Predicting Heart Disease
Cheva Kavitha
Predicting Heart Disease
This project focuses on predicting heart disease using machine learning techniques. We analyze various features such as age, sex, blood pressure, cholesterol levels, and other medical attributes to predict whether a person is likely to have heart disease. The goal is to build a predictive model that can assist healthcare professionals in early diagnosis and intervention.
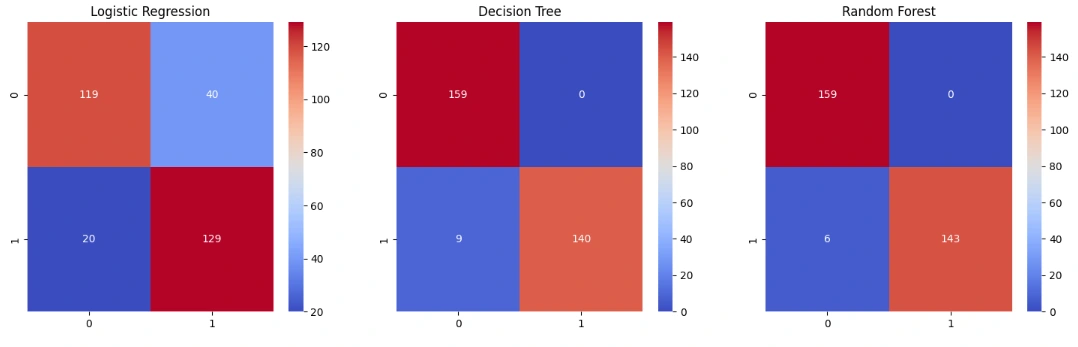
Table of Contents
Project Overview
Heart disease is one of the leading causes of death worldwide, and early detection is crucial for effective treatment. This project uses machine learning to predict the likelihood of heart disease based on several health-related features. By training a model on historical health data, we aim to provide a tool for predicting heart disease risk in individuals.
The Key Steps in the Project:
Data preprocessing and cleaning.
Feature selection and engineering.
Model selection and training.
Model evaluation and performance metrics.
Data Description
The dataset used in this project contains several attributes related to health and demographics, including:
Age: Age of the patient.Sex: Gender of the patient (1 = male, 0 = female).ChestPainType: Type of chest pain experienced.RestingBloodPressure: Blood pressure at rest.Cholesterol: Serum cholesterol in mg/dl.FastingBloodSugar: Whether the fasting blood sugar is greater than 120 mg/dl (1 = true, 0 = false).MaxHeartRate: Maximum heart rate achieved during exercise.ExerciseInducedAngina: Whether the patient experienced angina (1 = yes, 0 = no).Oldpeak: Depression induced by exercise relative to rest.Slope: Slope of the peak exercise ST segment.NumberOfMajorVessels: Number of major vessels colored by fluoroscopy.Thalassemia: A blood disorder (normal, fixed defect, or reversable defect).HeartDisease: Target variable (1 = presence of heart disease, 0 = absence).Data Preprocessing
Data preprocessing is an essential step in preparing the dataset for modeling. The following preprocessing steps were performed:
Missing Values Handling: Imputed missing values using the median for numerical features and the mode for categorical features.
Encoding Categorical Features: Categorical variables like
ChestPainType, Thalassemia, etc., were encoded using one-hot encoding.Feature Scaling: Numerical features were standardized or normalized to ensure the model treats all features equally.
Splitting the Dataset: The dataset was split into training and testing sets to evaluate model performance.
Modeling
Several machine learning models were used to predict heart disease, including:
Logistic Regression: A baseline model for binary classification.
Decision Trees: To understand feature importance and provide interpretable results.
Random Forest: A more complex ensemble model for better accuracy.
Support Vector Machine (SVM): To handle higher-dimensional feature spaces.
K-Nearest Neighbors (KNN): A simple yet effective classifier for this problem.
The models were trained on the training dataset and tuned for optimal performance using cross-validation.
Evaluation
Model evaluation was performed using the following metrics:
Accuracy: The proportion of correct predictions.
Precision: The ratio of true positive predictions to the total positive predictions.
Recall: The ratio of true positive predictions to the actual positives.
F1-Score: The harmonic mean of precision and recall.
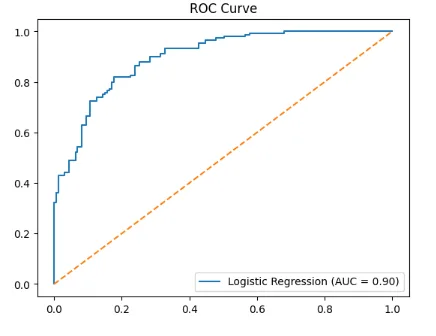
ROC-AUC: The area under the Receiver Operating Characteristic curve, measuring the model’s ability to distinguish between classes.
Each model’s performance was compared, and the best-performing model was selected for final predictions.
Usage
Clone this repository:
Load your dataset into the project.
Run the heart disease prediction script:
The model's predictions will be displayed, along with performance metrics such as accuracy and AUC.
Installation
Clone this repository:
Navigate to the project directory:
Install required dependencies:
Dependencies
pandas
numpy
scikit-learn
matplotlib
seaborn
xgboost
imbalanced-learn
Conclusion
In this project, we successfully built a predictive model to detect the presence of heart disease using machine learning techniques. By leveraging a variety of features such as age, sex, cholesterol levels, and heart rate, we were able to train several models to predict heart disease risk with high accuracy. The key steps included:
Data Preprocessing: Handling missing values, encoding categorical variables, and scaling numerical features ensured that the data was well-prepared for modeling.
Model Selection: Various models, including Logistic Regression, Decision Trees, Random Forest, Support Vector Machines, and K-Nearest Neighbors, were trained and evaluated.
Model Evaluation: Performance was assessed using metrics such as accuracy, precision, recall, F1-score, and ROC-AUC, which provided insights into the models' ability to predict heart disease accurately.
Key Insights:
Feature Importance: Features like cholesterol levels, age, and maximum heart rate were found to be the most influential in predicting heart disease.
Model Performance: The Random Forest model provided the best results in terms of accuracy and AUC, demonstrating its ability to handle complex, non-linear relationships in the data.
Impact:
This model can serve as a valuable tool for healthcare professionals to identify individuals at high risk for heart disease. Early detection and intervention can help prevent severe health issues and improve patient outcomes.
Future Work:
Advanced Feature Engineering: Exploring additional health-related features, such as lifestyle factors or family history, could further improve prediction accuracy.
Model Optimization: Hyperparameter tuning and model ensemble techniques could be explored to boost performance.
Real-time Prediction: Deploying the model into a real-time healthcare application could enable immediate risk assessments for new patients.
Overall, this project highlights the potential of machine learning in healthcare, demonstrating how predictive models can support early diagnosis and enhance preventive healthcare strategies.
Like this project
Posted Feb 6, 2025
Contribute to chevvakavitha/Predicting-Heart-Disease development by creating an account on GitHub.