feb 2, 2026
Migrated ETL pipelines to Apache Airflow, enhancing scalability and efficiency.
Likes
0
Views
5
Timeline
Sep 1, 2023 - Feb 1, 2024