Creating a Dimensional Model (Star Schema) in Databricks
Andreas Watts
Creating a Dimensional Model (Star Schema) in Databricks
For this project I built a dimensional model on car sales data using PySpark and Databricks.
Tech Stack: Azure Cloud, Azure SQL Server, Azure Data Factory, Databricks,
Python (PySpark, Pandas)
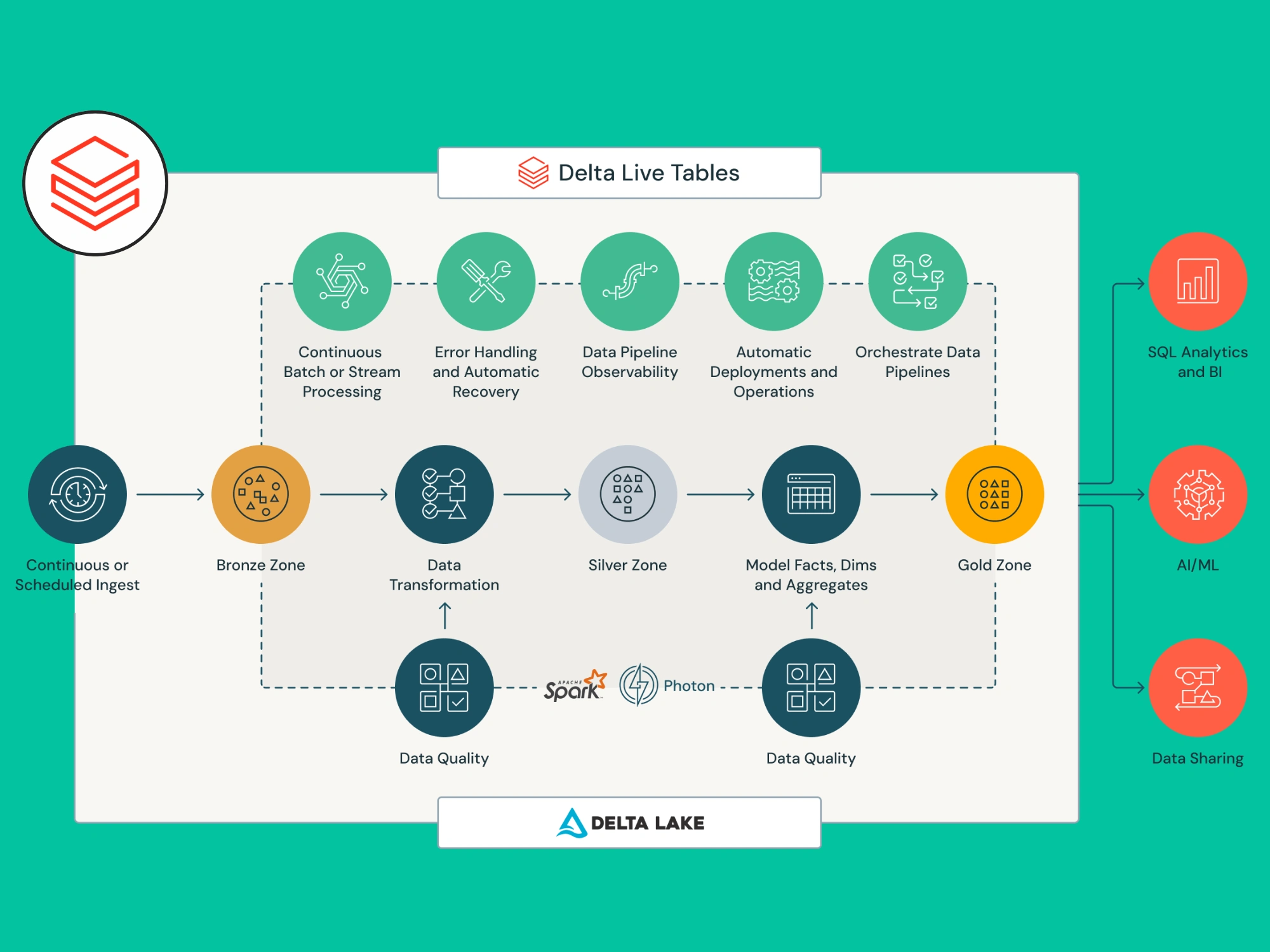
Project Architecture
Data is extracted from an Azure cloud SQL server using Azure Data Factory to Azure Data Lake Gen2 and saved as Parquet files. The data is then transformed within Databricks and then modelled into a star schema consisting of a fact table and multiple dimensions.
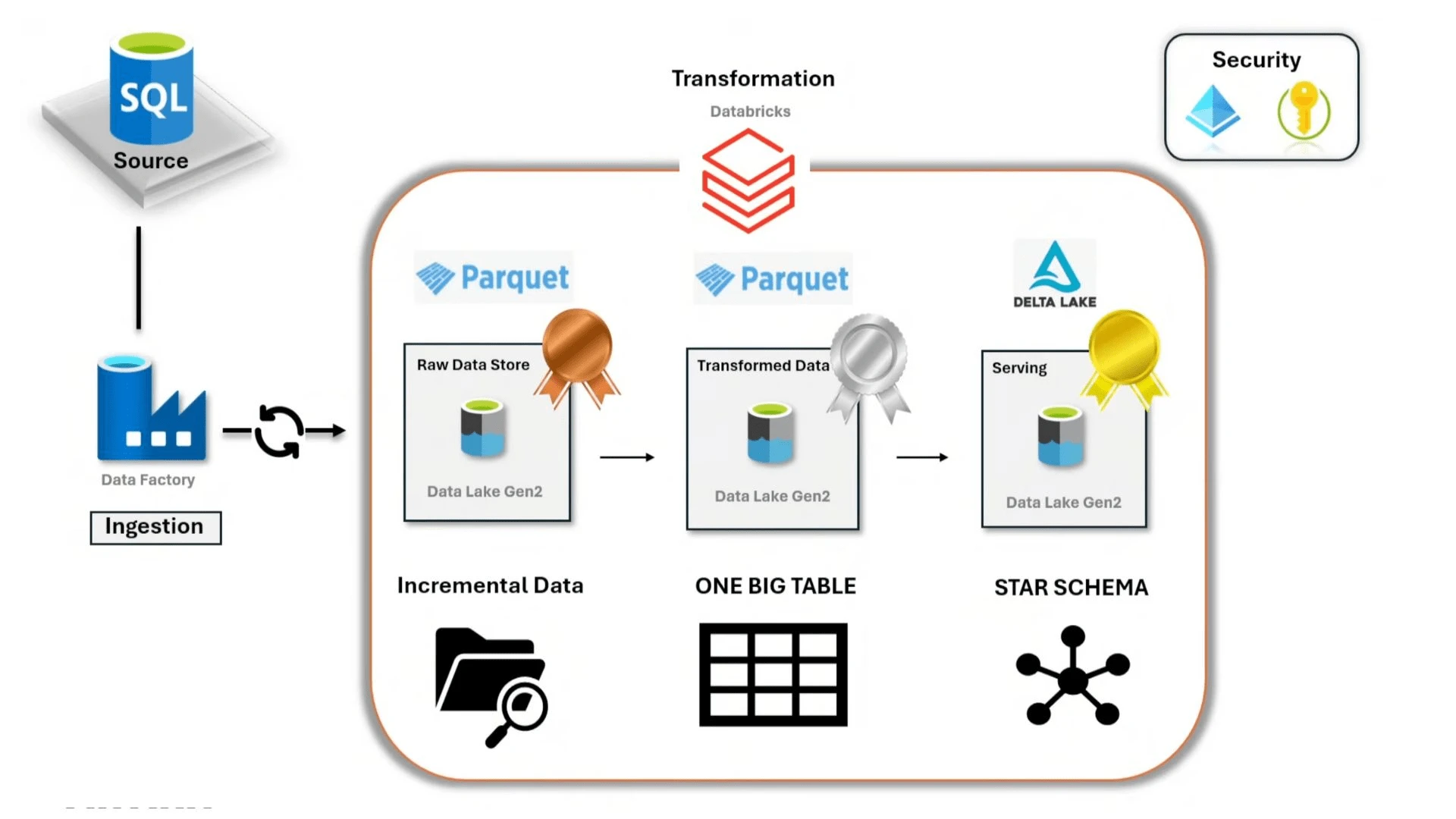
The final result is the following star schema:

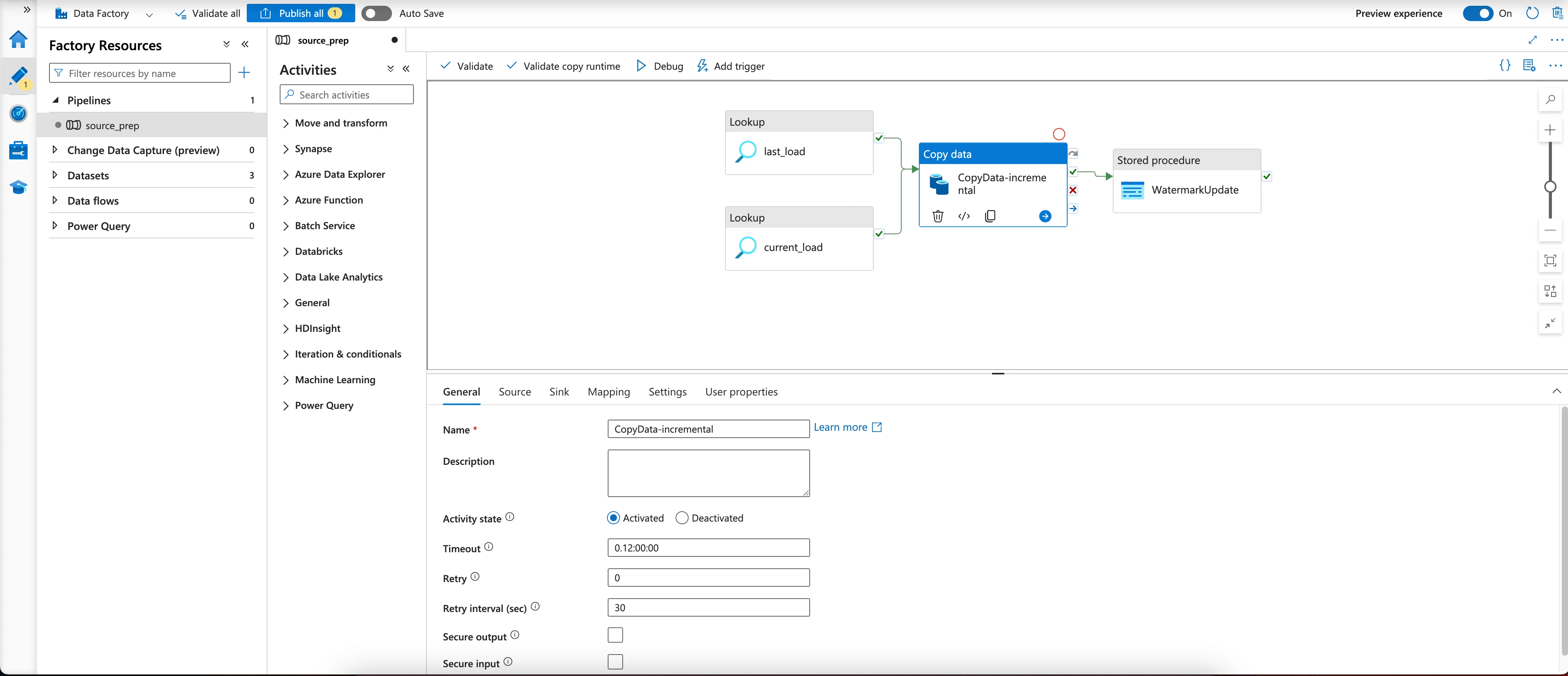
ETL
Extracting the data from the SQL server to the Data Lake was done with Azure Data Factory.
Notebooks
Sample images from the data notebooks:
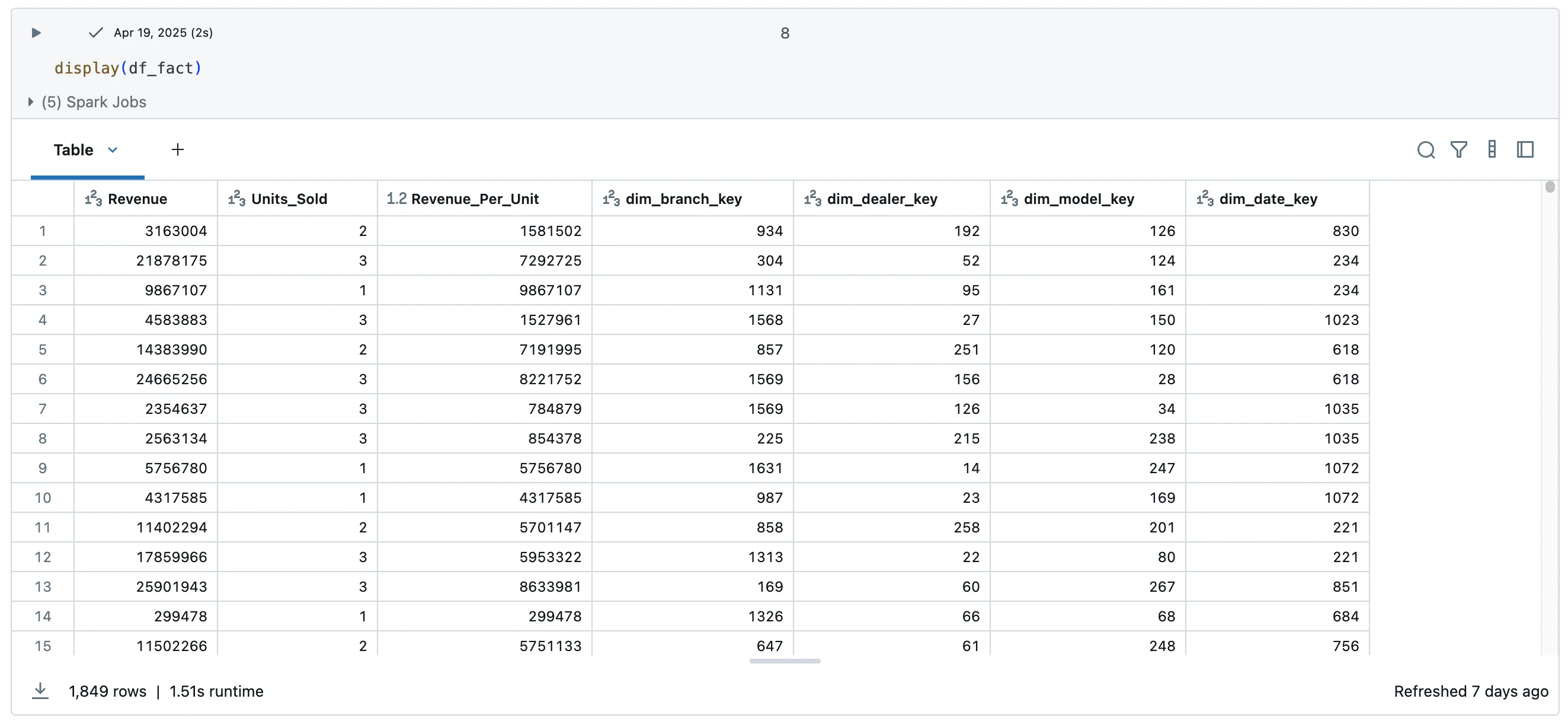
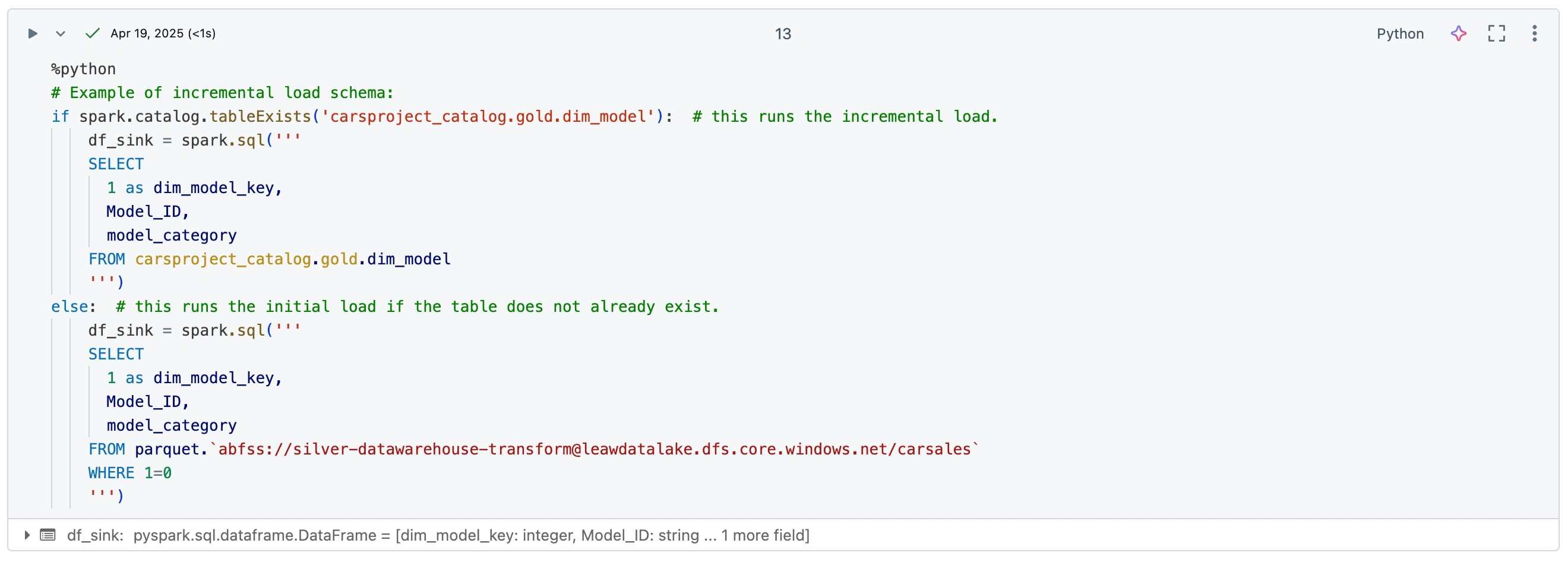
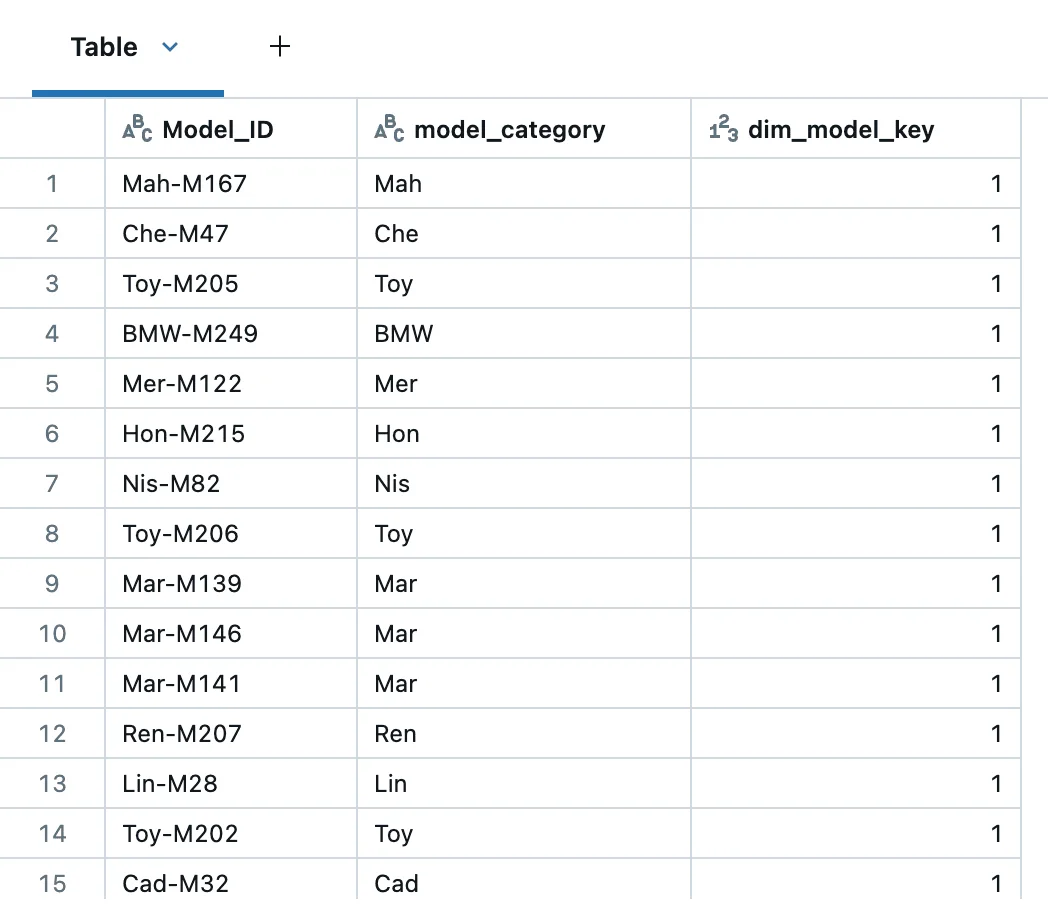
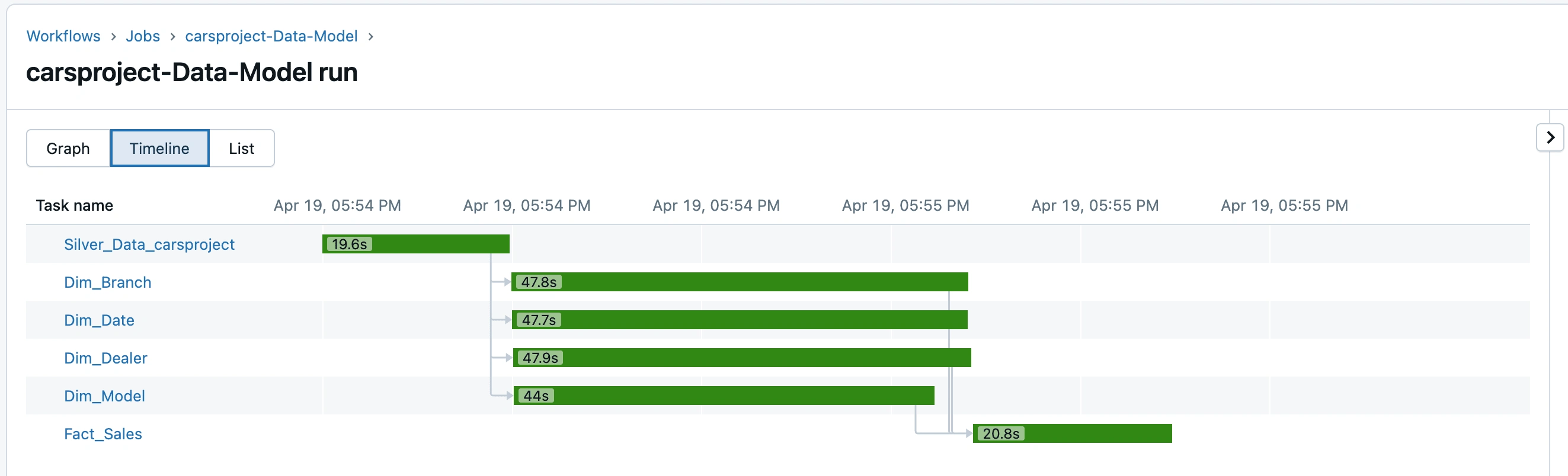
Workflow
Sample images of the workflow in Databricks:
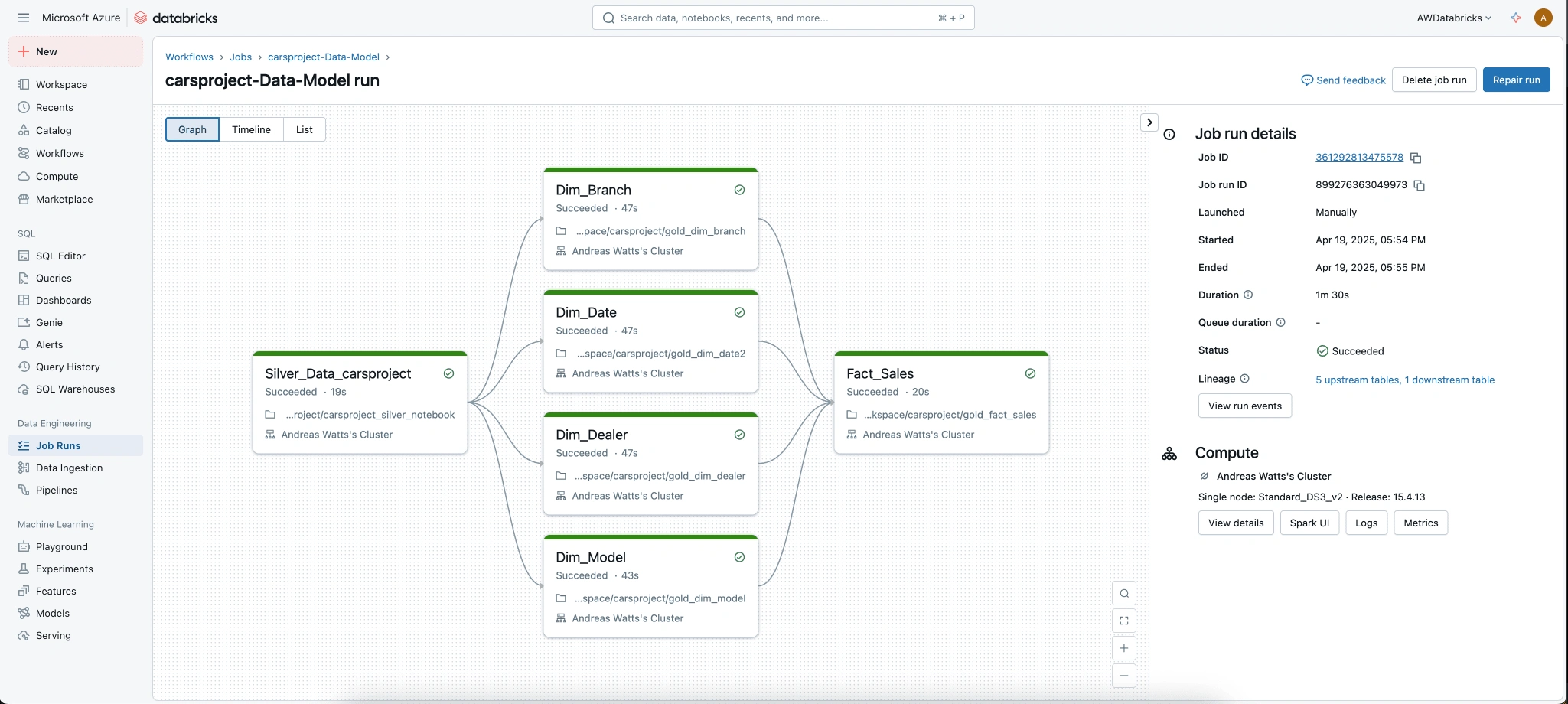
Like this project
Posted Apr 27, 2025
Built a dimensional model using PySpark in Databricks. Key concepts: Dimensional modelling, Kimball, star-schema.