Integration & Automation Hub
Waleed Ashraf Usmani
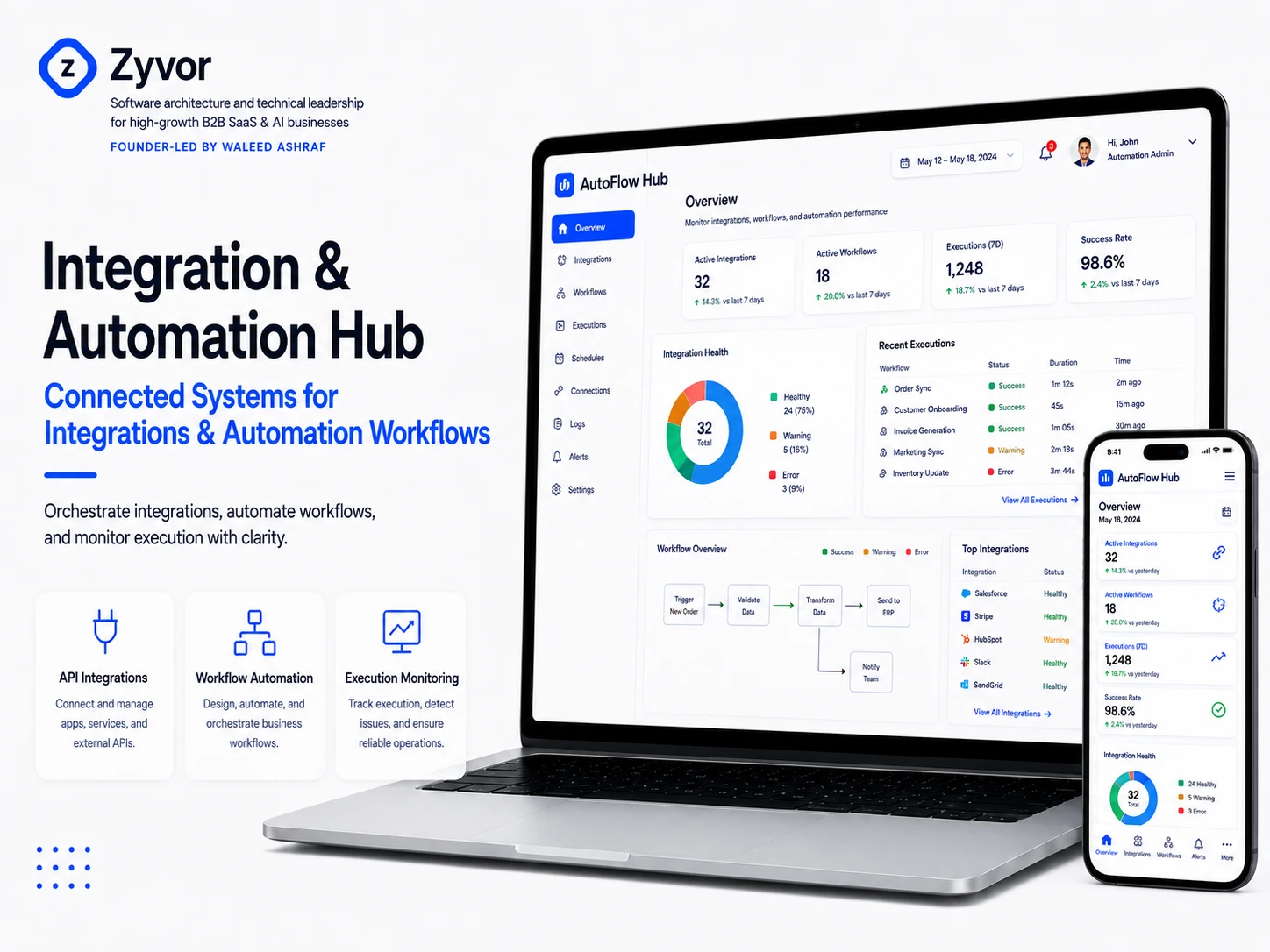
Integration & Automation Hub
The Problem
A mid-market SaaS company running 14 third-party integrations was spending more engineering time maintaining API connections than building product features. Every integration was custom-built, undocumented, and owned by whoever happened to write it. When something broke (and it broke weekly), debugging was archaeology.
14 integrations built over 3 years by 6 different engineers. No shared patterns, no documentation, no error handling standards. Each integration was a snowflake
Webhook processing was synchronous. A slow downstream API would block the entire webhook queue, causing cascading delays across unrelated integrations. One Salesforce API slowdown took down Stripe payment webhooks for 4 hours
Retry logic was inconsistent. Some integrations retried on failure, some didn't. Some retried infinitely, hammering rate-limited APIs until they got IP-banned. The Shopify integration was banned twice in 6 months
No monitoring or alerting. Integration failures were discovered when customers reported missing data, sometimes days after the failure occurred. Average time-to-detection for a silent integration failure: 3.2 days
Data transformation between systems was hardcoded. When a third-party API changed its response format, the integration broke silently and corrupted downstream data until someone noticed
Engineering spent 18+ hours per week on integration maintenance: debugging failures, handling API changes, responding to customer reports of missing data, and manually replaying failed events
The integrations were supposed to make the product more valuable. Instead, they were the product's biggest liability.
The Approach
I built a centralized integration and automation platform that standardizes how every external system connects, processes data, handles failures, and reports health. Every integration follows the same patterns, uses the same retry logic, and reports to the same monitoring dashboard.
Unified Integration Framework
One pattern for every integration. No more snowflakes.
✅ Standardized connector architecture with shared authentication management, request/response logging, and error classification for every third-party API
✅ Declarative integration configuration: new integrations defined via schema (endpoints, auth method, data mapping, retry policy) rather than custom code
✅ Versioned API adapters that isolate third-party API changes to a single adapter layer without touching business logic
📊 Outcome: New integration development time dropped from 3-4 weeks to 3-5 days. 14 snowflake integrations consolidated into a single framework. Engineering maintenance time reduced from 18+ hours/week to under 4
Async Webhook Processing with Isolation
One slow API never takes down another integration again.
✅ Queue-per-integration architecture: each integration's webhooks process independently. A Salesforce slowdown affects only Salesforce, not Stripe or Shopify
✅ Configurable concurrency limits per integration preventing any single connector from consuming all processing capacity
✅ Dead letter queues capturing failed events with full request/response context for debugging and manual replay
📊 Outcome: Cross-integration cascading failures eliminated. Webhook processing latency dropped from variable (30 seconds to 4+ hours during incidents) to consistent sub-5-second processing
Intelligent Retry Engine
Smart retries that respect rate limits and know when to stop.
✅ Exponential backoff with jitter, configurable per integration based on the third-party API's rate limit documentation
✅ Circuit breaker pattern: after N consecutive failures, the integration pauses and alerts instead of hammering a down API
✅ Rate limit awareness: integrations automatically throttle when approaching documented rate limits, preventing IP bans
📊 Outcome: API rate limit violations dropped to zero (from 2 IP bans in 6 months). Failed event recovery rate improved from 40% to 97% through intelligent retry strategies
Real-Time Monitoring and Alerting
Know about failures in minutes, not days.
✅ Integration health dashboard showing success rates, latency, error rates, and queue depth per connector in real time
✅ Anomaly detection alerting on unusual error spikes, latency increases, or throughput drops within 5 minutes of onset
✅ Failure classification: transient errors (retry automatically), permanent errors (alert immediately), and data format errors (quarantine and alert)
📊 Outcome: Time-to-detection for integration failures dropped from 3.2 days to under 5 minutes. Silent data corruption incidents eliminated through format validation and quarantine
Visual Workflow Automation
Connect integrations into multi-step workflows without writing code.
✅ Drag-and-drop workflow builder: trigger on event from System A → transform data → push to System B → notify on success/failure
✅ Conditional branching: route events differently based on data content (e.g., high-value orders go to Salesforce AND Slack, standard orders go to Salesforce only)
✅ Workflow versioning with rollback: test new automation logic on a subset of events before applying to all traffic
📊 Outcome: Operations team building their own automation workflows without engineering involvement. 8 custom workflows created in the first month, eliminating 12 hours/week of manual data transfer tasks
Architecture Decisions
Why I chose this stack and what tradeoffs I made.
SQS with per-integration queues over a shared queue — Integration isolation is the core architectural requirement. Separate SQS queues per connector ensure one integration's problems never affect another. Tradeoff: more queues to manage, but AWS handles queue infrastructure. The isolation guarantee is worth the operational overhead
Redis for circuit breaker state and rate limit tracking — Circuit breaker decisions and rate limit counters need sub-millisecond reads on every API call. Redis stores per-integration circuit state, failure counts, and rate limit windows. PostgreSQL stores the durable event log
PostgreSQL for event sourcing — Every webhook received, every transformation applied, and every outbound API call logged as immutable events. Full replay capability for any integration from any point in time. Essential for debugging and data recovery
Docker with isolated containers per integration — Each integration runs in its own container with independent resource limits. A memory leak in one connector can't affect others. Container restarts are automatic and isolated
The Results
Timeframe | What Happened |
|---|---|
Week 1 | Framework deployed. First 4 integrations migrated from snowflake code to standardized connectors. Monitoring dashboard live |
Week 3 | All 14 integrations migrated. Queue isolation eliminated cascading failures. Intelligent retry engine preventing rate limit violations |
Month 1 | Time-to-detection for failures dropped from 3.2 days to under 5 minutes. Engineering maintenance time reduced from 18+ hours/week to under 4 |
Month 2 | Operations team created 8 custom workflows without engineering. 12 hours/week of manual data transfer eliminated. Failed event recovery rate at 97% |
Month 5 | Platform processing 120K+ events/day across 14 integrations. Zero IP bans. Zero cascading failures. Zero silent data corruption incidents since launch |
Like this project
Posted May 16, 2026
API orchestration platform built with centralized integrations, webhook processing, retry queues, workflow automation, failure alerts, and monitoring for reliable connected business operations.
Likes
0
Views
5
Timeline
Jul 1, 2024 - Oct 31, 2024
Clients
Sarwar Group