API integration and Backend Development
Chaitanya Tyagi
Developed a robust microservice designed to integrate with third-party APIs seamlessly. This tool enables efficient data retrieval and ingestion into internal databases, significantly optimizing data processing workflows. By replacing traditional scraping techniques with direct API integration with e-commerce sites like Amazon, Walmart, and Instacart, the service improved the speed and accuracy of data ingestion, leading to enhanced performance and reliability for the platform.
1. API Integration
Objective: Retrieve data from external sources such as Amazon, Walmart, and Instacart using their APIs.
Steps:
Authentication:
Use OAuth, API keys, or tokens to authenticate with third-party APIs.
Store and refresh authentication tokens securely.
Data Retrieval:
Identify and request the required endpoints (e.g., reports, inventory, pricing).
Use query parameters to filter or paginate data for efficient retrieval.
Handle rate limits with retry logic and backoff strategies.
Error Handling:
Implement robust error-handling for API failures, timeouts, and unexpected responses.
Log errors for debugging and monitoring.
2. Backend Microservice
Objective: Create a backend service to handle API calls and process data for ingestion.
Steps:
Service Development:
Write the microservice in Java, using frameworks like Spring Boot for REST API creation.
Modularize the service for extensibility (e.g., connectors for different APIs).
Data Transformation:
Parse and normalize API responses into a unified schema for ingestion.
Perform lightweight data validations and transformations as needed.
Queue Management:
Use a queuing system like Kafka or RabbitMQ to manage API call tasks and ensure scalability.
API Scheduling:
Schedule periodic API calls using tools like Quartz Scheduler or managed cloud services.
3. Glue Job for Data Processing
Objective: Automate the ETL (Extract, Transform, Load) process for the ingested data.
Steps:
Extract:
Retrieve processed data from the microservice's database or S3 bucket.
Handle large volumes of data efficiently with partitioning.
Transform:
Use AWS Glue to clean, enrich, and format the data.
Apply transformations such as filtering, aggregating, and mapping.
Load:
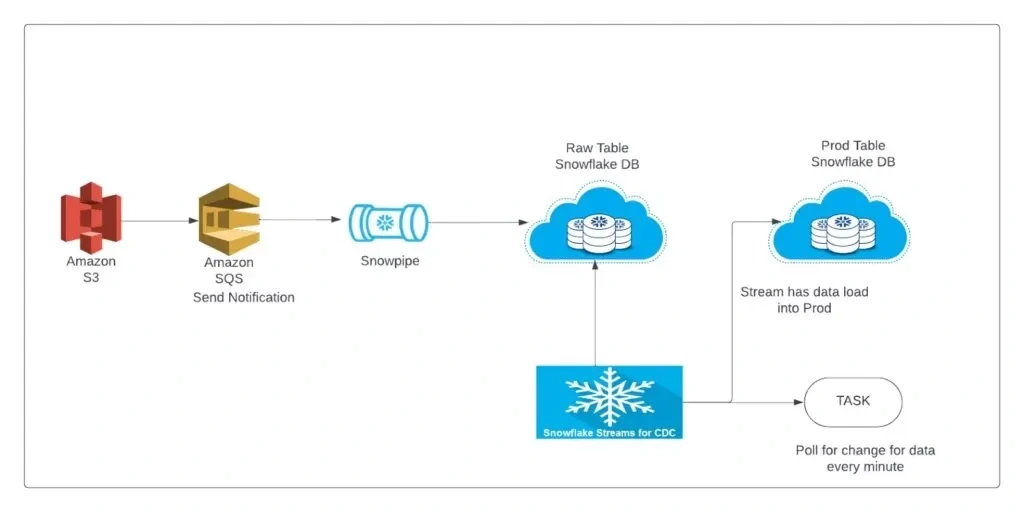
Save the transformed data into a data warehouse (e.g., Snowflake).
Orchestration:
Use AWS Glue workflows or AWS Step Functions to manage dependencies and run jobs sequentially or in parallel.
4. Snowflake for Storage and Analytics
Objective: Store processed data in a scalable cloud warehouse for analytics and reporting.
Steps:
Data Loading:
Use Snowflake’s commands like COPY INTO to load data from S3 into Snowflake tables.
Leverage Snowpipe for real-time data ingestion.
Schema Design:
Create tables with optimized schema to support analytics (e.g., star or snowflake schema).
Use partitioning and clustering for performance.
Query Optimization:
Implement indexing and caching strategies for faster query execution.
Data Security:
Apply role-based access control and encryption to secure sensitive data.
5. Monitoring and Maintenance
Logging and Metrics:
Use tools like AWS CloudWatch, ELK Stack, or Datadog to monitor API calls, Glue jobs, and data warehouse queries.
Alerts:
Configure alerts for API failures, job errors, or anomalies in data ingestion.
Scaling:
Use auto-scaling for the microservice and Glue jobs to handle varying data loads.
Like this project
Posted Nov 21, 2024
API integration and backend development for data ingestion and warehousing.