Automated Document Recognition (ADR)
Ahsin Shabbir
Background
Automated Document Recognition (ADR) is the application of machine learning artificial intelligence models to understand document content and categories for organization of digital content. Companies in legal, logistics, finance, healthcare, and education can benefit from the use of ADR in their IT infrastructure.
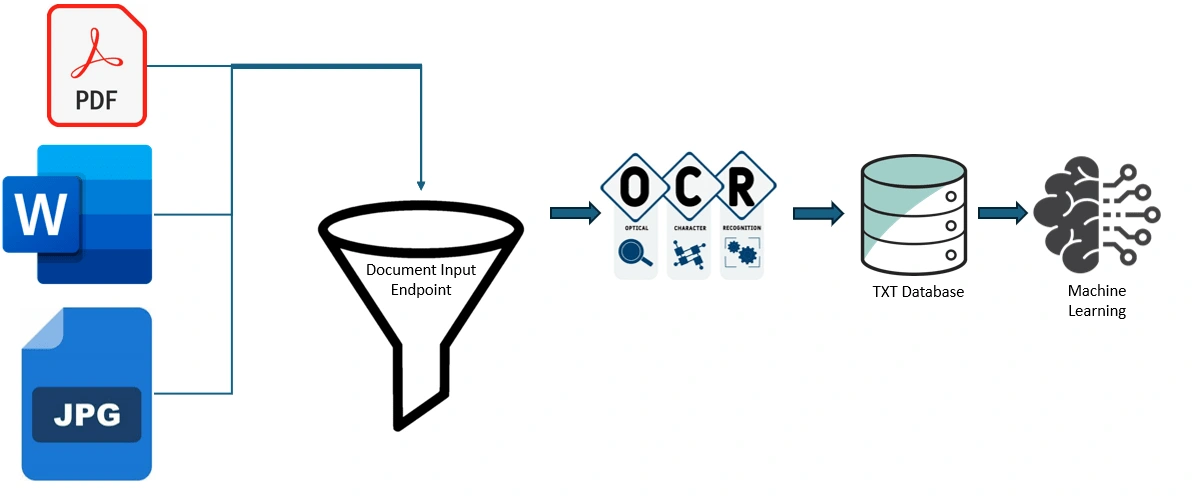
Documents arrive in a variety of formats but the outcome is to extract text using OCR, then use machine learning for categorization of the document.
Solution

Python is used to process documents by running OCR, training a machine learning model, and providing AI based inference as a web service. Deployment is done using Docker and FastAPI webservice to allow for horizontally scalable near real-time use cases. Integration into existing IT infrastructure is streamlined via the internally deployed API.
Need a reliable freelancer with reasonable prices, high quality work, and 100% satisfaction guarantee? Contact me today!
Find me on Linkedin: https://www.linkedin.com/in/ahsinshabbir
Like this project
Posted May 6, 2024
Use Artificial Intelligence to understand document content and categorize new documents for creating organized digital content.
Likes
0
Views
27