RAG Agent Automation with n8n and Vector Database
Hassan Nawaz
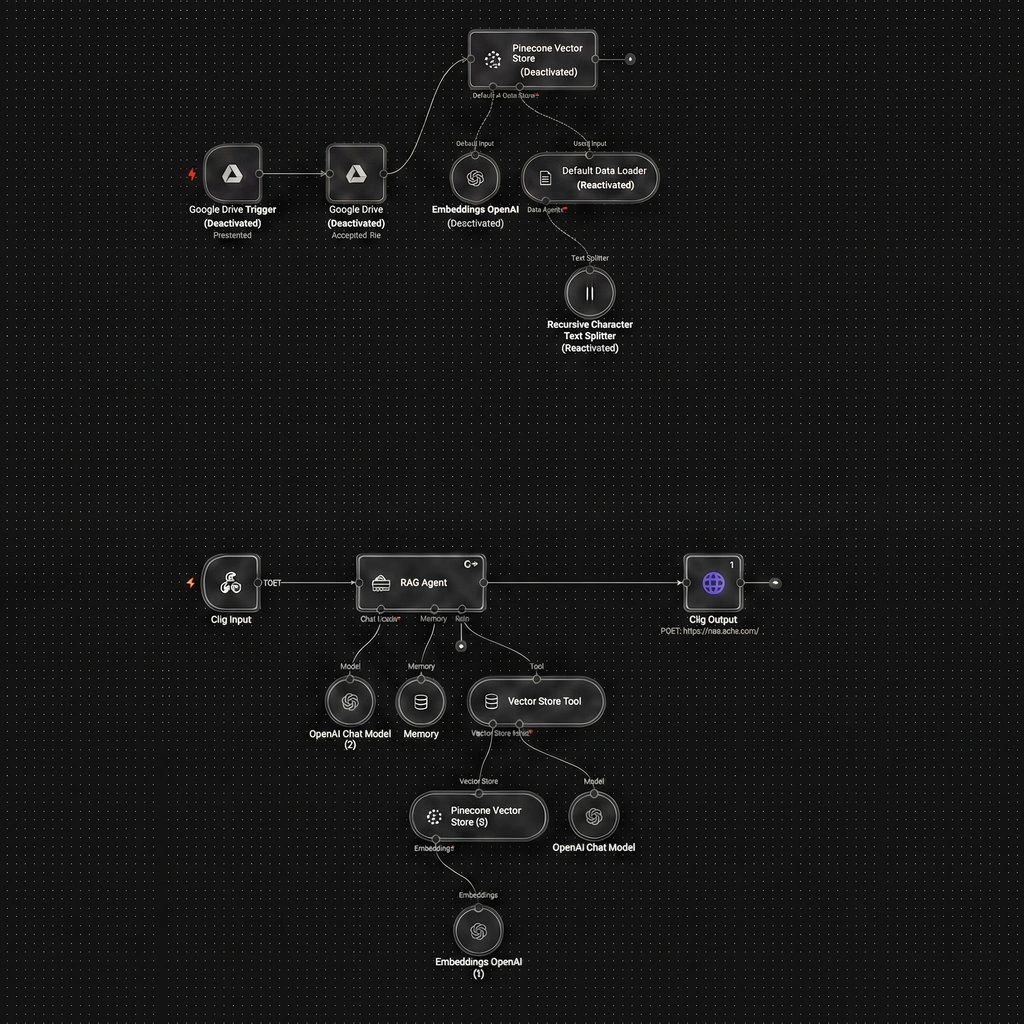
Built a production-ready Retrieval-Augmented Generation (RAG) agent using n8n to enable accurate, context-aware responses from private documents. The system ingests files from cloud storage, chunks and embeds content, and stores vectors in a database for structured retrieval.
The workflow separates ingestion and query pipelines and includes validation and controlled data access. This design ensures reliable, scalable knowledge retrieval while maintaining consistency and accuracy under real-world usage conditions.

Like this project
Posted Jan 22, 2026
Built a production-ready RAG agent in n8n for accurate document-based retrieval using vector storage, validation, and controlled query pipelines.




