Fine-Tuning Llama-2 for Domain-specific Question Answering
Ibrahim Abedrabbo
Side Project
Brief
This project employs the Llama-2 model with 7B parameters and fine-tunes it for question-answering tasks using two different datasets: a collection of physics books and a scientific paper. The models successfully learned the new knowledge domains and provided representative answers to prompts.
Fine-tuning the Large Language Model (LLM) Llama-2 is split into two main phases:
Self-supervised learning (pre-training). In this step, the model is trained on the text corpus in a causal learning fashion (CLM) to adapt to the text domain.
Supervised learning (fine-tuning). Use the trained model from the previous phase to fine-tune the wanted task. In this project, the task is question-answering.
Dataset
Two types of datasets were obtained for the two phases mentioned in the previous section.
For the self-supervised learning phase, a collection of physics books is used for the first model. For the second model, a recent scientific paper was used. The text was extracted and split into chunks using the LangChain library.
For the supervised learning phase, for each domain (physics domain and the scientific paper domain, separately) a collection of questions and answers was generated using the Llama2-7b-chat LLM in an automated script. To generate questions and answers, the script takes a chunk from the domain text, augments it in a special prompt, and inputs it to the model. Then, all the returned Q&As output from the LLM are split into input and target (question and answer).
Training
The pipeline is as follows for each domain:
train the self-supervised model with the text chunks.
use the trained model from the previous phase and fine-tune the supervised model with the question-and-answer dataset
Parameter-efficient techniques (PEFT) and QLoRA were used to reduce the trainable parameters. Instead of training the full model with 7 billion parameters, a large chunk of the network is frozen, while training only the adapters parameters which consist of only about 34 million trainable parameters.
Results
Following are the perplexity values for training in the first phase. Perplexity is used to evaluate pre-trained models trained in a causal learning fashion.
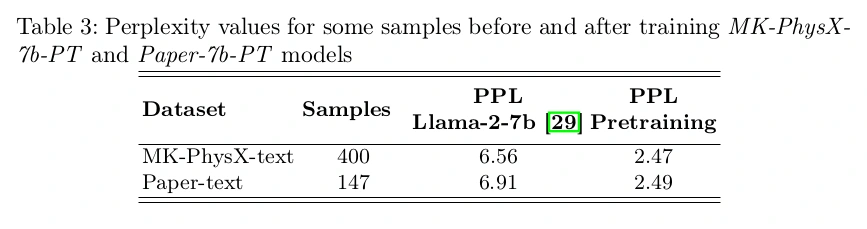
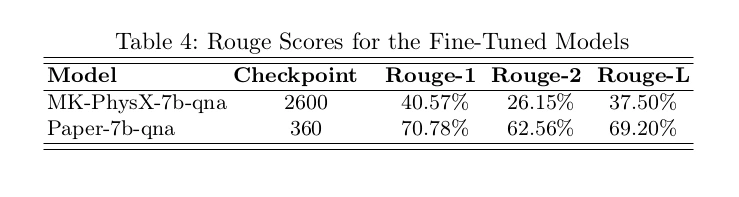
For evaluating the generated answer’s quality the Rouge metric is used. It quantifies the output against the reference ground truth.
Like this project
Posted Sep 8, 2024
In this project, I start with the Llama-2 model with 7B parameters and fine-tune it for question-answering tasks on two new domains.
Likes
0
Views
70



