rox-test
Leonardo Rickli
rox-test
This is a test from Rox Partner that asks for a cloud infrastructure for engineering/data analysis from a fictitious company that makes bicycles. There is a brazilian portuguese version for this test if you want to read this repository in another language. The test asks for Data Engineering skills to optimize the process. The following items are requested:
Do conceptual modeling of the data.
Creation of the necessary infrastructure.
Creation of all the necessary artifacts to upload the files to the created database.
SCRIPT development for data analysis.
(optional) Create a report in any data visualization tool.
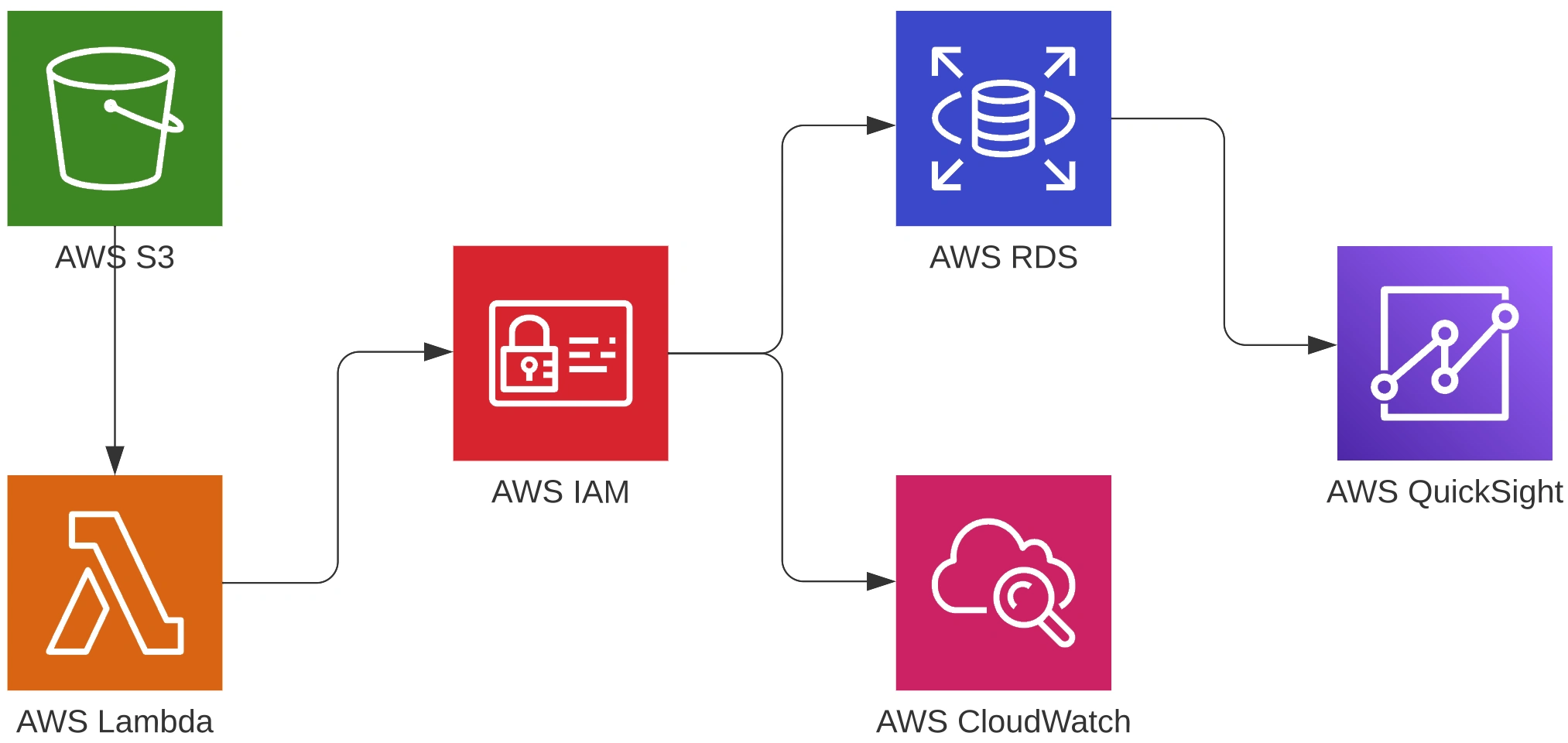
The AWS platform was used to create the necessary infrastructure because I believe it offers the best solution for the promoted activity. In addition, I do already have experience and the Solutions Architect certification on the platform. The following AWS tools and others were used:
RDS: An RDBMS (Relational Database Management System) tool will be used as it best meets the proposal. The chosen database was MySQL 8.0.33, Single-AZ, db.t3.micro with 20GB of General Purpose SSD storage (gp3), automatic backup, and access with public IP, maintaining the free-tier architecture. The data presented does not have a considerable size so we do not need a robust database in processing to meet the required situation.
S3: It will be created a bucket for the cleaned files that were created based on the raw files provided.
Lambda: We will use Lambda to execute triggers for the PUT commands in S3.
IAM: It will be used to give roles to the Lambda function so that we have access to the S3, CloudWatch, and RDS tools.
CloudWatch: It will be used to check our Lambda function's logs, to check its progress. It is here that we will verify if the triggers are really working after the testing phase inside the Lambda itself.
QuickSight: Used for viewing data through a connection made to the RDS database.
Excel: Used for preliminary data analysis only.
Pandas: It will be used for data cleaning and EDA (Exploratory Data Analysis) of the files provided in the test.
DBeaver: Used to create the on-premises database for testing, create the ERD (Entity Relationship Diagram) for Data Modeling and verify the ingestion of files in RDS.
Lucidchart: Used for the architecture diagram provided in this test.
Data Cleaning and EDA
An on-premises test environment was created where the data was ingested into a MySQL database to check whether it would accept the data presented in its raw format. A lot of data cleaning and EDA was made to overcome the constraints imposed by the rigid schema of the database created. These files are in .ipynb format so we can see the progress of exploration and data cleaning. Some details about cleaning:
Files with ";" separators were changed to the traditional "," separators.
Columns with date and time were properly allocated to the DATETIME format.
"null" texts (in any variation of uppercase or lowercase) have been removed.
It was found that there are large lines of text in some columns of the "Person" table, allocating the column to the LONGTEXT format.
There were cases of repeated values in the primary key for the "SpecialOfferProduct" table, these lines were removed.
Data Modeling
This is the preliminary diagram that was sent along with the test:
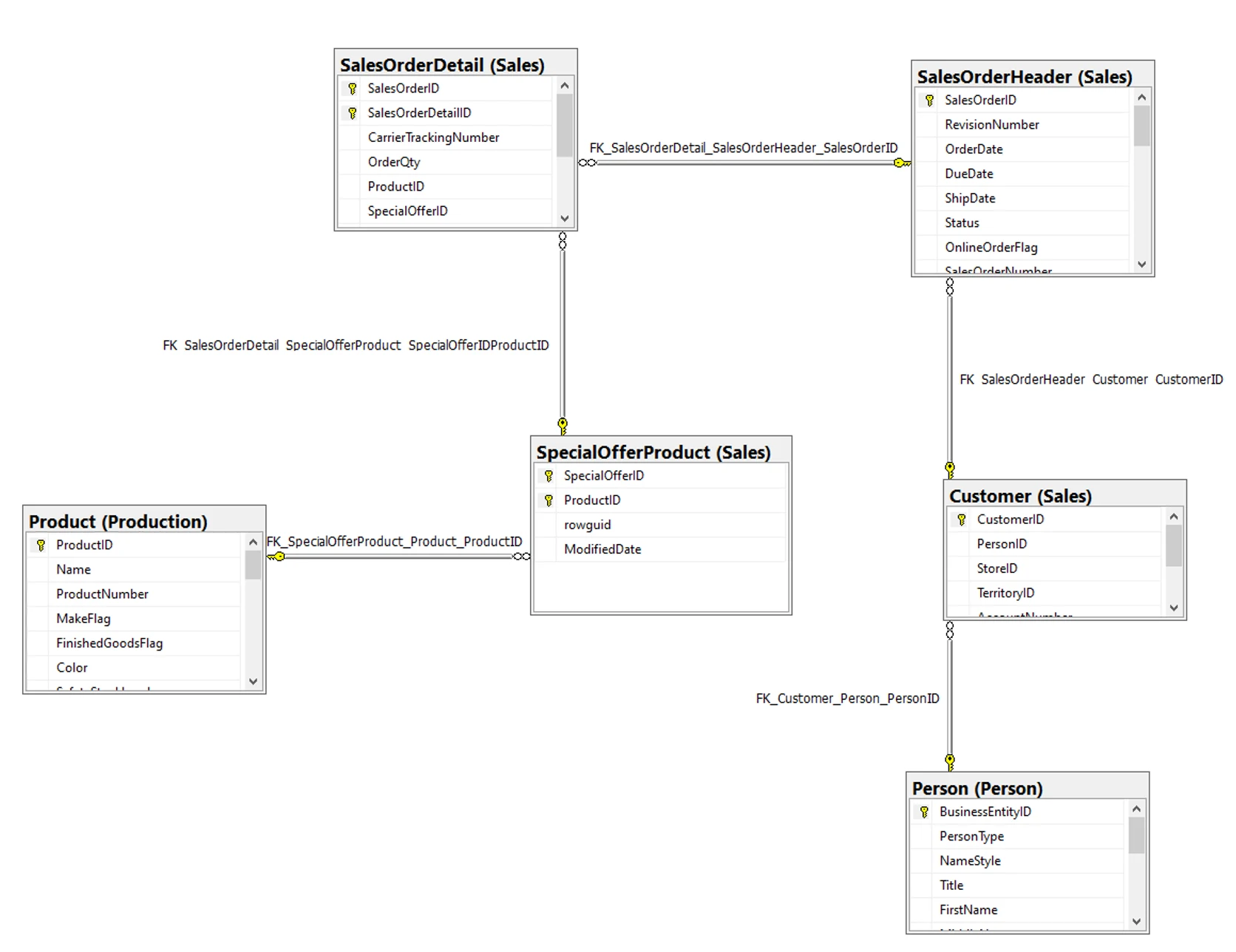
According to the diagram, the database will have these tables:
testeRox
By analyzing the .csv files we find the columns and the primary and foreign keys of the tables. A Python script was made for the connection to the MySQL database within RDS so we can execute these SQL queries. These queries are used to create the schema in the MySQL database. It is important to note that, for the Python script to run locally on your machine, it is necessary to update the inbound rules of the security group allocated for the RDS instance by selecting port 3306 (MySQL) and inserting your machine's IP. It is not good practice to use the "0.0.0.0/0" IP as it is too generic, reducing security in your instance. It will also be necessary to create a public IP when creating the instance.
The ERD below shows the relationship between the entities (tables):
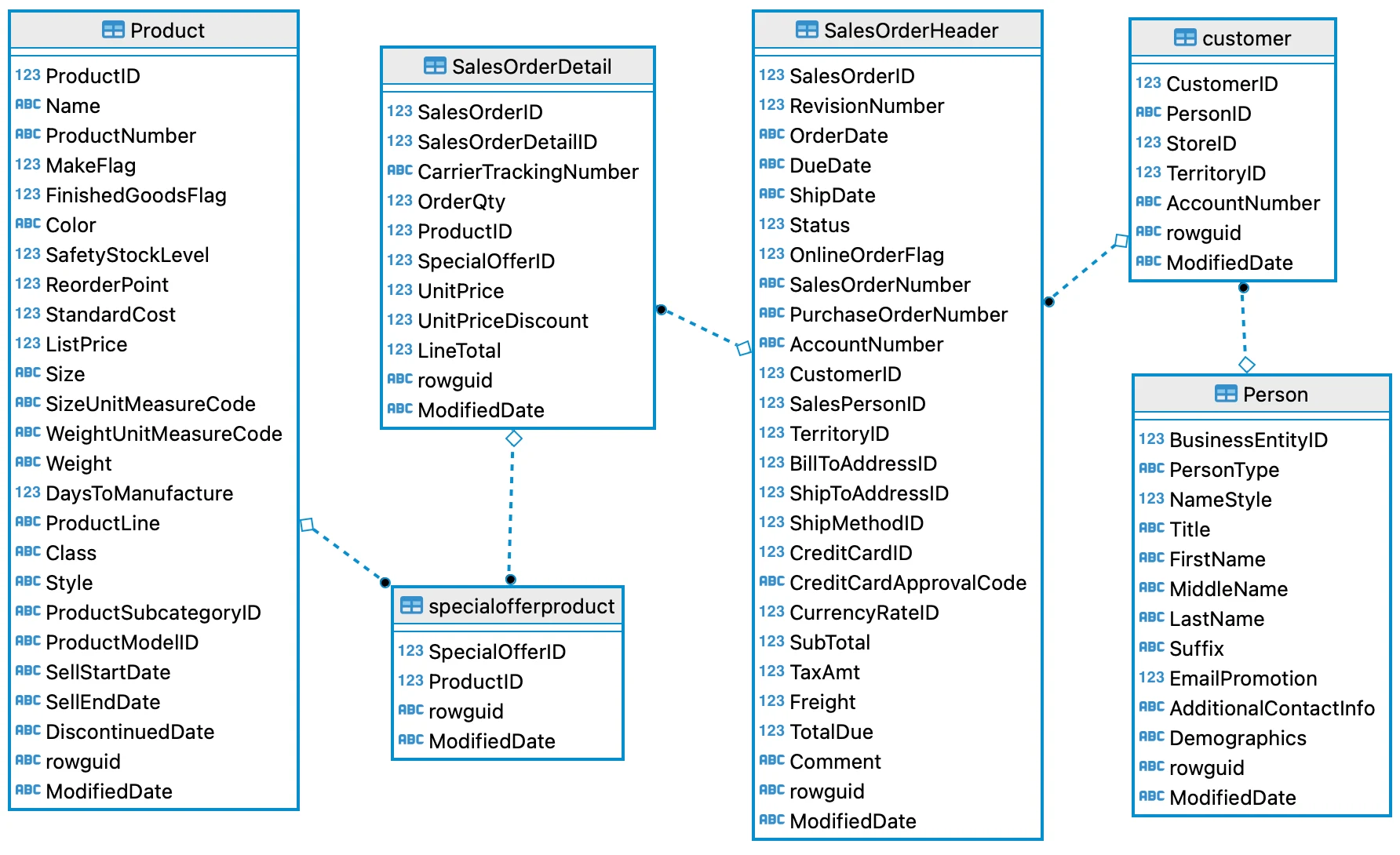
Special attention was needed to the datatypes of certain columns, especially in the columns with dates. A special case is in the Person table, where we find the columns "AdditionalContactInfo" and "Demographics". The LONGTEXT datatype was necessary because there are long lines of text in xml format.
ETL
A Python script was made to upload the .csv files already cleaned through Data Cleaning.
A Lambda function is called through this Python script each time a file is uploaded to the S3 bucket. This way, every time a file is inserted into the bucket, it will automatically be fed into our RDS database. It was also necessary to implement a MySQL layer with the necessary packages to transform and load the .csv files into the RDS database through the Lambda function. The function timeout was increased because the first ETL was not successful, this action is recommended for when the function tends to process a large number of files, the three seconds that are designated by default across the platform are usually not enough for this type of transformation. Using environment variables inside the Python function to protect personal data is recommended.
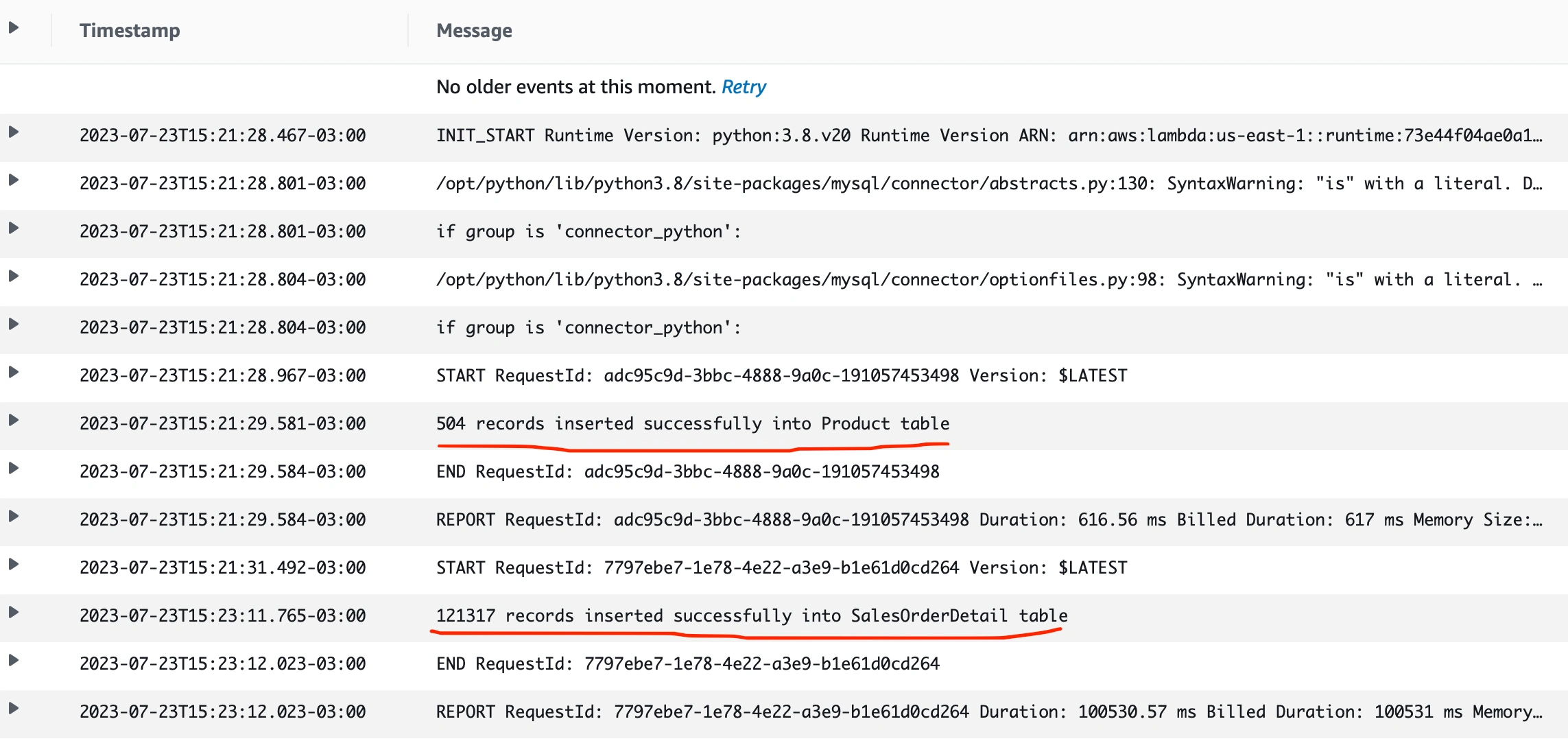
With the proper permissions established via IAM, it is possible to monitor the ETL process performed by Lambda through CloudWatch logs. This is great for monitoring the initial tests and the final ingestion of files into the RDS instance after the testing phase.
Data Analysis
Based on the implemented solution, answer the following questions:
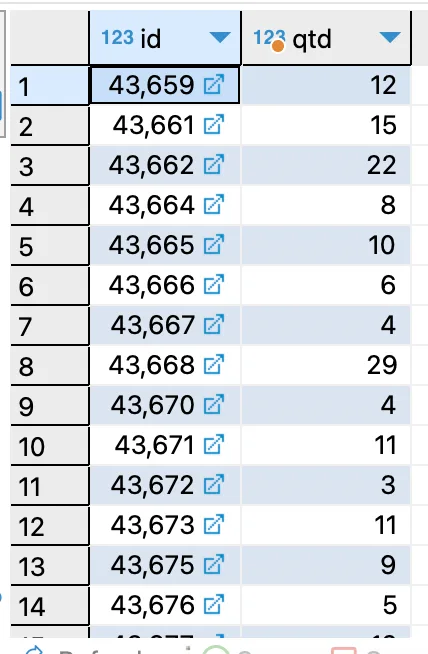
Write a query that returns the number of rows in the Sales.SalesOrderDetail table by the SalesOrderID field, provided they have at least three rows of details.
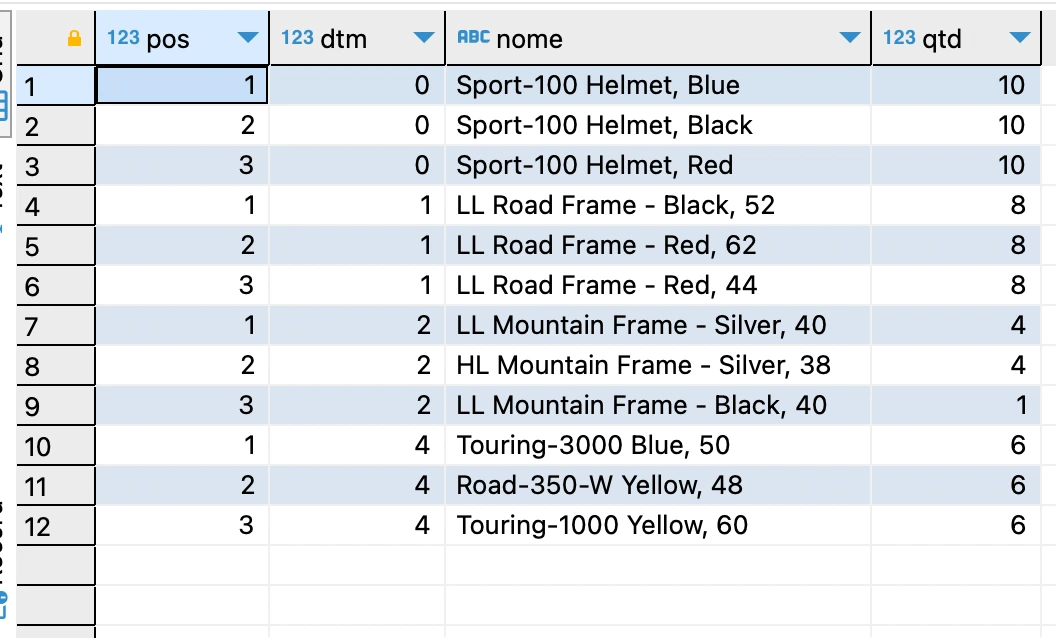
Write a query that links the tables Sales.SalesOrderDetail, Sales.SpecialOfferProduct and Production.Product and returns the 3 most sold products (Name) by the sum of OrderQty, grouped by the number of days to manufacture (DaysToManufacture).
Write a query linking the Person.Person, Sales.Customer, and Sales.SalesOrderHeader tables to get a list of customer names and a count of orders placed.
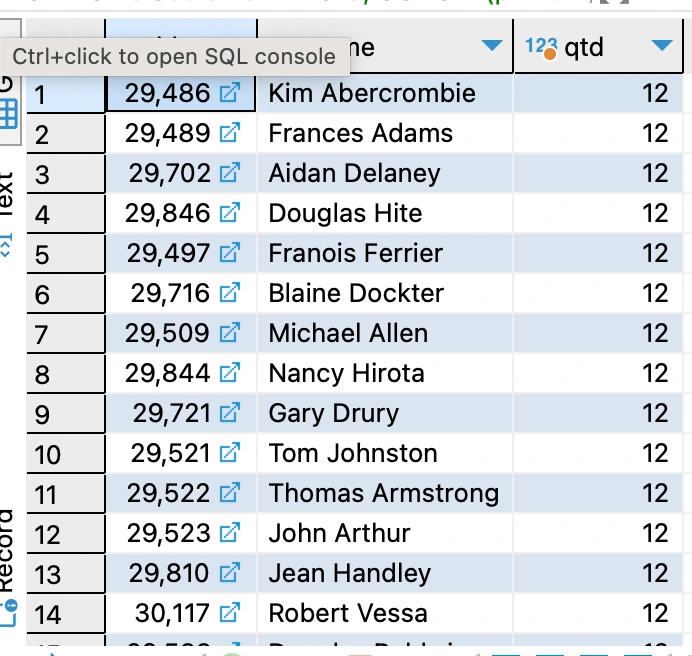
Write a query using the tables Sales.SalesOrderHeader, Sales.SalesOrderDetail and Production.Product, to obtain the total sum of products (OrderQty) by ProductID and OrderDate.
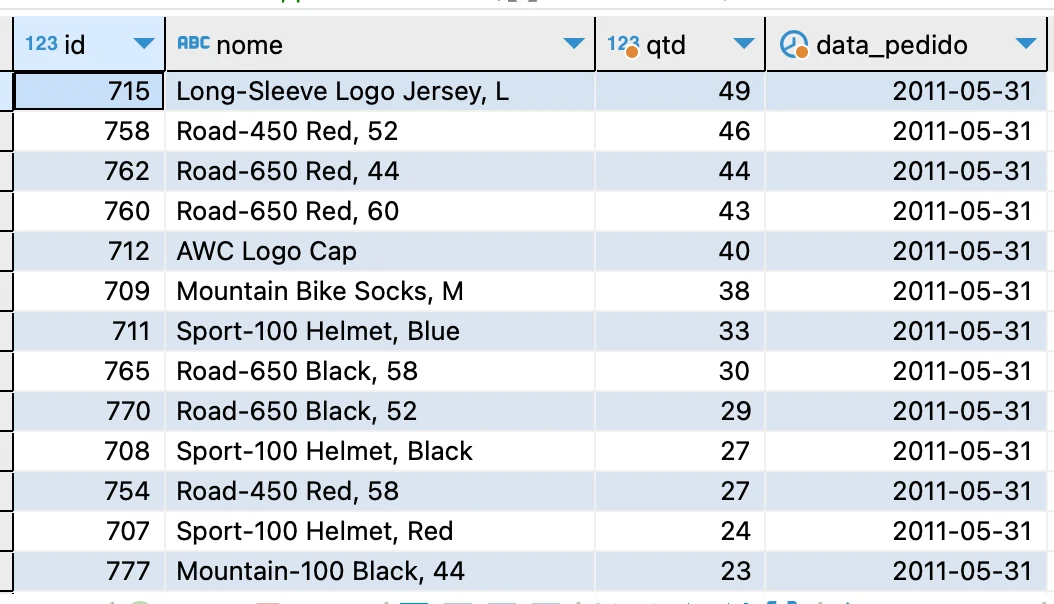
Write a query showing the SalesOrderID, OrderDate, and TotalDue fields from the Sales.SalesOrderHeader table. Get only the lines where the order was placed during September/2011 and the total due is above 1,000. Sort by descending total due.
In this case, the query did not return any values because there is no data in this proposed interval.
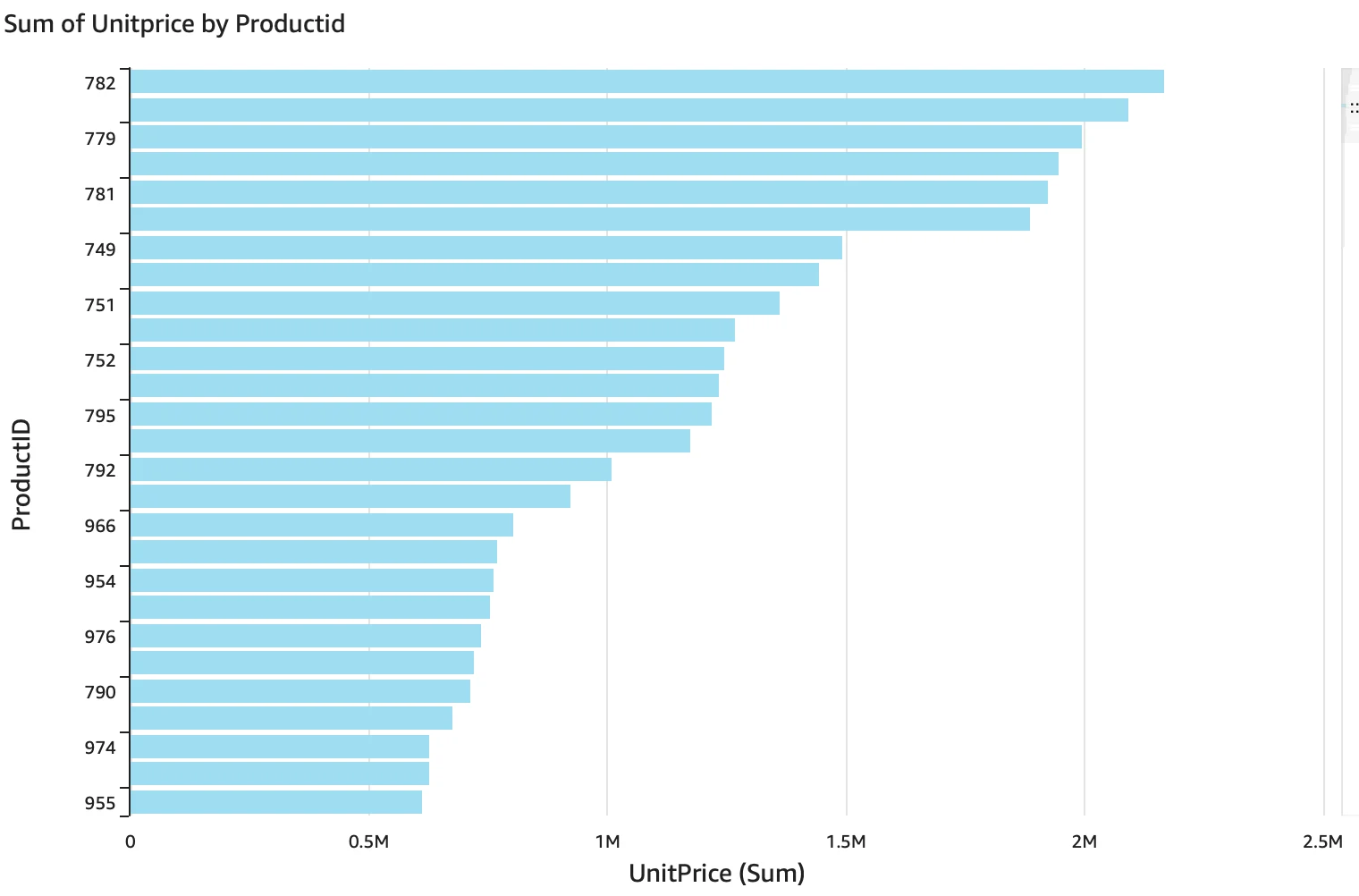
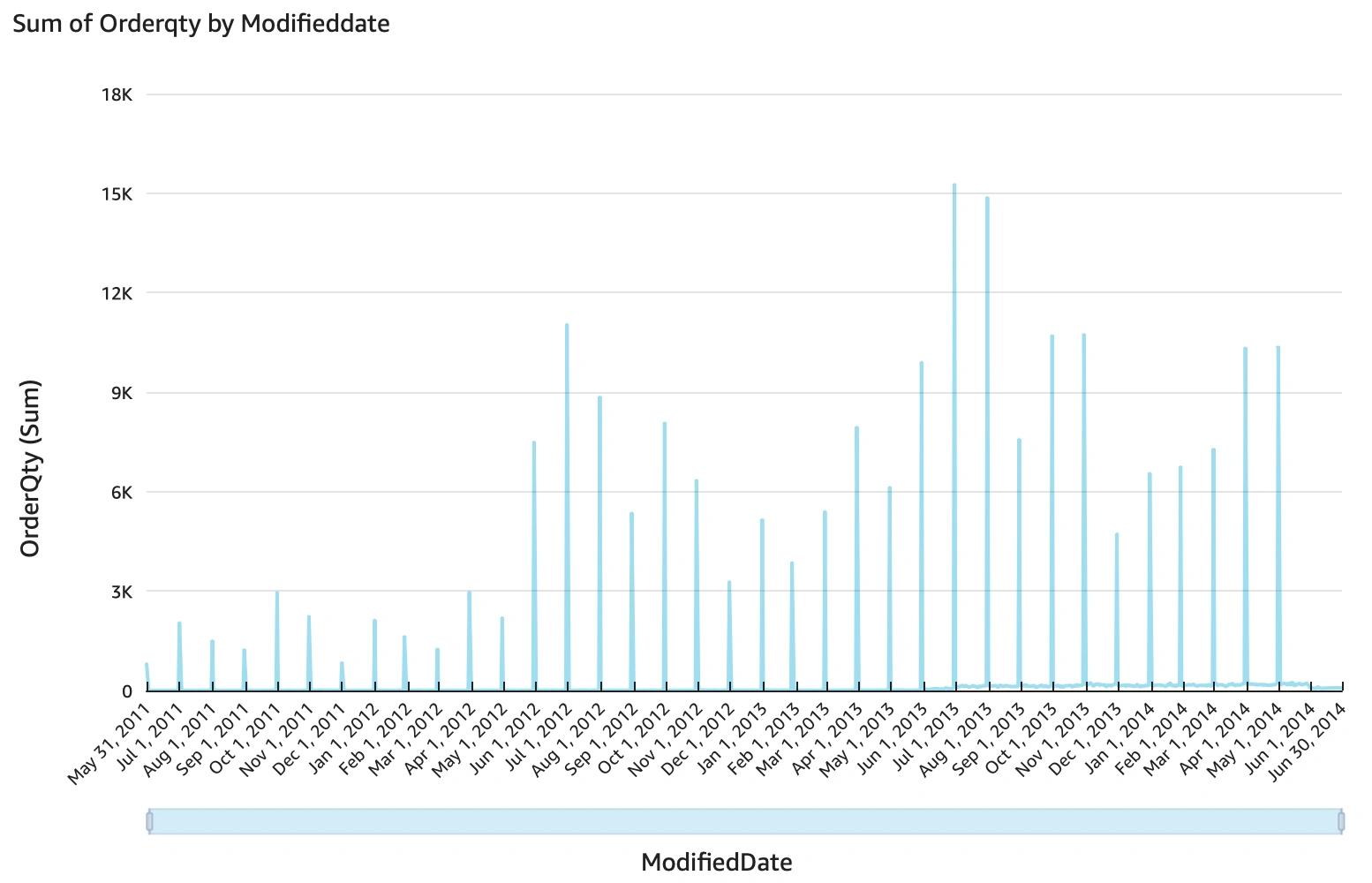
Data Visualization
Using AWS QuickSight and making sure that the proper permissions are granted to IAM through roles and VPC alignment, we can use it to connect to RDS and generate dashboards. Below are some visualizations.
Other Architectures
In the conception of the project and in the course of the processes, some proposals for different approaches and architectures emerged that could be discussed and/or perhaps addressed in the future. Below are some of these approaches:
When testing the on-premises data transfer to the MySQL database in the RDS instance, there is the possibility of directly transferring the on-premises files to the existing database in the cloud. This measure is not viable because the data transfer is very slow, it requires a schema to already be established in the database and the architecture is poor, making future automation and improvements unfeasible.
In the AWS documentation, it was suggested to back up the on-premises database using Percona's XtraBackup tool. This measure may be feasible in the event of a direct transfer from the on-premises database to the cloud.
After designing this project, it is possible to create a template in the CloudFormation tool to automate the creation of the stack used in this repository.
It is possible that the data ingestion of objects (.csv files) within S3 is done by the AWS Glue tool for performing ETL. Subsequently, this processed data is sent to AWS Athena for data analysis. Athena is easily connected to Tableau for data visualization in addition to QuickSight.
Like this project
Posted Apr 29, 2024
Data Engineeering project using AWS Lambda to extract and process data from a local PostgreSQL database and load into AWS RDS.
Likes
0
Views
49
Clients
Rox Partner