Book Catalog Web Scraper
Ciro
Case Study: Book Catalog Web Scraper
Overview
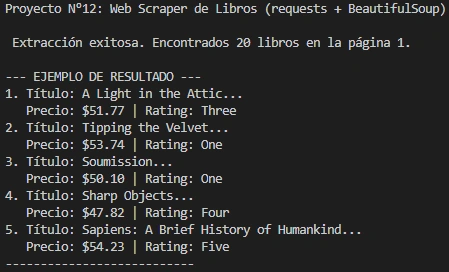
Developed a Python‑based web scraper to extract structured data (titles, prices, ratings) from a public book catalog. The project demonstrates expertise in HTTP requests, HTML parsing, and data extraction using CSS selectors.
Challenge
Websites often present information in unstructured formats without APIs, making it difficult to collect and analyze data. The challenge was to design a scraper that could reliably extract book details while handling errors and missing data.
Approach
Connectivity: Used requests with custom headers to simulate browser behavior and avoid blocking.
Parsing: Applied BeautifulSoup to navigate the DOM and locate book elements.
Selectors: Leveraged CSS selectors to accurately extract titles, prices, and ratings.
Robustness: Implemented error handling (raise_for_status, try/except) to ensure stable execution.
Solution
Delivered a modular Python script that converts raw HTML into structured Python dictionaries. The scraper outputs clean, reusable datasets ready for analysis or integration into larger pipelines.
Impact
Enabled structured extraction of catalog data without relying on an API.
Demonstrated best practices in error handling and ethical scraping.
Showcased ability to transform unstructured web content into actionable datasets.
Reflection
This project highlights proficiency in Python, web scraping techniques, and data structuring. It reinforces the ability to design robust scripts that respect server constraints while delivering reliable insights.
Like this project
Posted Jan 2, 2026
Built a Python web scraper with requests and BeautifulSoup to extract book titles, prices, and ratings.
Likes
1
Views
3