welfare-programs-streaming-gcp
Leonardo Rickli
welfare-programs-streaming-gcp
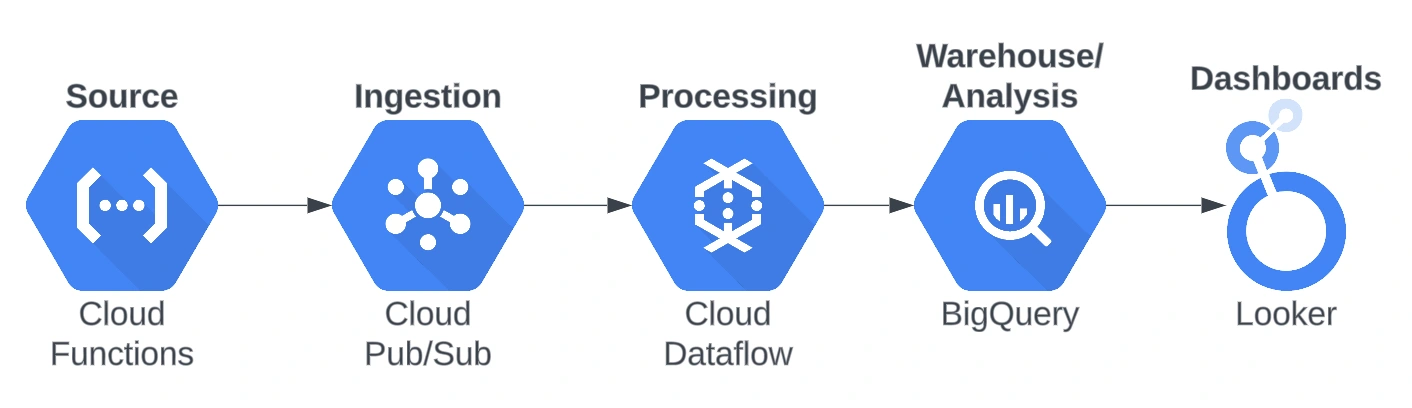
This project explores the Google Cloud Platform's resources to create a streaming pipeline to process real-time data from the Portal da Transparência (Welfare Programs) API. Actually, there is no real-time data provided by this API. We generate the real-time data through a Python script.
The Transparency Portal (Portal da Transparência) is a digital platform designed to provide detailed information about public entities' expenditures and financial management. Its primary goal is to promote transparency in public administration, allowing citizens, journalists, researchers, and other interested parties to access and analyze data related to revenues, expenses, contracts, agreements, and salaries of public servants, among other aspects.
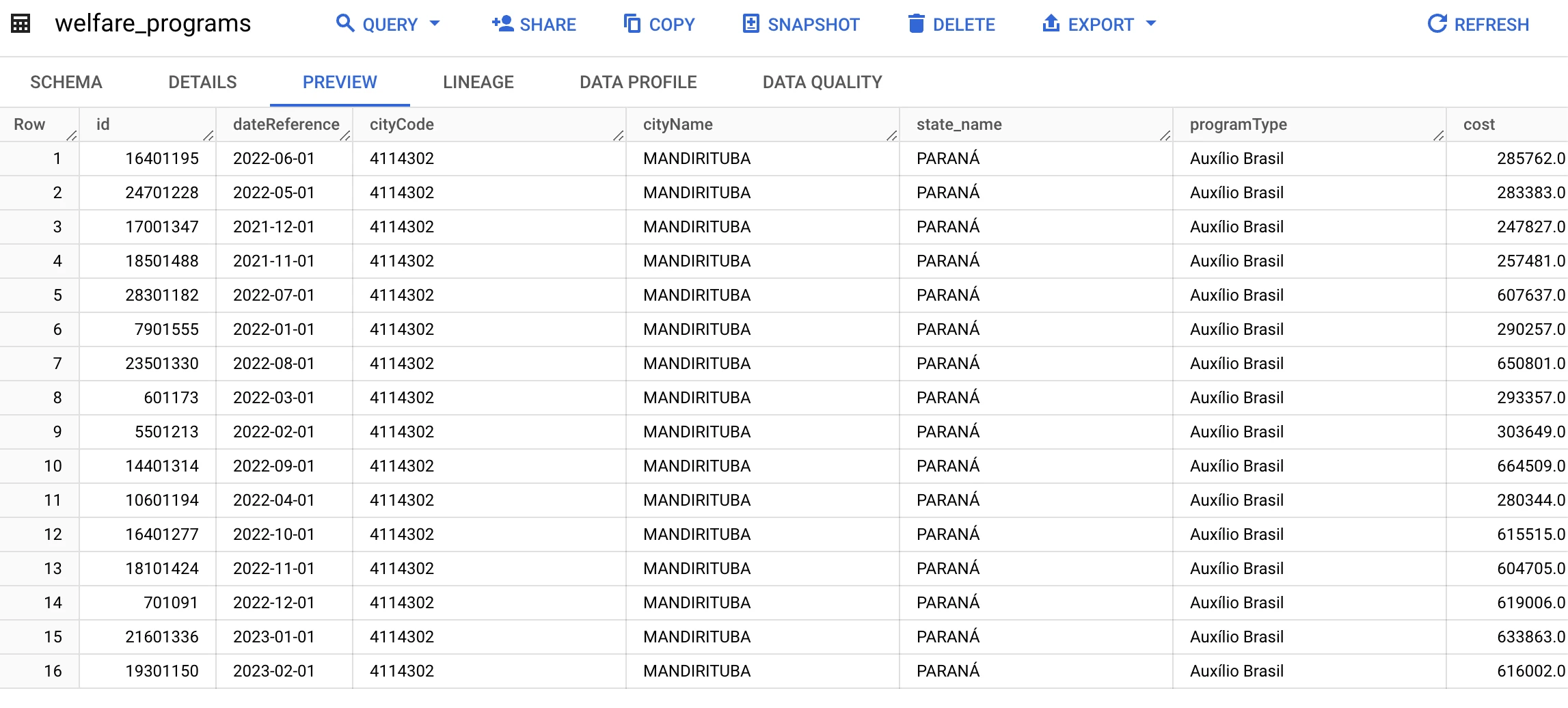
Data is requested via an API from the Portal da Transparência website in JSON format, transformed to rename and add some columns and finally inserted into BigQuery in tabular format for analysis.
The following GCP resources were used:
Cloud Functions: Used to generate the real-time data in a FaaS (Function as a Service) manner. This way we can deploy the script in the cloud, instead of generating the data from your local machine.
Pub/Sub: The main representative of the streaming class in GCP. I could say that pretty much every streaming pipeline will use Pub/Sub as their main motor for real-time messaging solutions on the cloud.
Dataflow: This is the best tool to use when streaming data with Pub/Sub on GCP. Used to transform the data received from Pub/Sub and then write to BigQuery.
BigQuery: The flagship of GCP; used mainly for warehousing (it can now be a data lake) and analytics. For this project, it is used for storing the transformed data from Dataflow in tabular format and some analytics.
Looker Studio: Used for creating dashboards for our data.
Before we begin
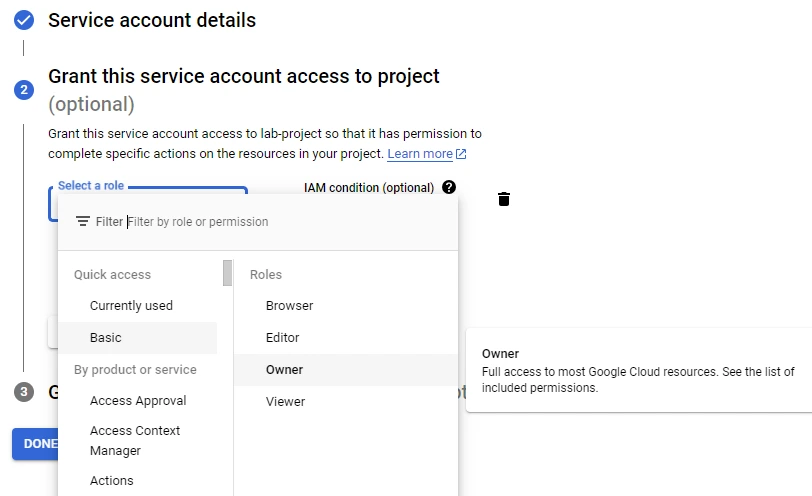
Create a new project so it's easier to shut down all the services used when there is no more need. The second step we take is to create a service account for our local machine so it has access to GCP's resources. To do that, we go to IAM & Admin in the Service Accounts section and create a new one. One important step is defining a role for this service account; In this case, we will use the Owner role like in the image below. Be aware that in the cloud, we like to use the least-privilege principle and this Owner role will definitely be unaligned with this principle.
After you've created your service account, you can create a JSON key that will be downloaded to your local machine. I like to rename this key into a simpler name and store it in the folder that I'm working with my project, so we don't have to declare the key's absolute path inside our Python scripts, at least on Linux based machines.
Create a GCS bucket for your project and add the folders "temp" (for the temporary files that Dataflow will create) and "template" (for when you deploy your beam_pipeline in the later steps of this project).
Finally, I like to use the Compute Engine default service account as my main service account for my cloud resources. Assign the "BigQuery Data Editor" and the "Pub/Sub Editor" roles on it.
Ingestion
First, we have to create an account on Portal da Transparência's website so it gives us a key for accessing the API data. This key will be inserted on the Python script. When you request data from an API, it usually comes in JSON format (you can check out a sample_data in its raw form). The data_generator script was created so we can get data from the Auxílio Brasil's get request of the API and then publish it to a Pub/Sub topic. This script also simulates a streaming process by sending an object of the JSON file for a given amount of time that you can set; in this case, a message (a JSON object) will be publish every five seconds to a Pub/Sub topic.
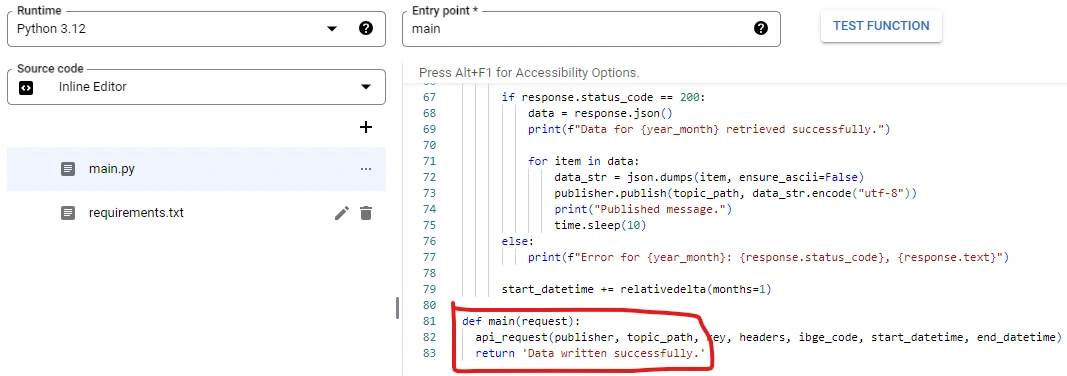
When we send this script to Cloud Functions, it's advised to comment out the "os.environ" section in the script and add a "def main(request):" along with a return statement on it. When creating the function on Cloud Functions, don't forget to insert "main" as the entry point like in the image below:
These are the libraries required in the requirements.txt file:
Now we can deploy our function. After it's been deployed, we can use GCP's CLI to start the function by running the CLI test command given in the "Testing" section.
Processing
Pub/Sub will receive these messages and store them in a topic. When you create a topic, it's nice to create a raw_data_schema for the data arriving to that topic, this way you will guarantee order in the data that's being published to our topic. Don't forget to also create a subscription for the topic.
Dataflow is by far the most complicated part of this project. Before we start creating the Beam pipeline, we have to first create a dataset inside BigQuery, don't worry about defining the table and a schema in the dataset, this will be created inside the Beam script. If you still want to create the table and schema just for quality assertions, here is the bigquery_schema that you can insert as text inside when creating the table.
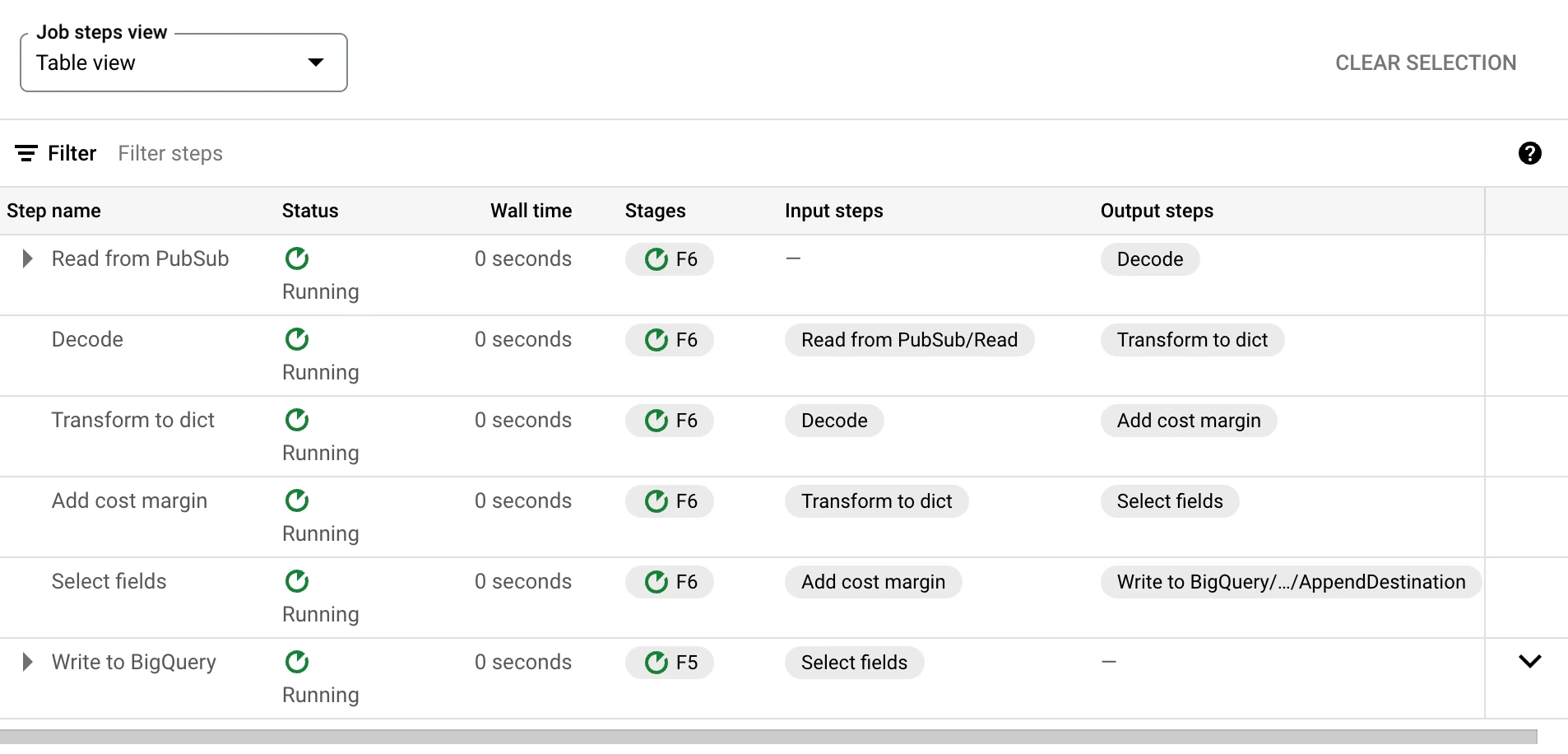
The beam_pipeline script has a toggle (comment out) so you can test your pipeline on your machine or deploy it to the cloud, this works because one has the DataflowRunner declared and the other does not. With that script, we become a subscriber to our Pub/Sub topic, transform the JSON object by adding fields and changing its names and then writing it to BigQuery in tabular format. Make sure to test it first on your local machine before deploying it on the cloud, this one can be quite expensive if you leave it testing indefinitely on Dataflow. Once the script has been deployed and it's showing on the "template" folder inside your GCS bucket, you can create your Dataflow job.
Be patient when deploying to Dataflow, the table might take longer to create in BigQuery when compared to your local testing.
Storage and Serving
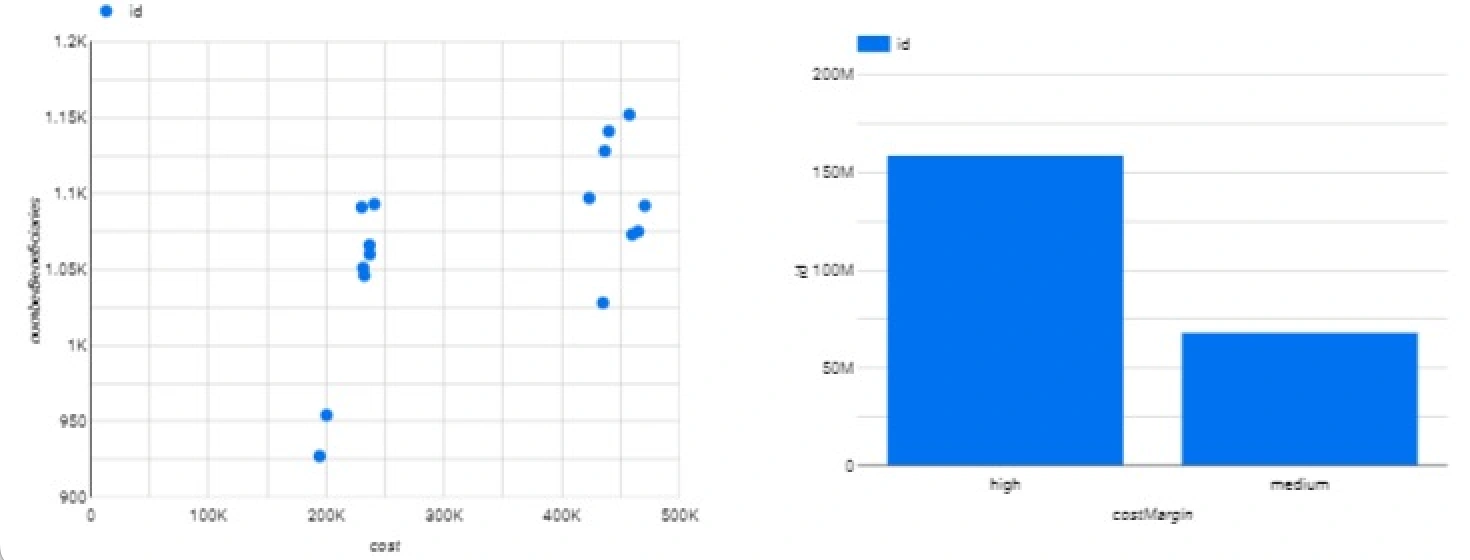
Now that the data has been inserted into BigQuery, we can use Looker to build some dashboards on top of it.
Like this project
Posted Apr 29, 2024
Data Engineering an Analysis for streaming data using Google Cloud Platform's resources like Dataflow, Pub/Sub, Cloud Functions, Looker Studio, and BigQuery.
Likes
0
Views
11
Clients
Rox Partner