Large Language Model AI with Access to Private Enterprise Data
Ahsin Shabbir
Background
Large Language Models (LLMs) use natural language processing to answer queries. ChatGPT is a well-known implementation of an LLM. While LLMs are available to use on the internet, there are certain requirements for enterprises to avoid sharing highly sensitive data with third-parties, and the data must never leave the enterprise's network. Companies that are in the healthcare, defense, financial, and insurance industry deal with sensitive data that requires a deployment of an LLM within their network for answering queries on their data without risk of a data breach.
Objective
I worked with a client in the defense industry that wanted me to deploy an LLM within their network and setup an API that is used throughout the company for employees to query proprietary company data.
Project Requirements
The LLM must not access the internet
The LLM must only be accessible to non-admin users through an API
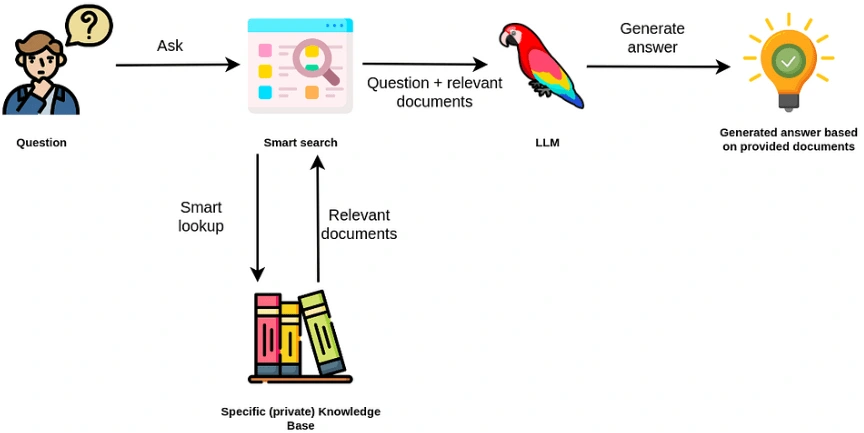
The LLM must perform retrieval augmented generation (RAG) so that it can answer queries using proprietary enterprise data
The solution must allow non-technical employees to switch to a more powerful LLM if it becomes available in the future
The LLM must automatically scale up and down based on the usage
Solution

Technologies Used / Architecture
Load Content into Vector Database
The client did not have a vector database provisioned so I started by deploying Weaviate on Kubernetes. I then worked with the client to source their proprietary data and load it into Weaviate as vectors. I wrote a python script that can perform the entire ETL process of ingesting the documents and loading them as vectors.
Deploy LLM
I used the mistral 7x8 model which at the time is the most efficient and accurate open source model. After downloading the model file, I deployed it as a Docker service on top of Kubernetes. I setup the Kubernetes deployment definition to automatically scale the number of containers for the model based on CPU utilization.
Create API
I used FastAPI and Python to create an API that is deployed as a Docker container on Kubernetes with auto-scaling enabled. The API is available within the client's network and employees can access it by visiting a website deployed internally or by sending requests programmatically using PostMan or similar tool. The API service has access to the LLM service running in the same Kubernetes cluster, but only admins can access the LLM service directly. This ensures that all queries being submitted by employees go through the API and there is a robust audit trail of user's queries and the response from the LLM.
Perform Retrieval Augmented Generation
RAG is needed to power the LLM with the company's private data so it can better answer employee's queries. I setup the LLM inference to first turn the employee's query into a vector, then use the vector to query the Weaviate database to retrieve documents that have the highest similarity in vector space using cosine similarity distance measure, and fed this information into the LLM's prompt before returning the generated response to the user.
Conclusion
The client's employees are able to retrieve relevant information much faster using natural language queries in an interactive manner, improving productivity by an order of magnitude. The process prior to the implementation of an LLM with RAG was heavily manual, crawling through dozens of SharePoint sites to find a simple requirements document. After I completed the project, the client's employees are very satisfied with the speed and accuracy of the retrieved information. The project is deployed with automatic scaling enabled, and the client can swap the LLM being used and use a more powerful LLM in the future if one gets developed. The ETL script that I wrote with Python is being used to feed updated content into Weaviate, which is improving the system over time.
Need a reliable freelancer with reasonable prices, high quality work, and 100% satisfaction guarantee? Contact me today!
Find me on Linkedin: https://www.linkedin.com/in/ahsinshabbir
Like this project
Posted Apr 11, 2024
I deployed a Large Language Model AI that can fetch information from private enterprise data and answer employee's queries with high accuracy