Data Engineering with Music Metadata: From API to Graph Insights
Diana O
End-to-End Data Engineering with Music Metadata: From API to Graph Insights
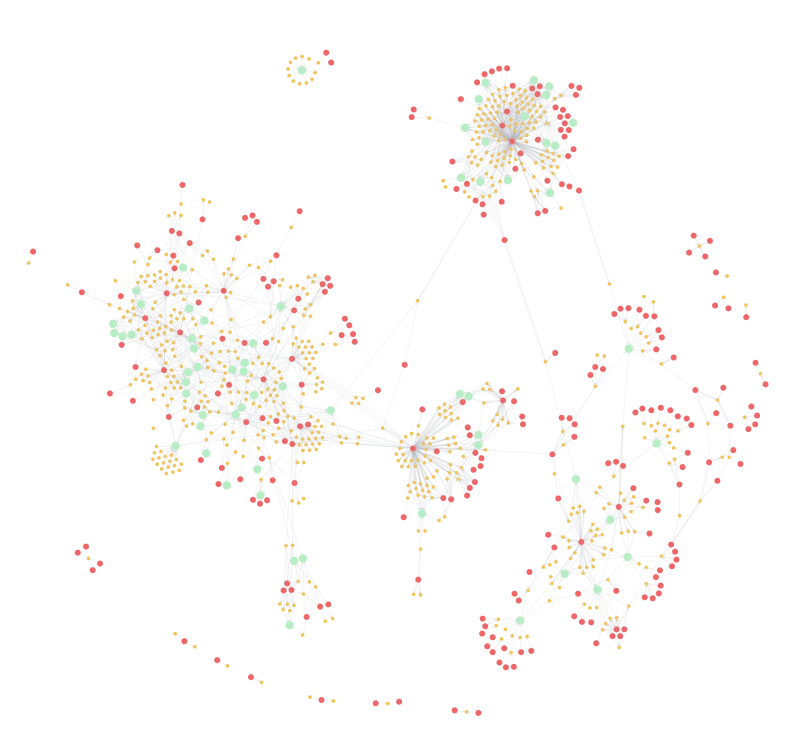
The Music Catalog Extractor is a Python-based ETL (Extract, Transform, Load) pipeline designed to transform complex, open music metadata from the MusicBrainz API into structured, queryable formats. It extracts detailed information on artists, recordings, releases, and contributors, then cleans and organizes the data into a normalized relational schema using SQLite and a graph-based model in Neo4j. This project applies core data engineering principles to turn semi-structured metadata into insight-ready datasets suitable for analysis, visualization, and integration into downstream applications.
Navigating Complexity: Understanding the MusicBrainz API
A core challenge of the project lay in interpreting and navigating the extensive MusicBrainz API documentation. The API provides a wide range of deeply nested and interrelated data, covering artists, recordings, releases, and credits. Identifying which endpoints to query, how to handle pagination, and how to extract meaningful relationships required careful study and planning.
This early research phase was important so that I can develop a strategy that focused on extracting:
Core artist metadata (including name, aliases, gender, date of birth, begin area)
Release-level detail (formats, labels, date of release, associated artist)
Recording-level (title, genres, collaborators such as composers, lyricists, producers, other performers etc.)
Relationships between artist, release, recordings and collaborators
Robust API Integration
To efficiently extract large volumes of data from the MusicBrainz API, I implemented:
Pagination logic to manage API limits and ensure complete coverage.
Rate limiting and retry mechanisms to comply with API usage policies and gracefully handle transient failures.
Caching strategies to reduce redundant calls and optimize performance during repeated or resumed runs.
These features ensure the pipeline is reliable and production-ready, even when working with public APIs that may be rate-constrained or intermittently unavailable.
Schema Design and Dual Database Modeling
A significant portion of the project was devoted to designing an effective schema and mapping complex music metadata into usable structures. I employed a dual-model approach:
Relational Storage with SQLite
The pipeline first stages data in SQLite using normalized tables. Key entities include:
Artists: With identifiers, names, types, genders, and aliases
Recordings: Capturing individual tracks and associated metadata
Releases: Representing albums linked to artists and labels
Contributors: Including composers, lyricists, and producers
Graph Modeling with Neo4j
To support deeper exploration of relationships, data is also transformed and imported into a Neo4j graph database. Here, nodes represent entities such as artists, recordings, and contributors, while relationships capture interactions like:
(Artist)-[:PERFORMED]->(Recording)
(Contributor)-[:COMPOSED]->(Recording)
(Recording)-[:APPEARS_ON]->(Release)
This graph-based model enables advanced querying and insight generation that would be difficult or inefficient with traditional relational databases. For example, it supports questions like:
“Find songs released in the 1990s that were composed by female artists”
“Show all collaborations between Artist A and Artist B across shared recordings or releases”
“Identify the most frequent artistic collaborators of Artist A”
Scalable and Resilient Batch Processing
To support large-scale ingestion, the system includes configurable batch parameters (e.g., --batch-size, --max-artists) and uses a progress-tracking mechanism to record the state of each run. This enables:
Checkpointing: Allowing interrupted runs to resume without data loss.
Memory efficiency: Preventing overload during long-running operations.
Scalability: Supporting thousands of artists and recordings without manual intervention.
Like this project
Posted May 14, 2025
A Python ETL pipeline designed to transform complex, semi-structured music metadata from MusicBrainz API into a relational schema (SQLite) and Neo4j graph model
Likes
0
Views
14
Timeline
Apr 1, 2025 - Apr 30, 2025