Debugging mysterious traffic from Boardman, OR
Gajus Kuizinas
This was a fun and a long journey with somewhat unexpected learnings and outcomes that are worth documenting.
It all started with an accidental observation that almost half of our traffic is coming from Boardman, OR.
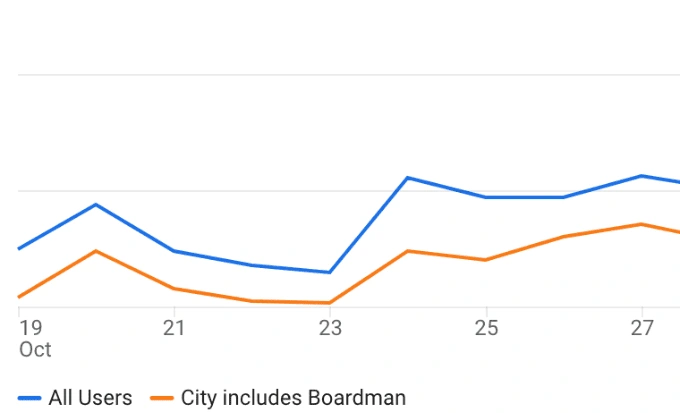
Boardman accounts for a significant portion of traffic.
A quick Google search revealed that Boardman, OR hosts a large AWS data center. Turns out that because Boardman has access to electricity from hydropower, it is cheaper than other data centers and is therefore preferred by many.

Furthermore, if you search for related keywords ("boardman AWS google analytics") a few articles surface (such as this one) that speculate that traffic coming from Boardman is automated bot traffic and suggests just filtering it out.
At this point, we didn't suspect anything malicious, and we could have easily just filtered out this traffic in Google Analytics. But it didn't feel right to just block the entire city without knowing what is going on. We hypothesized that this traffic is coming from:
someone scraping our website
one of our external services misconfigured (e.g. liveness checks)
large centralization of VPN hosting providers
The last one was the primary reason I was hesitant to just block all the traffic from Boardman. We needed to know the root cause before making the decision...
Identifying the URLs accessed
Our load balancer logs do not include geo location, which made it hard to identify what URLs are being accessed. I wanted to know if there is a pattern or if URLs are random. The way we eventually did it is by looking at Google Analytics Realtime dashboard and filtering by "Boardman" city.
This is where we learned the first interesting insight: the only URLs being accessed are people profiles. Even more surprisingly, the only profiles being accessed are for test accounts. (A topic for another post, but we run all integration tests against production environment.) And even more surprisingly, even though profiles being accessed were test accounts, the URL is a production URL.
The fact that URLs being accessed are for test profiles was surprising, because these URLs are not public. This meant that unlike whatever we thought earlier, these tests are triggered by our infrastructure. The next step is to figure out where these requests originate from.
Analyzing the HTTP requests
Now that we knew which URLs are being accessed, we can look at the load balancer logs to better understand what is happening. Specifically, I was hoping HTTP headers or IP will reveal the initiator.
Here are the headers of one of the HTTP requests:
These requests were coming from many different IPs, but all from the same range.
Few things caught my eye:
user-agent indicates a super old Chrome version (Chrome/64)
The IP from which the request originates indeed belongs to AWS
I should now mention that we do not host anything on AWS. And yet, every time we ran tests, they triggered requests against our services originating from AWS. Following this revelation, my new theory was that one our service integrations (Intercom, customer.io, ...) is triggering these requests, but we needed a way to confirm that.
Blocking the origin
First, we tried to identify which service could be causing these requests by making them make a request to a request bin and comparing HTTP headers and IP address. However, all that this did was confirmed that none of the services that we suspect are the perpetrators.
Failing that, we decided to block all traffic that comes with HTTP headers "Chrome/64" and see what breaks.
Nothing broke.
My actual reaction after blocking the traffic did not break anything.
At this point, we knew that requests are initiated by something in our test pipeline, but blocking those tests did not break anything. My theory was that something that we do in our tests must trigger a webhook (or another background action) that we are not detecting. However, how do you even start debugging that?
I decided to take a step back and think about how to isolate the trigger. After all, we knew it is coming from tests.
Identifying the trigger
I looked again at all the URLs that are being accessed. They were all for newly created test accounts. Looking at each account, they all had a common theme – they were all testing payments. After a bit of digging in the CI logs, the pattern started to emerge – all tests that trigger these requests test Stripe integration...
That's it folks. It was Stripe. Turns out, every time we create a test user in Stripe, for whatever reason, Stripe attempts to scrape the website associated with the user's profile. Annoyingly, blocking these requests did not surface any error – it seems that whatever that Stripe is scraping is non-essential.
Learnings
We never suspected this to be anything malicious. It was an exercise out of curiosity and working as a team. However, along the way we learned about...
An oversight in our integration tests
Gaps in our logging infrastructure
Features of our firewall
Missing documentation
Another takeaway is that whenever designing any services that scrape data from other websites, it is important to include headers that allow to identify them. If Stripe requests included a header that identifies that these requests originate from Stripe, this would not have been such a long exercise.
Thank you to the entire team for taking part in this fun exercise!
Like this project
Posted Nov 16, 2022
A journey of debugging mysterious traffic spikes coming from Boardman, OR.




