brazil-e-commerce-azure-databricks
Leonardo Rickli
brazil-e-commerce-azure-databricks

In this project, we will be using some ETL, analytics, and BI tools on Microsoft Azure cloud in the company of Databricks and Power Bi. We will use the Brazilian E-Commerce Public Dataset by Olist to create a relational database for analysis.
The Microsoft Azure platform was used to create the necessary infrastructure because I believe it offers a better connection with Databricks and Power Bi. The following Azure tools and others were used:
Data Factory: Used for the ingestion of the raw files that you can find in this repository. It will then send those raw files to a staging area in a data lake inside a Storage Account
Data Lake Gen 2: These will be the staging areas for the data. The first staging area will be the raw data that will be ingested by Databricks. The second staging area will be the transformed data by Databricks that will be ingested by Azure Synapse.
Databricks: Used for data cleaning and some EDA (Exploratory Data Analysis). This section is important because it will make the correct schema for further data analysis on Synapse.
Synapse: This is the analytics tool offered by Azure. We can use the transformed data to make a relational database model and query data for analytics.
Power Bi: Used for presenting dashboards with the data that is the relational format.
Using a fundamental Data Engineering method called ETL (Extract, Transform, and Load), we will extract the raw files from this repository, transform it to align with the tight schema constraints of a data warehouse and load it into a data warehouse for analysis and visualizations.
Before we start deploying the resources, it's important to create a unique resource group for this project.
Extract
Using Data Factory, we establish a source (the raw files from this repository) and the sink (the staging area where the data will be sent).
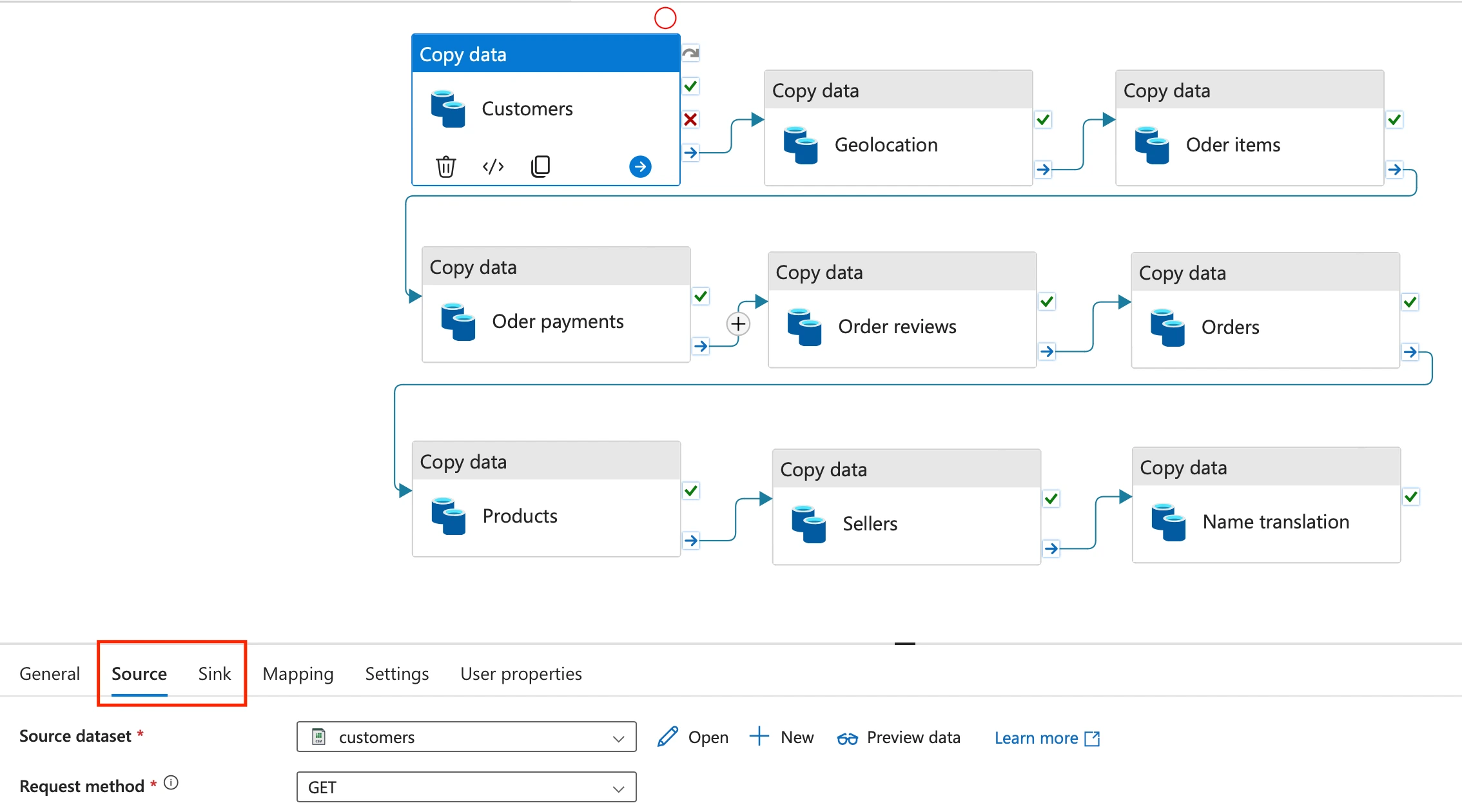
Transform
After the data has been inserted into the first staging area, we will use Databricks to transform the data through cleaning and EDA. Databricks goes in this process with the use of a notebook that is also linked in this repository.
The majority of the tables were already pretty decent in terms of cleaning, there were just some minor datatype changes for a better schema representation of the columns. There was one exception with the table "order_reviews", there were some problematic rows that were giving error messages when Synapse was trying to read it, those rows had double quotes in them, so I managed to delete all of those rows.
Once the data is transformed, it is then sent to another staging area where it will be ingested by Synapse.
Load
Data is now loaded into Synapse, we will make this data become relational by creating an ERD so we can query some answers from it.
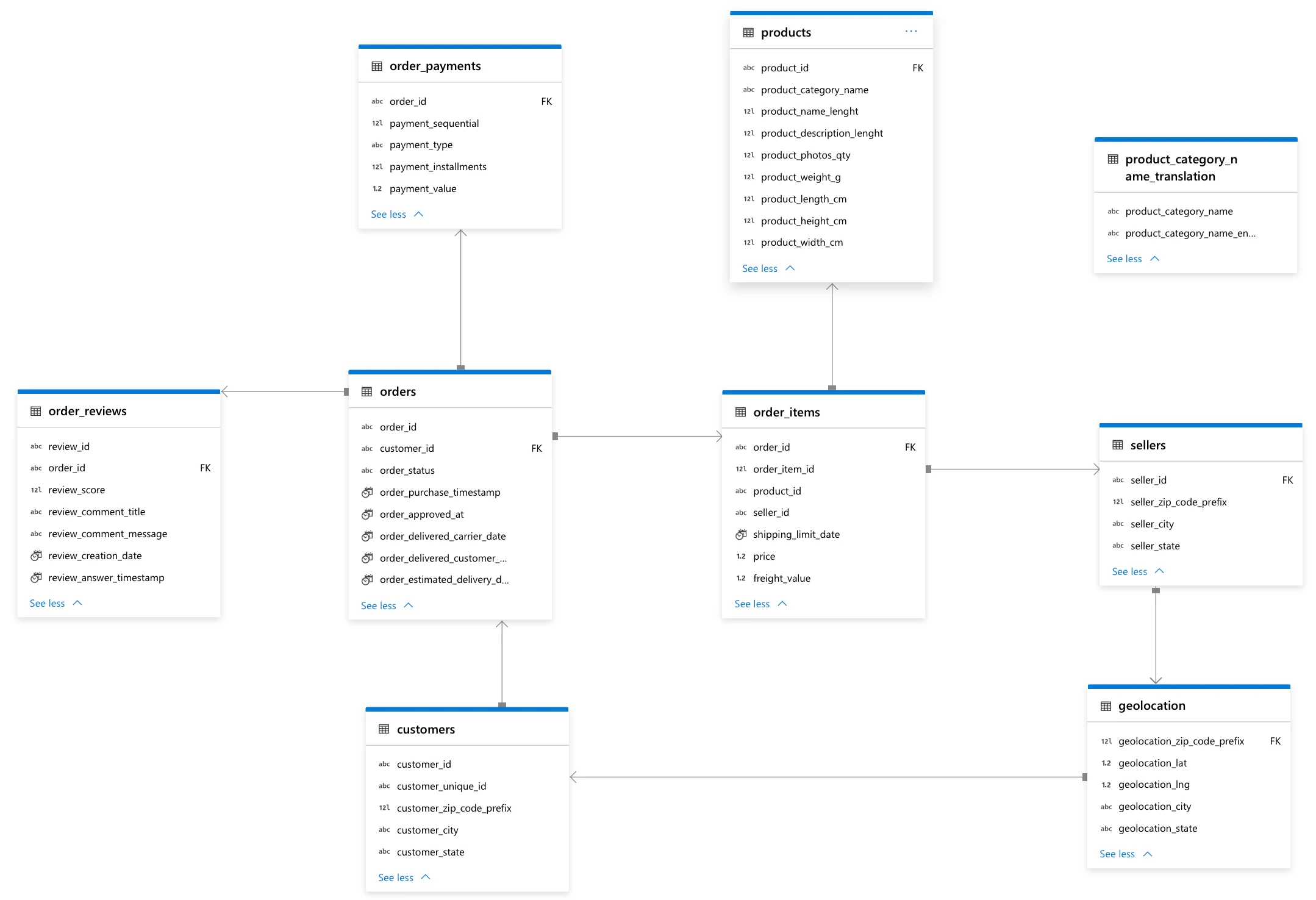
We can now query some answers using SQL.
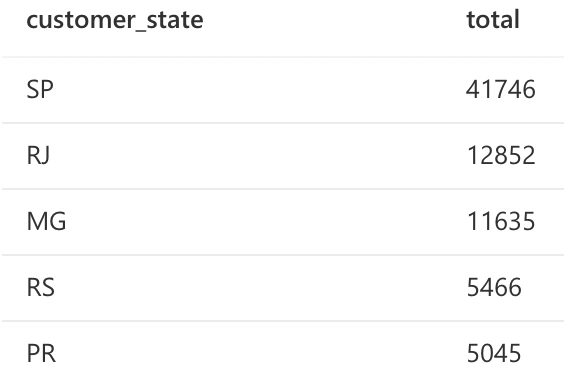
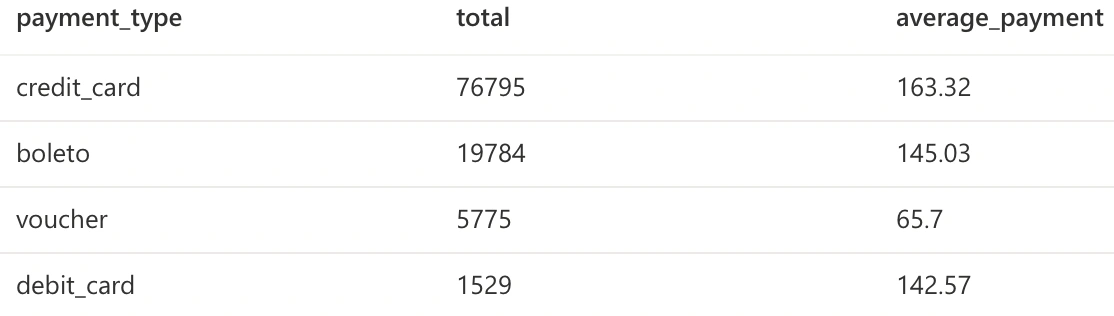
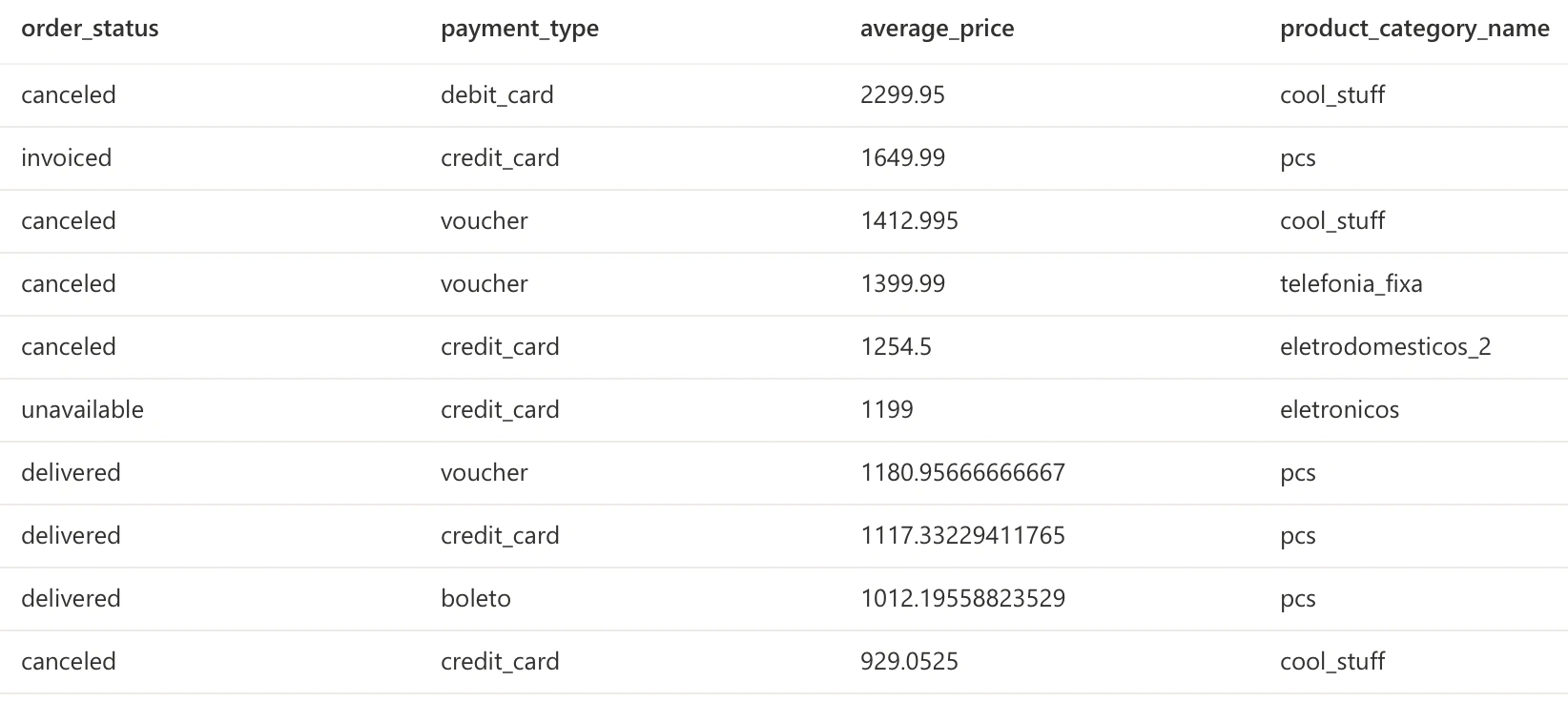
Dashboards
Before we start making our dashboards, we have to establish a connection between Power Bi and Synapse. To do that, download Power Bi desktop and grab the "Serverless SQL endpoint" inside the resource group that you are using.
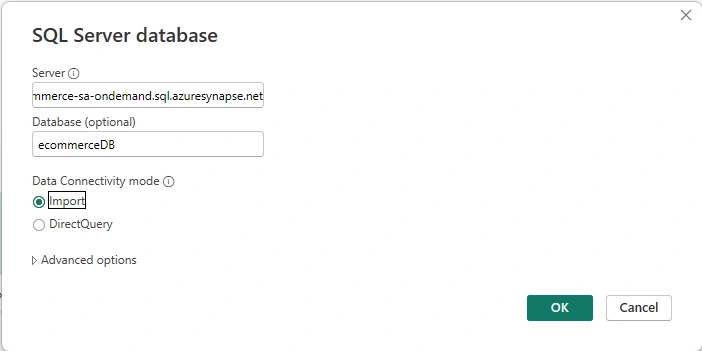
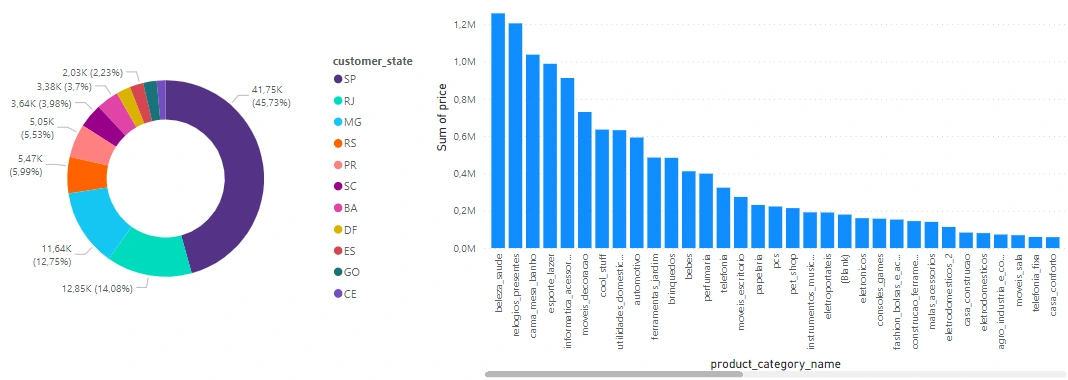
Now that we inserted our credentials in, we can start making some dashboards.
Like this project
Posted Apr 29, 2024
Data engineering and analytics project using Microsoft Azure tools like Data Factory, Data Lake, Synapse, Databricks and Power Bi.