Optimizing Neural Network via Model Structural Pruning - PyTorch
Ibrahim Abedrabbo
Side Project
Brief
In this project, the main goal was to provide an experimental proof of structural model pruning for optimizing neural networks, resulting in higher inference FPS.
The structural pruning technique from an open-source project was employed to prune the SwinTransformer-tiny model for classification on a subset of the ImageNet-1k dataset.
The inference time was decreased by up to 45% compared to the original model while maintaining the accuracy of the original, un-pruned, model.
Pruning & Training
The solution involves the following steps:
Training the base vanilla model on the dataset.
Apply structural pruning.
Fine-tuning the pruned model on the same dataset.
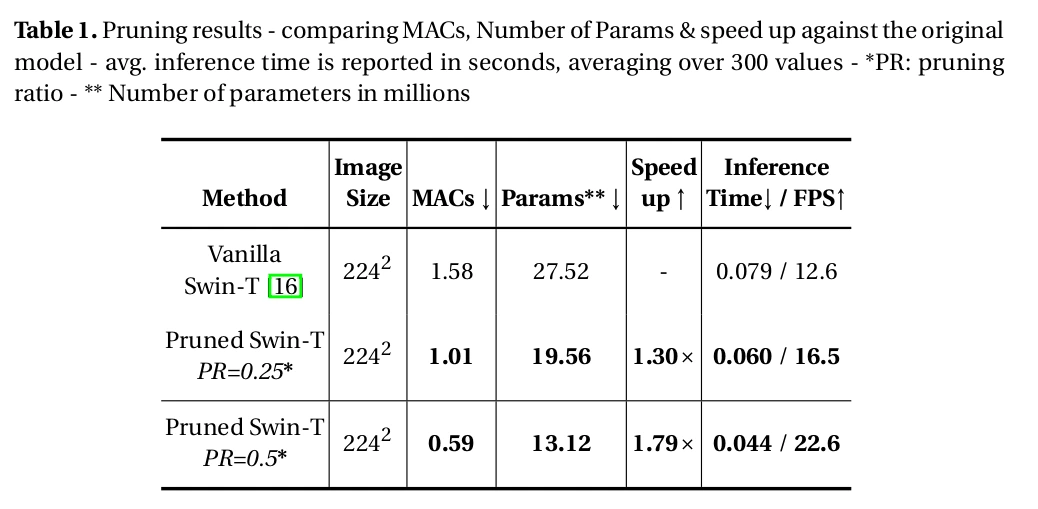
Model Pruning Results
The following table demonstrates the results of pruning the original model. Two different pruning configurations were applied to the vanilla model. The number of trained parameters dropped significantly for both the pruned models. Also, inference speed was increased by ~23% for the first model, and ~44% for the second model.
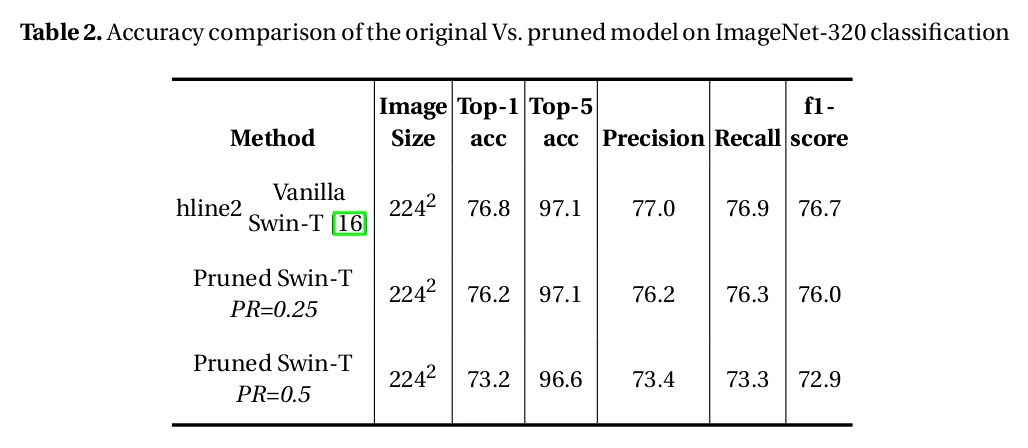
Accuracy Comparison
Pruning retains competitive performance across various evaluation metrics. The following table demonstrates the effectiveness of the pruning technique.
Like this project
Posted Sep 8, 2024
Optimizing neural networks via model pruning. The project highlights the efficiency of model pruning in increasing inference speed while retaining accuracy.
Likes
0
Views
26



