crashlattice57/ML_Malicous_URL_Classification
Damian Moore
Data Science Malicous_URL_Classification: Project Overview
Created a tool that can take a url as an input and return whether the url is malicous, phishing, web defaced, or benign.
Feature Engineered a single column data set into multiple additional columns and feaures based on url stats
Trained several models for classification to include Logistic, Decision Tree, Random Forest, and K Nearest Neighbors.
Built client facing API using Flask
Code and Resources Used
Python Version: 3.10
Packages: pandas, numpy, seaborn, matplotlib, sklearn, flask, jsonify, json, pickle, requests
Data Cleaning / Feature Engineering
Upon seeing the data, I identified that it was not enough information for a classification model to make reasonable predictions. I added several new columns based on domain knowledge and statistics.
Created columns:
length of url
how many parts of seperated by "."
length of suffice (".com",".ru",".md", etc.)
ip address present
file extension present
shortened links present ("bit.ly", "t.co", tinyurl.com", etc.)
took a list of special characters and got the count of each in a url and created columns of the results
EDA
identified distribution and correlation between columns and the classification value, Used groubyby, scatterplots, and heat maps for visualizations. Highlights Below
Identified that the benign url were almost all over the place, but you can see that of the malware, phishing, and defacement url were more tightly clustered.
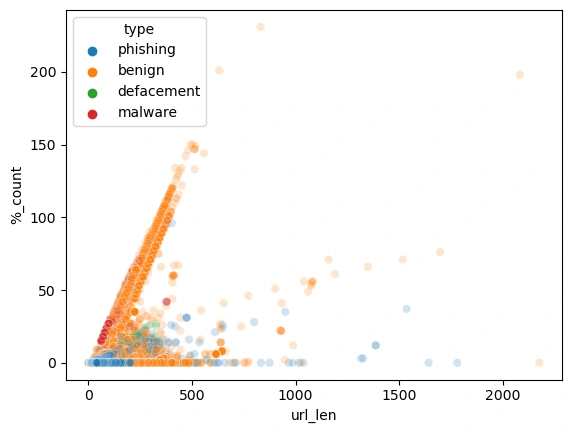
Malware url, had a significantly higher chance to have an ip address present.
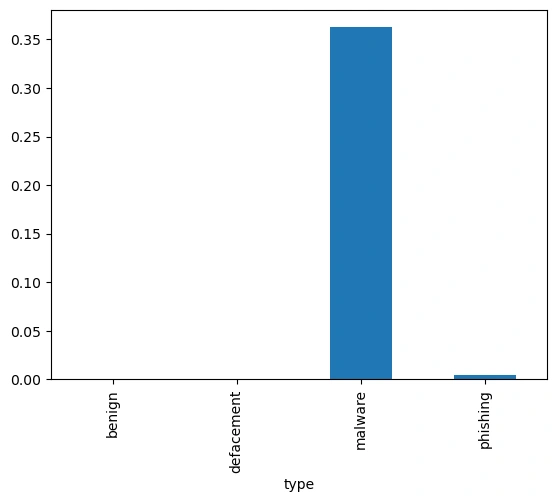
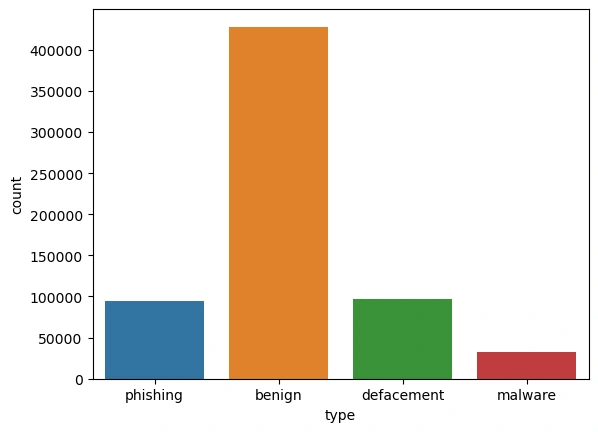
The dataset is very imbalanced , with benign urls having over 50% of the values in the dataset, depending on the results of the models, I would have considered merging the data between the other columns and creating a binary classification vs. a multiclass
Model Building
For Model Building I knew a couple models that I wanted to try ahead of time that I usually get good results from, First I split the data in a 70/30 train test split. I then dropped the "type" column that we are trying to predict from my X data and then dropped the "url" column , since I already have the important features in the new engineered columns. I then used Sklearn's StandardScaler to scale all of the X data. Created a function that takes in all of the takes and trained them all and compared results based on accuracy, recall, precision and f1 scores. Depending on the results of the training I would have used different hyperparameters for each model via a gridsearch.
Model performance
Both Tree Based Models performed the best, but the RandomForestClassifier was the best overall
DecisionTreeClassifier
Accuracy: 93.89999999999999%
Precision: 91.8%
Recall: 91.3%
F1-Score: 91.5%
LogisticRegression
Accuracy: 78.0%
Precision: 62.1%
Recall: 56.699999999999996%
F1-Score: 58.199999999999996%
RandomForestClassifier
Accuracy: 94.5%
Precision: 92.9%
Recall: 92.0%
F1-Score: 92.4%
KNeighborsClassifier
Accuracy: 91.8%
Precision: 89.5%
Recall: 87.7%
F1-Score: 88.5%
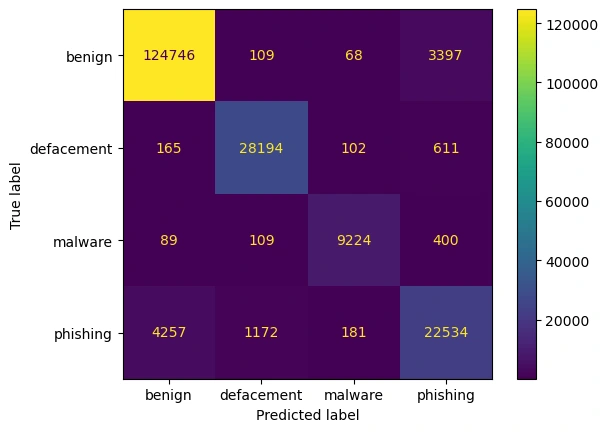
Confusion Matrix
Confusion matrix of the True Labels and Predicted Label,
Model Deployment
I then pickled the model and created a flask API endpoint hosted on a local server that takes in a single url and identifies the class
Like this project
Posted May 31, 2024
Contribute to crashlattice57/ML_Malicous_URL_Classification development by creating an account on GitHub.
Likes
0
Views
8