Data Staging Area Implementation for Enhanced Data Management
Szymon Zaczek
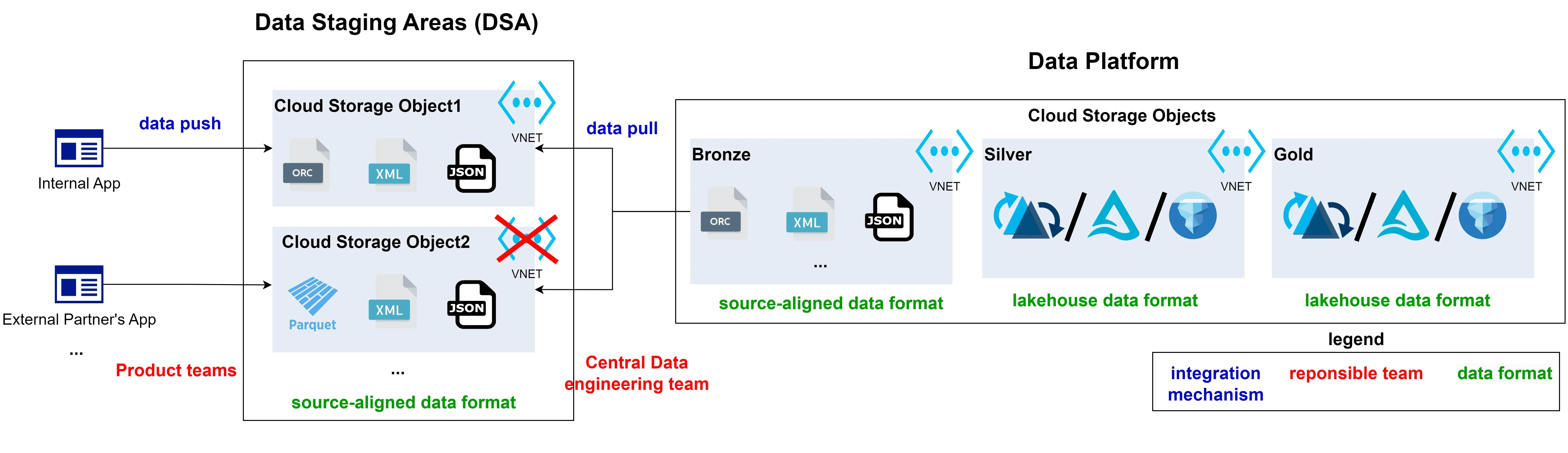
A data staging area (DSA, also called data landing zone) is a vital component of a data platform in large organizations, in which many different teams are interested in having a centrally governed and managed storage solution. It is an intermediary storage layer that acts as a gateway to the persistent storage layer within the main data platform. It is an additional data layer prior to the well-established medallion architecture, that acts as a foundation of data management within Lakehouse platforms.
Before I explain what a data staging area is and what problems it solves, let’s briefly review the typical data layers found within modern data platforms.
Data layers within modern data platforms
Modern data platforms typically aim to adapt the Data Lakehouse paradigm, integrating ACID transactions, governance, and security with decoupled storage and compute infrastructure for independent scaling. Within Lakehouse platforms, data is usually processed accordingly to the well-adopted medallion architecture:
bronze (raw) — Represents data in its raw, unprocessed form. This is where data from various sources is ingested and stored as-is, without any transformations or modifications. The purpose of the bronze layer is to preserve the original data for future exploration or analysis. Format of data files is dependent on a source-system.
silver (cleansed) — Data promoted from bronze layer undergoes a process of cleansing and basic transformations upon landing in silver layer. It includestasks such as data validation, deduplication, schema enforcement and standardization. The goal here is to ensure that the data is clean, consistent, and ready for further processing. Format of data files adheres to one of Lakehouse-compliant formats, such as Delta Lake, Apache Hudi or Apache Iceberg.
gold (curated) — The final layer in the medallion architecture is the gold layer, also known as the curated layer. In this stage, data is further refined and enriched to make it more valuable for analytics and business intelligence purposes. This mostly involves creating a business-level aggregates and data models built upon data coming from multiple source systems. Format of data-files is either Delta Lake, Apache Hudi or Apache Iceberg, similarly to silver layer.
Why would we ever need another data layer then? Isn’t it enough to have those 3 well-established zones?
It turns out that quite often, it’s just not enough.
Where standard medallion architecture falls short and what’s the issue
Let’s imagine following scenarios:
Cooperation with external partners. Our company cooperates with many external partners that cannot expose data to us via the modern interfaces (such as messages, APIs). Instead, they can only share data files with us. They are embedded within an on-prem data center though and they are prohibited from giving direct access to their servers to other companies. The only sensible solution is that they’ll upload files to a server or storage service owned by our company. However, our company’s internal infrastructure is situated within Virtual Network for security and compliance reasons, hence we need a storage solution that would bridge the gap betwen external partners and our company.
Persistent data storage at scale with overloaded central data engineering team. There are a lot of product-oriented teams within our organization that would like to take advantage of a centrally governed and managed storage layer. However, central data engineering team only employs a few people, hence they can’t build ingestion pipelines from the source systems themselves at scale. Also, product-oriented teams do not have an immediate usecase for their data but creating a history of records proved to be a succesfull strategy for the company. Therefore, product teams would just want a storage that they could push data into, without having to adapt to the data management frameworks and coding languages that central data engineering team has adapted.
Throughout those 2 distinct scenarios, there are 3 apparent issues that are not directly solvable within the standard medallion architecture.
Decouplement of public/private networking. Since we need to cooperate with external partners who cannot be onboarded into our Virtual Network infrastructure, we need some kind of an intermediate storage layer that would facilitate the secure transfer of data between our partners and our internal systems.
Data engineering teams are a bottleneck. Implementing integrations between vast number of diverse source systems and a central data platform is definitely a time-consuming task. On top of it, data engineering teams are involved in data mangement operations, supporting data governance, as well as helping data scientists and data analysts in performing data transformations. All of this contribues to the fact that, quite often, data engineering teams are a bottleneck within technology companies.
Responsibility separation. In order to scale storing data in a centrally managed solution, integrations sometimes need to be built by engineers creating client-facing applications. Considering that product teams usually just want to push data to a persistent layer, so it can be stored for historical analysis, data doesn’t need to be processed up till gold layer straightaway. In fact, it’s enough that data is initially stored in a source-aligned, raw format. However, since it’s not data engineers that would be building the integrations to the source systems here, they can’t be responsible for all of the operational support that those data integrations need. Hence, there is a need for a clear boundary of work delivered by product teams and data engineering teams.
So how can those distinct issues be solved elegantly, just by introducing one specific piece into our data platform architecture? Let’s finally discuss the concept of data staging area.
Data Staging Area overview
Teams responsible for products or applications, aiming to distribute their data in a centralized, well-regulated, and structured way throughout the company, push their data to Cloud Object Storage (for instance, S3 bucket/Azure Storage Account/Google storage bucket). The data arrives in Cloud Object Storage in a source-aligned format. Depending on whether the product team is internal to the company or an external partner, Cloud Object Storage may be enclosed within the company’s Virtual Network or it can be open to the public Internet. Each application sharing data should have its own Cloud Object Storage. Collectively, these storages form the Data Staging Area (DSA). From the DSA, the central data engineering team pulls data into the medallion architecture of the Data Platform.
Let’s now explore the concept of DSA in details.
Facilitation of Push-Based Integrations
The data staging area is specifically designed for push-based integrations and should not be used in other cases.
For instance, if data can be shared between product team and data engineering teams via publish/subscribe pattern, then product team should create their own publisher app/service, into which data engineering team should subscribe, ingesting data into bronze layer of data platform. Please note in such a case, the employed event broker should be standardized throughout the company so data engineering team is well aware how to efficiently build an integration and that this process is streamlined. Then, the onboarding process of new data producers become very fast as easily maintainable.
Public and Private Networking handling
Depending on the nature of cooperation between product and data engineering teams and its specific requirements, data staging areas can be deployed as either public-Internet facing or confined within the company’s Virtual Network infrastructure. When created for an external partner, data staging area should be reachable on a public Internet. When created for a cooperation with an internal product team, it should be deployed within Virtual Network, unless a source-system is only publicly-facing solution itself.
Responsibilities Decoupling
In the context of DSA, responsibility decoupling refers to separating duties between teams building push-based integrations (usually product teams) and those that build pull-based integration as well as use data in a broader, analytical (or predictive) context (see the graphic at the top of Data Staging Area overview section). Those tasks may be carried out by central data engineering team, members of data platform team, domain-focused data engineers or data analysts/developers that need to leverage incoming data for one of the projects they’re working on.
Responsibilities of team building push-based integration
The team building push-based integration holds a certain range of responsibilities revolving around the initial stages of data handling. These include:
Data Push: Ownership of the solution (code/compute infrastructure/credentials) belong to the team that is building that particular integration.
Push-based Integration Monitoring: In addition to carrying out push-based integrations, this team is also responsible for monitoring of solutions, so operational support can be provided. This includes tracking the successful uploads of data, detecting and resolving any errors or issues that may arise during the process.
Data content (including data quality) in DSA (unless there is dedicated data owner): Since usually the team that builds integration also builds the source application, data pushed by their integration must be their responsibility, accordingly to agreed upon SLAs. However, they’re not responsible for data quality within medallion architecture of data platform, because they are not the ones that build data transformations that promotes data throughout medallion architecture
Central Data Engineering Team Team responsibilites
The Central Data Engineering team takes over once the data has been pushed into DSA. Their responsibilities include:
Data Ingestion from Staging Area into Medallion Architecture (pull-based integration): Core role within the application of DSA for central data engineering team is that they ingest data from DSA into medallion architecture within a data platform.
Data Transformations: This function mostly include promoting data throughout supported data layers within data platform (medallion architecture), while adhering to the boundaries between different layers and ensuring common standards across all datasets (including data coming from different sources)
Data Quality Metrics within Data Platform: Central data engineering team needs to implement data quality metrics monitoring, such as accuracy, completeness, consistency, reliability, and timeliness; note those can be tracked only within medallion architecture and not within DSA — central data engineering team is not responsible for data quality within DSA
Jobs Monitoring within Data Platform: This team is also tasked with monitoring all jobs (processes) running within the data platform to ensure they are functioning as expected.
Self-service Capabilities of Promoting Data (optional): Central data engineering team is also responsible for enabling self-service capabilities of promoting data from DSA into medallion architecture of data platform; it usually can be done until silver/cleansed layer, since this is the last layer that do not involve combining data across different sources
Data Lifecycle within Data Platform (optional): If there are global rules for Data Lifecycle, it’s central data engineering team that’s responsible for retention rules, backups, data archiving, as well as storage tiering lifecycle
Data Governance Capabilities within Data Platform (optional): Depending on who builds technical capabilities of data governance, central data engineering team might be responsible for building technical capabilities of leveraging central data governance, including access control and anonymization of sensitive data
DSA infrastructure (optional): Cloud services that build up DSA can be owned by central data engineering team, if there is no dedicated data platform team or if the infrastructure is not centrally owned by cloud operations team
Pulling data from DSA puts much less effort on data engineers than ingesting data from source sytems
Since DSAs are designed to use a standard Cloud Object Storage, which is heavily utilized by the data engineering team anyway, pulling data from DSAs into the Data Platform is straightforward. This process can be streamlined to such a degree, that along with the deployment of a new Cloud Object Storage within DSA for a new application, an event-based job would be also deployed. This job would pull data into the raw data layer of the Data Platform upon the arrival of new files in the newly created storage.
Reusing such components for multiple systems enables great scaling capabilities of the system, reducing the overhead that data engineerng team would introduce if they needed to pull data directly from source systems.
That being said, pushing data also requires some effort. However, as long as standard storage APIs are used for pushing data, those operations should be rather straightforward and repeatible. Central data engineering team could also publish a generic libraries supporting coding languagues that are used throughout the company that would streamline authentication to cloud providers and uploading data files to storage. This way, central data engineering team instead of focusing on single point integration, can act as an enablement team.
Incentive-First Approach: Encouraging Data Sharing Among Product/Application Teams
It is in product teams’ interest to share their data to a broader audience. By doing so, they can amplify the impact and reach of their work. This enables them to gain new stakeholders leveraging their data, which in turn may reinforce their standing all throughout the organization.
By going with DSA approach, the dependency on central data engineering team is greatly reduced, since everything in DSA requires a standard, easily programmable and automatable components. It definitely increases the speed of deliverables around analytical and predictive usecases of data across the company. It also makes sharing data within the company just so much easier.
By adopting the DSA approach, the dependency on the central data engineering team is significantly reduced since everything in DSA involves standard, easily programmable, and automatable components. This certainly accelerates the delivery speed of analytical and predictive use cases of data throughout the company. Moreover, it greatly simplifies the process of sharing data within the company.
One data staging area per one source system
The best practice for building a Data Staging Area (DSA) is to create a single staging area for each individual source system. This means that there should be a single Azure storage account, S3 bucket, or Google storage bucket designated for each source system. Adopting this approach facilitates optimal network and access decoupling between non-related source systems. This leads to improved organization, increased security, and enhanced efficiency in data handling as each source system’s data is isolated and managed separately. It also simplifies troubleshooting and maintenance processes since any issues can be localized to the specific DSA associated with a particular source system.
Access Permissions Rules
Team Building Push-based Integrations: These teams are granted write access while restricting updates to data, so once data is pushed, it cannot be modified. This is a crucial measure to maintain data integrity and prevent unauthorized changes or potential data corruption further downstream.
Central Data Engineering Team: This team is granted read access to data in DSA, which enables them to promote data into medallion architecture. They are not permitted to modify or delete any data residing in DSA, ensuring that the original dataset remains intact and unaltered. This access level safeguards against potential data mishandling, while still allowing for meaningful data usage and exploration.
Cost Considerations
Implementation of DSA comes with a cost, both on the infrastructure and compute side. There is an additional storage resource and an additional integration/ingestion job between DSA and data platform’s storage, which would be both redundant if we ingested directly into raw layer of data platform.
While not employing DSA is less costly in terms of direct cloud expenses, it does come with certain compromises that need to be taken into consideration. Please remember that we’re focusing here on the cases where data engineering teams are overloaded and they can’t really keep up to their growing backlog and as a solution for that, we’re trying to allow product/application teams take ownership of data sharing capabilities, instead of relying on overloaded data engineering team.
Though foregoing DSA reduces direct cloud costs, it’s essential to consider the accompanying trade-offs. We’re primarily considering scenarios where data engineering groups are overwhelmed, struggling to manage their expanding backlog. As a resolution, we aim to enable product/application teams to take ownership of data sharing capabilities rather than relying on overloaded data engineering teams.
Challenges When External Teams Ingest Data Directly Into Raw/Bronze Layer of Data Platform
Onboarding Product Team
If a product team is allowed to write data directly to data platform’s storage layer, they should be onboarded into rules of living within data platform. This includes a thorough understanding and adherence to data quality standards, rules governing various data layers, and other operational guidelines. Non-compliance or lack of understanding in these areas can lead to setbacks, inefficiencies and pointing fingers at each other between the teams, if anything goes wrong.
Unified Monitoring
One of the most widely accepted best practices within Data Platforms is the unified monitoring of processes that affect data, including data ingestion. In instances where an external team is ingesting data into raw zone of data platform, their monitoring tools should be coupled to that of existing one within data platform. Without it, end data users would always need to know where to look for status of the jobs that produce data they’re reliant upon.
Network Requirements
Cloud Object Storages of data platforms usually need to be placed within company’s virtual network. Due to that, data bandwidth between source systems and data platform should also be within the boundaries of company’s virtual network. If a source system is a client-facing application, it must be open to the public internet, therefore some sort of proxy between company’s virtual network and the app must still exist. DSA can obviously fill that role.
Data Access Limitations
Product teams that build the integration can’t impede with data incoming from other systems, so their access needs to be strictly restricted only to storage objects dedicated just for them. Direct updates on data in raw should be prohibited, in order to ensure that downstream data layers and data products remain consistent. Ensuring that those guidelines are followed might require providing an additional decoupling on storage objects and access rights that was not originally in place.
Benefits for Decoupling of Responsibilities
Clear Boundary Between Who Does What
Having a clear delineation of responsibilities helps in reducing confusion and overlaps in tasks. In a well-decoupled system, there is a clear goal that each team needs to achieve to get the desired outcome. This leads to greater efficiency, as individuals or teams can focus solely on their assigned tasks without having to worry about crossing into another team’s territory. The responsibilities of each team is described further at: Responsibilities Decoupling section of this article.
Enhanced Technological Autonomy for Teams
Decoupling leads to increased technological autonomy for different teams within the organization. Each team has the power to make decisions regarding the technology stack it uses, the tools it employs, and the methodologies it adopts. This allows them to opt for solutions that are best suited for their specific needs and requirements.
Team Can Choose Solutions That Fit Them Best
With decouplement of responsibilities, each team is free to select solutions that are most appropriate for their tasks. They are not bounded by the constraints of a unified system or forced to adhere to technologies that may not be optimal for their objectives. This results in a more efficient operation as teams can tailor their tools and technologies based on what works best for them.
Incentivizing Proper Execution of Tasks
Since each team is taking individual technical decisions, they are incentivized to do things correctly. There is an inherent sense of ownership that comes with this autonomy, leading teams to strive for excellence in executing their tasks. The quality of work produced tends to be higher as a result.
Greater Flexibility and Fewer Dependencies for Teams
Decoupling enhances flexibility within teams as they operate independently from each other. This also reduces dependencies between teams, allowing them to work at their own pace without being held back by the progress or limitations of other teams.
Onboarding Into Data Platform’s rule of living not required
In a decoupled system, the product team does not necessarily need to be onboarded onto the data platform’s rules of living. They can operate independently, adhering to their own guidelines and procedures. This further reinforces the principle of autonomy and allows for more streamlined operations.
Value of the Data Staging Area — is the investment into additional infrastructure components worth it?
Data Staging Area’s value proposition lies in its potential to revolutionize the way organizations manage their data integrations. By promoting a culture of autonomy and responsibility, it paves the way for enhanced operational efficiency and productivity. Therefore, despite the initial investment into additional infrastructure components, it is a strategic move that could significantly boost an organization’s performance and set them on a trajectory towards achieving their long-term objectives by reducing dependencies between product teams and data platform team.
Data Staging Areas are especially effective in a generally loosely coupled organizations that tend to not have a unified integration patterns all throughout the company and when it’s generally quite difficult to ingest data into data platform. If such an ingestion is easy, for instance, if product teams are used to exposing their data on a company-wide messaging platform that is properly governed, then data engineers should probably just ingest data directly into raw layer of data platform from there. If that’s not the case though, and especially, if it’s data engineering/data platform team that’s the bottleneck within the organization, the implementation of Data Staging Area should provide an optimal decoupling for data integrations.
Like this project
Posted Jul 30, 2025
Implemented a Data Staging Area to enhance data integration and management.
Likes
0
Views
10