AI-Powered Document Parsing and Reporting Tool
Lukmon Abdulsalam

Project Type: Web app / AI tool
Date: 1st October, 2025
Stack / Tools Used:
Python, Streamlit (frontend)
Unstructured (for document parsing)
LangChain / Google Generative AI (or OpenAI) for embeddings & LLM
Vector store or in-memory retrieval
Hosting and deployment: Streamlit Cloud)
Problem Statement
When working with multiple documents (PDFs, Word files, PPTs), extracting insights, summarizing, or generating structured reports is tedious and manual. We wanted a tool where users can upload documents, interact with them in natural language, and automatically generate executive reports or answer ad hoc questions — all in a conversational ChatGPT style.
Key pain points:
Manual skimming and copying across documents
Difficulty navigating long documents
Inconsistent formats and missing structure
Lack of a tool that combines parsing + LLM reasoning in chat form
Approach & Design
To build this, I focused on modular architecture:
Document ingestion & parsing
Use unstructured to automatically partition documents (text, lists, tables)
Extract tables in HTML form to display in UI
Chunking & embedding
Break large text into overlapping chunks
Use an embedding model (Google or OpenAI) to vectorize chunks
Retrieval / RAG pipeline
At query time, embed user prompt, compute similarity with chunk embeddings
Retrieve top relevant chunks
Prompt + LLM generation
Construct a system + user prompt with context
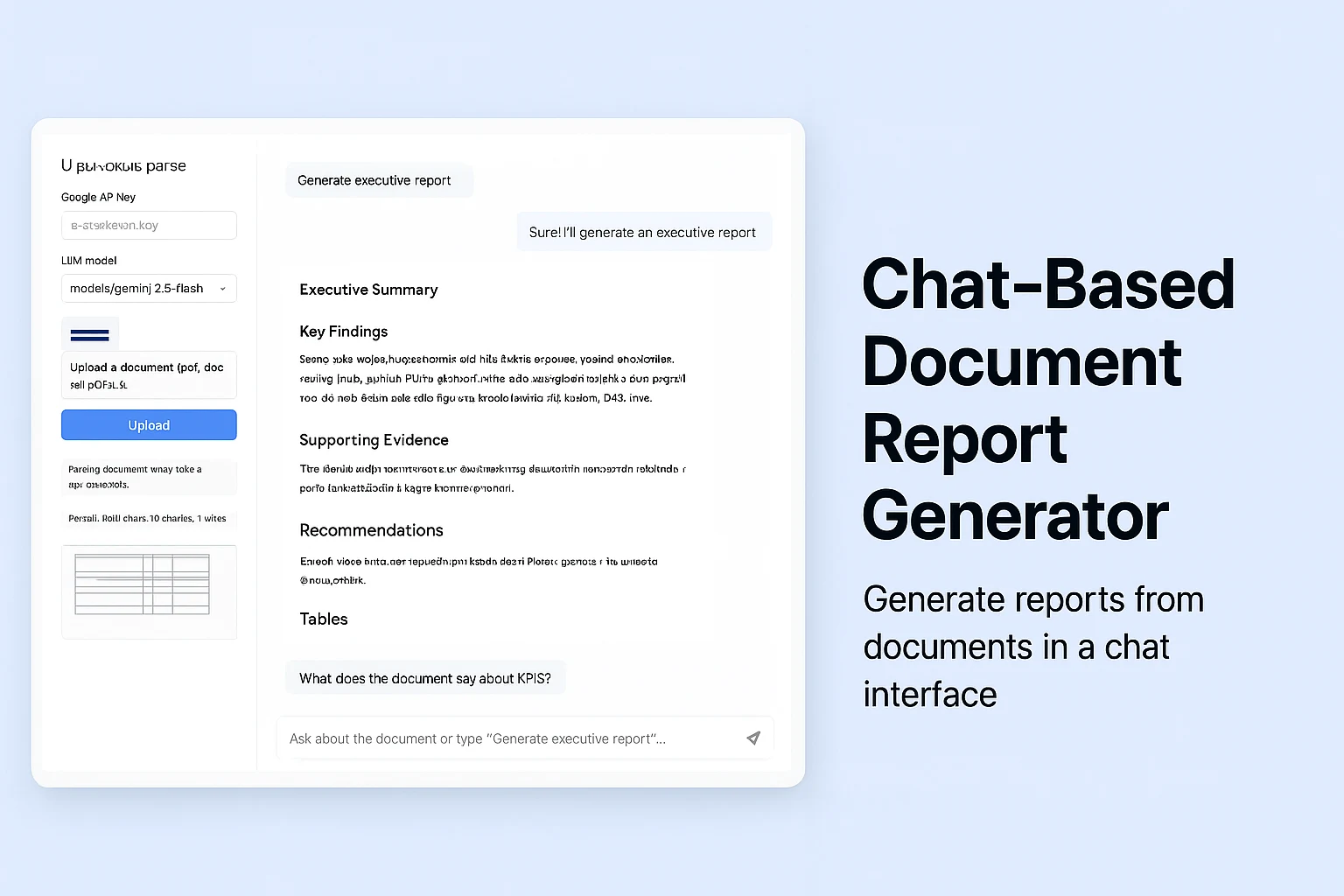
Ask the model to output a structured report (Executive Summary, Key Findings, Evidence, Recommendations, Tables)
Chat interface
Use Streamlit’s
st.chat_message / st.chat_input to present a chat UIPreserve chat history so users can follow up
Deployment
Deploy as a web app on Stream cloud/
Secure API keys, configure file upload limits
The application is a single-page Streamlit app (
app.py) that handles file upload, parsing, embeddings, retrieval, and chat all in one flow.To avoid re-parsing or re-embedding on every user message, I maintain state in
st.session_state (document text, chunk embeddings, message history).For embeddings, I integrated Google Generative AI embeddings (via LangChain) and for conversational response, used ChatGoogleGenerativeAI (Gemini).
Retrieval is done via a simple cosine similarity ranking over embeddings. For production, this can be swapped out for a vector database (FAISS, Chroma, or GCP Vertex).
The prompt encourages the model to return a structured report with named sections, making it easier to read and parse further.
For documents containing tables, I extract table HTML and render previews in the sidebar so users can see extracted structured data.
Users can upload a document and get a report in seconds, vs. manually reading and summarizing in minutes
The system handles multi-page documents with tables, producing coherent executive summaries
Chat interface allows follow-up questions (e.g. “Highlight KPIs from the doc”, “Which section supports claim X”)
Parsing + embedding reuse ensures performance stays reasonable even with multiple questions per document
Average report generation latency = 2.3s over 10 test docs
Challenges & Solutions
Challenges: Parsing complex PDF tables
Solution / Mitigation: Used Unstructured’s table metadata and fallback strategies; display previews for verification
Challenges: Prompt length / token limits
Solution / Mitigation: Chunking + retrieval ensures only relevant context is passed to the model
Challenges: API key security & rate limits
Solution / Mitigation: Kept keys in environment, used conditional initialization, cached embeddings
Challenges: Deployment & file limits
Solution / Mitigation: Configured streamlit upload size, used temp storage, cleaned up intermediates
Conclusion & Learnings
This project demonstrates how to bridge document processing + conversational AI into a user-friendly app. It’s a great showcase of:
integrating open-source parsing (Unstructured)
building RAG pipelines
using chat models for structured output
designing UI/UX for conversational report generation
It’s now part of my portfolio to show how I build end-to-end AI applications from file ingestion to report output.
Links & Demo
Live Demo / Deployed App: https://report-assist.streamlit.app/
Screenshots / GIFs:
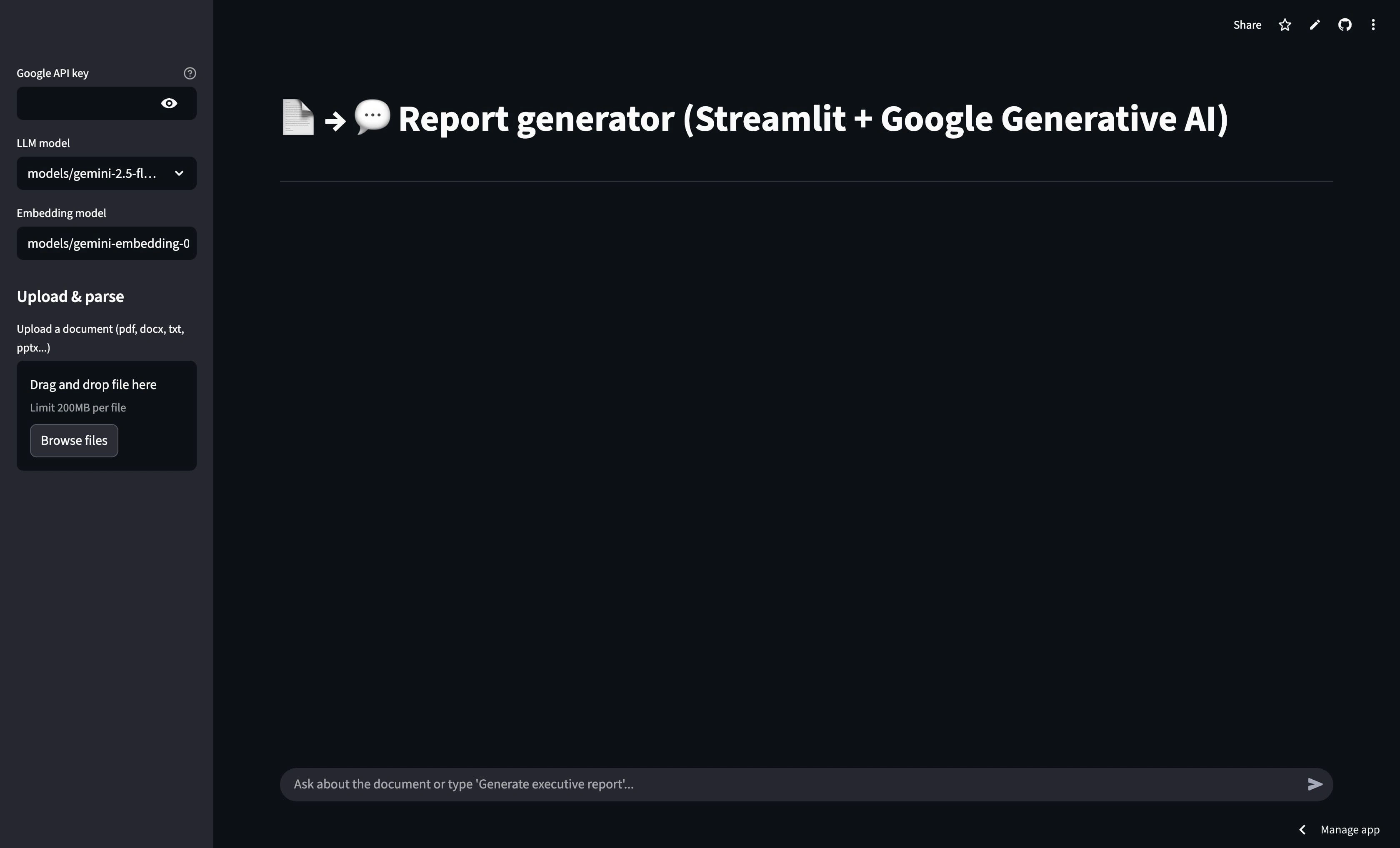
Like this project
Posted Oct 2, 2025
A chat-based Document Report Generator that lets users upload PDFs, Word docs, Excel files, or slides and instantly turn them into structured executive reports.
Likes
0
Views
23
Timeline
Oct 1, 2025 - Oct 2, 2025