Data-Labeling Application UX/UI Enhancement
Serena Sabuda
Infinitypool
UX RESEARCH - UI DESIGN - STYLE GUIDES - ITERATIVE DESIGN
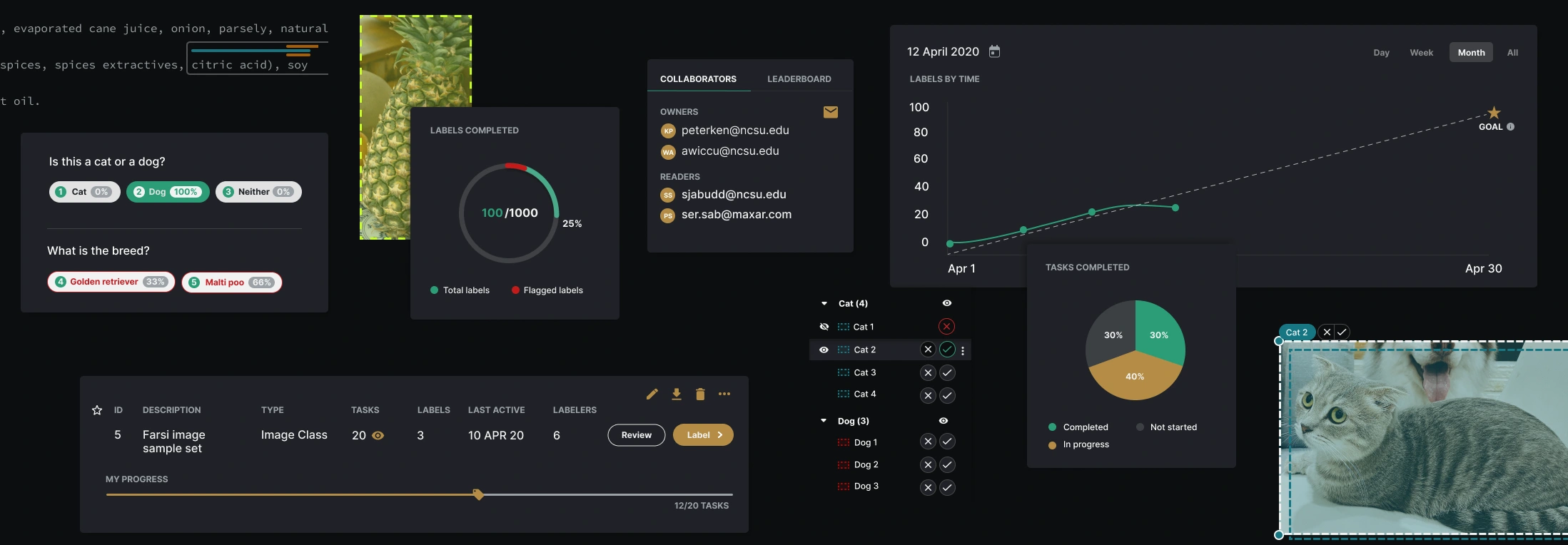
From 2020 to 2021, I worked on a data labeling application designed for rapid and collaborative labeling to support supervised machine learning projects. I delved into every aspect of the design process multiple times in order to support several fully-functioning, complex data-labeling features like: computer vision, text translation, natural language processing and text annotation, and image, text, video, and audio classification.
Infinitypool’s original data-labeling experience was laborious and inefficient for all users involved. The lack of data-labeling models also made it primitive relative to competitors.
We conducted numerous user interviews and identified four primary user groups to design for. Each user had varying levels of technical skills and different use cases. Some users would use the application for labeling, while others would monitor the labelers or upload their own data for labeling.
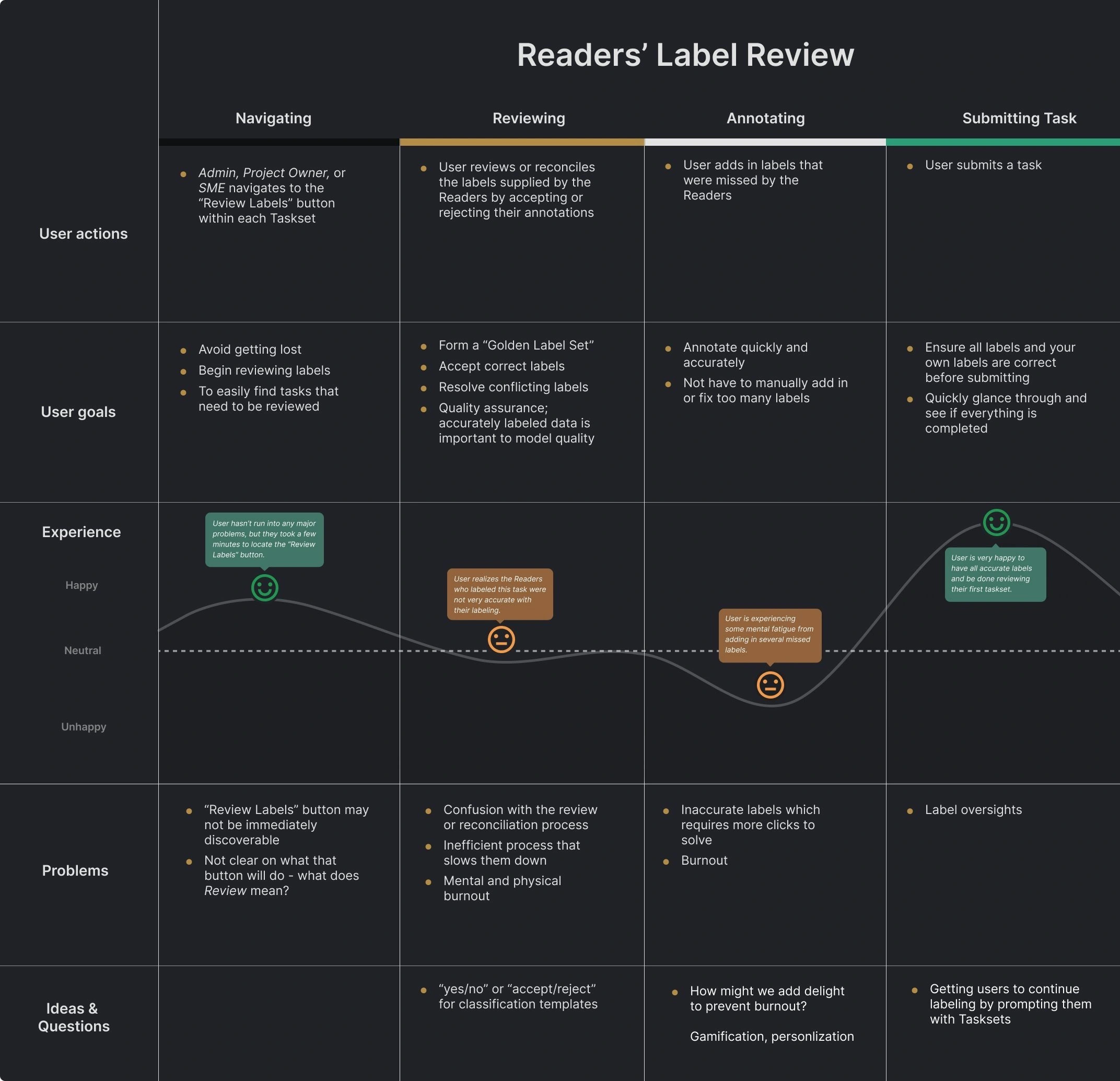
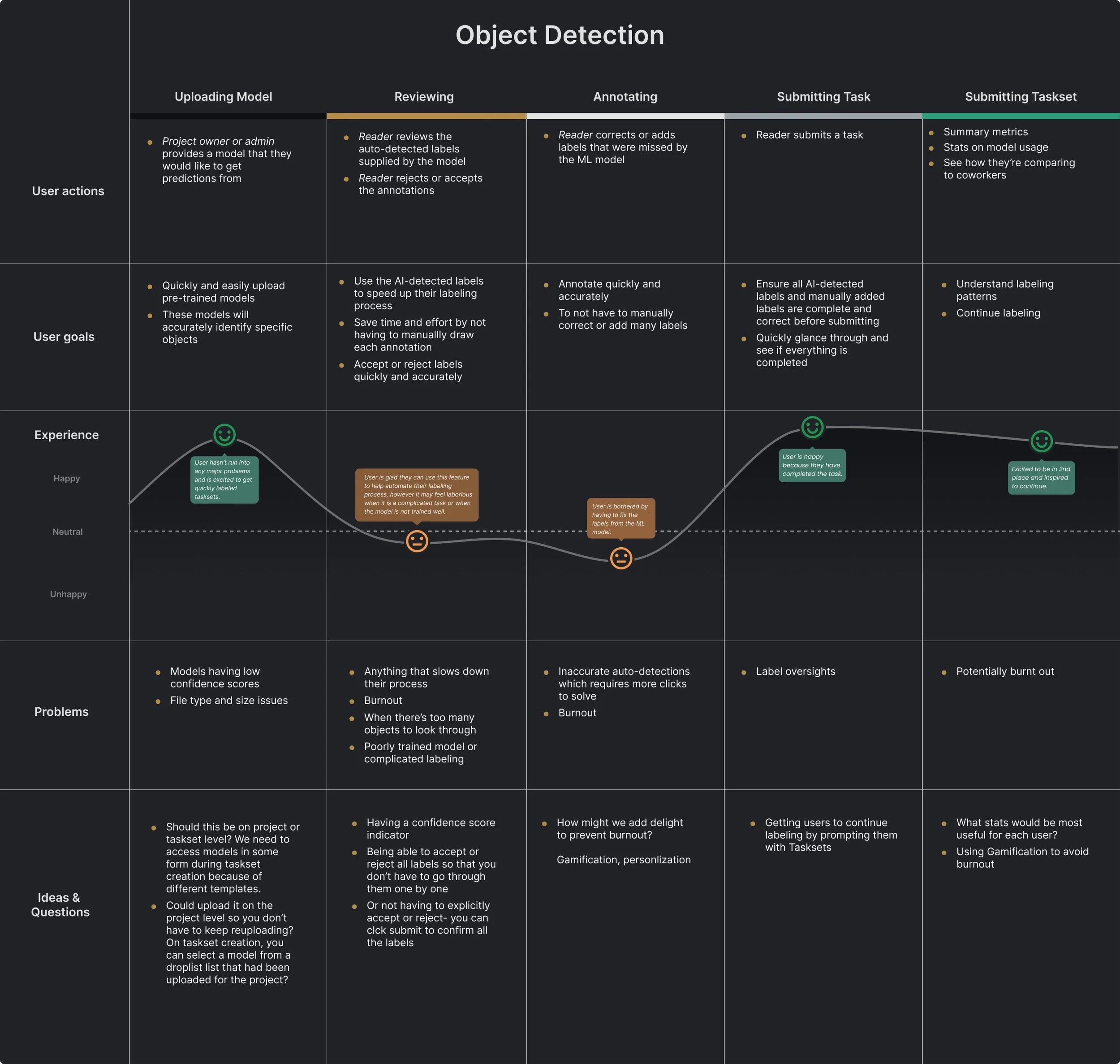
For our more complex features like Model Validation and Object Detection, we created user journey maps to visualize the exact steps and experiences a user would go through. It helped us hone in on their journey and refine specific aspects of their experience.

🧑🏻💻 Templates
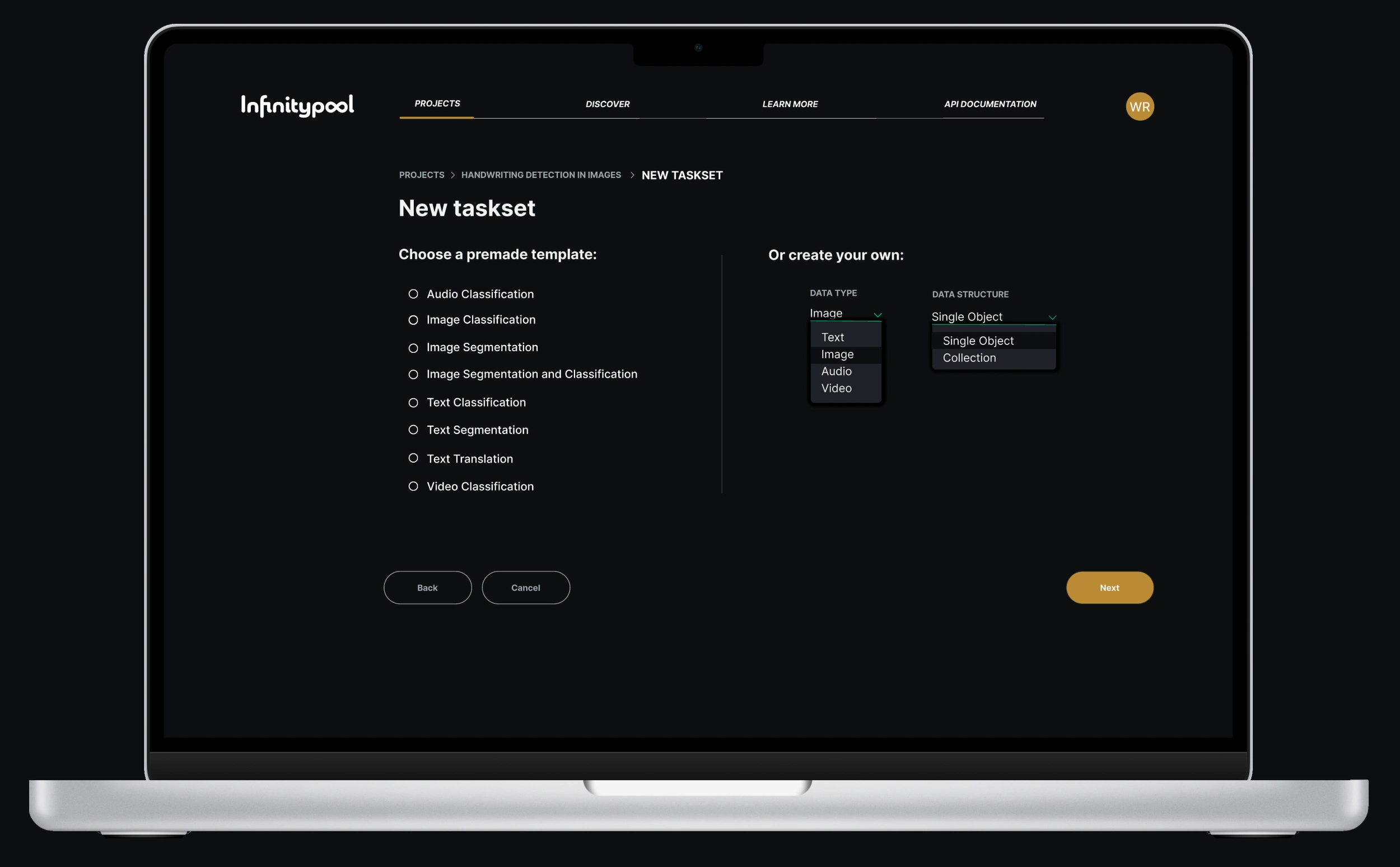
To compete, Infinitypool needed industry standard data-labeling templates. To gain an edge over the competition, Infinitypool needed to be the best at each of these types of labeling. We compiled a comprehensive list of standard templates and also provided users with options to customize their own and combine various types of data types and structures:
During the design of initial mockups, the need for a Dark Mode became evident. We discovered that analysts are typically labeling on a large monitor and in a dark room - this helps them label more accurately. But labeling on this bright, white screen in this setting can cause eye strain.
Labeling mass amounts of data can be an arduous task. We needed a way to incorporate delight into this process and received feedback from users that they would love to see how their metrics stacked up against their co-workers. The gamification feature was built out in a way that inspired users to continue labeling by adding competition:
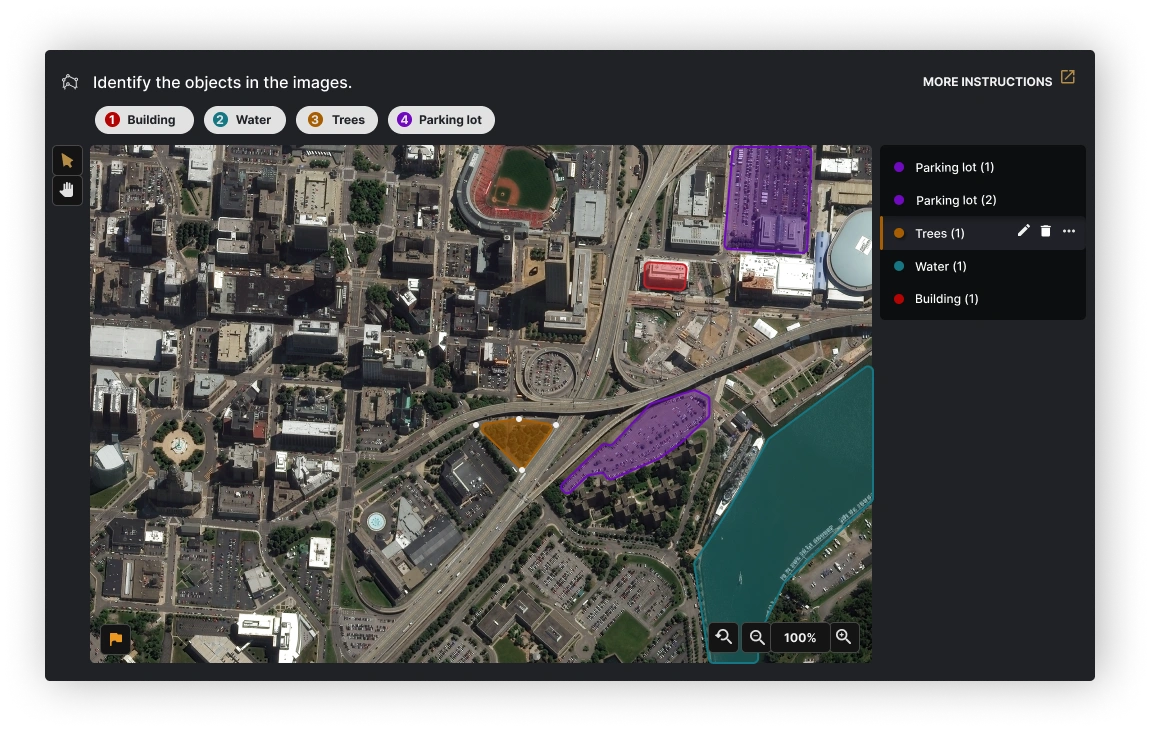
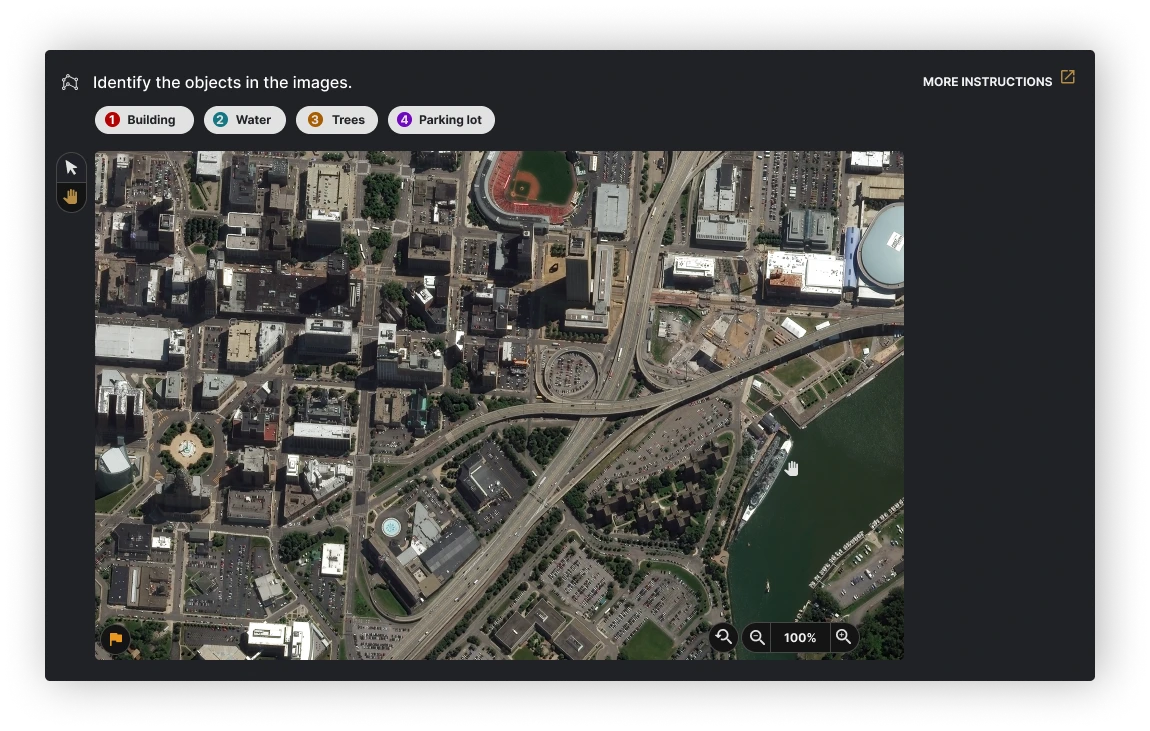
🖼 Image Segmentation
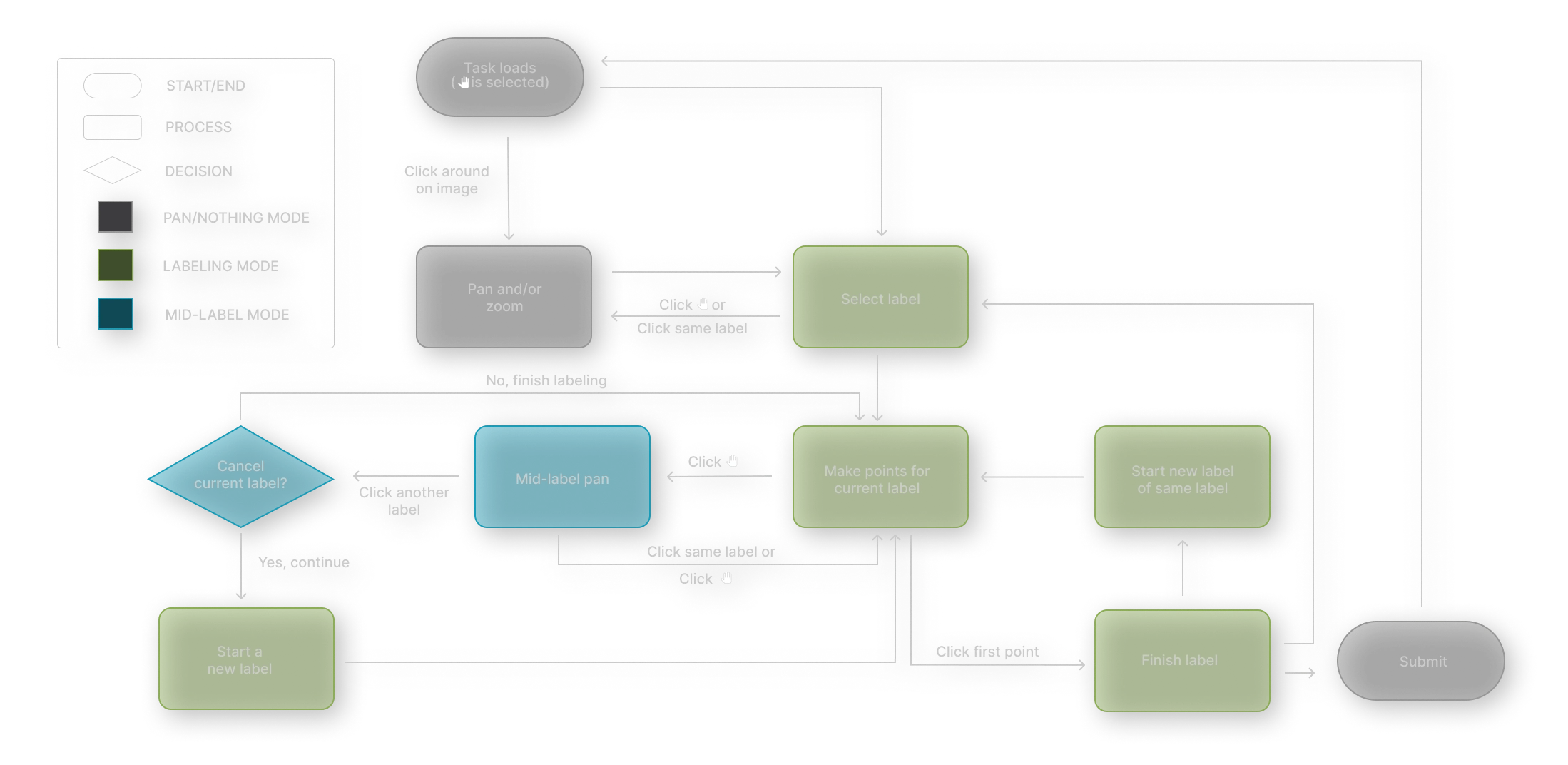
One of the more challenging features to design was Image Segmentation. I was responsible for making segmenting objects within an image a smooth experience for an Analyst. This required rounds of feedback and iterations. A task that seemed simple at first, like Panning across an image, required a detailed workflow diagram.
This workflow diagram illustrates to developers exactly what happens at each step of the Panning and Labeling process:
🤖 AI Automated Labeling
Further along in development, we designed a way for users to Accept or Reject Computer Vision AI automated labels. We researched and implemented Layer Contols, Hover States, and a way to mass Accept or Reject labels.
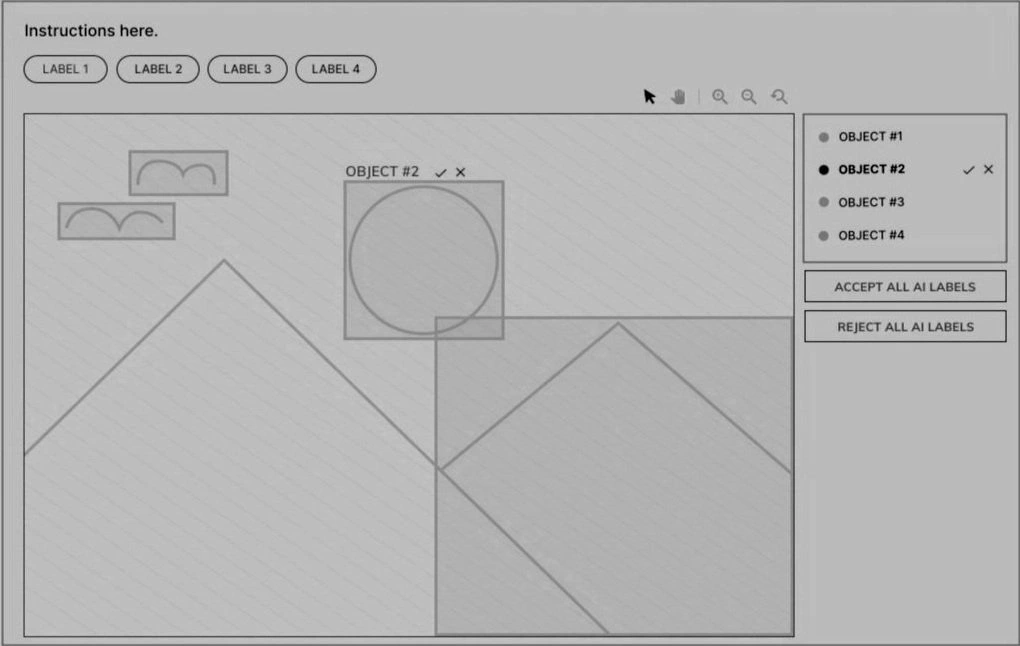
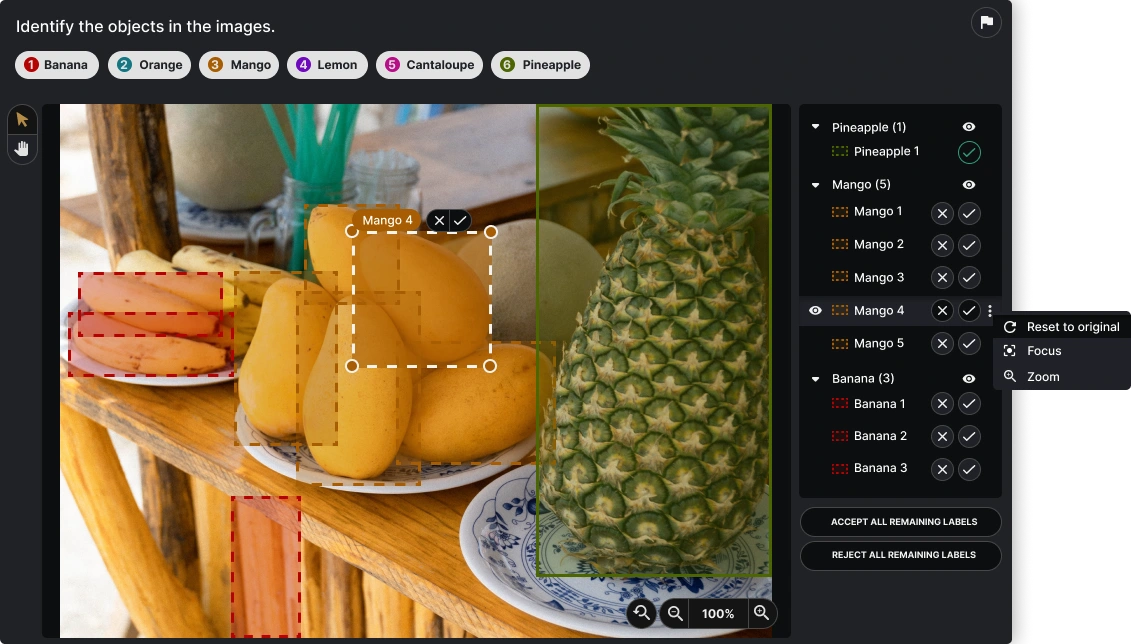
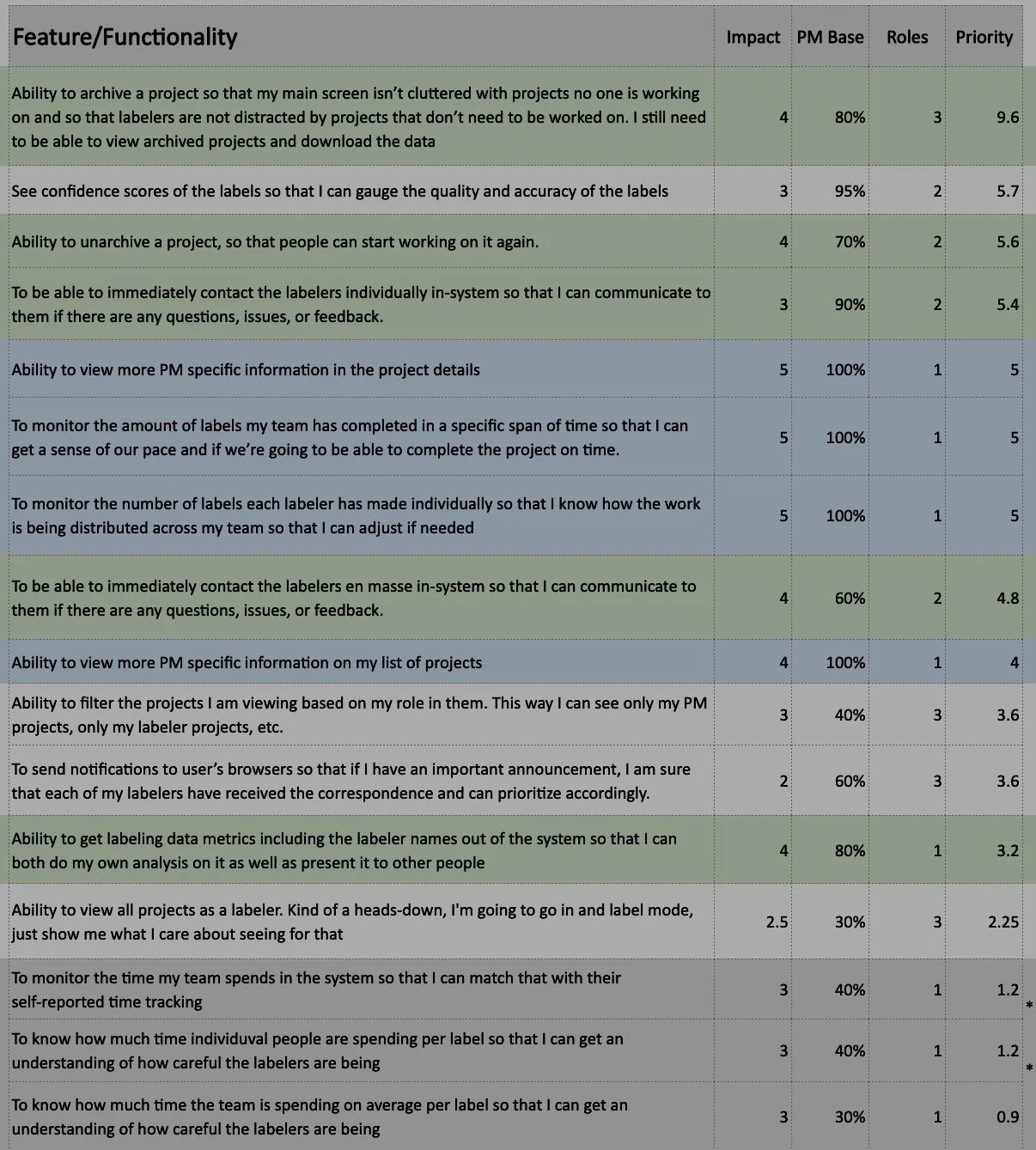
Feature Prioritization
We created a feature prioritization list that included the feature/functionality in question, an impact score, the percentage of users the feature would affect, the number of user roles it would affect.
Those were used to calculate its overall priority rating. Features with the highest ratings guided our iteration process.
Like this project
Posted May 5, 2026
Designed user-friendly, competitive data-labeling features for Infinitypool.
Likes
0
Views
4
Timeline
Dec 31, 2019 - Dec 31, 2020