LLM + RAG Chat with AlloyDB and Vertex AI
Joven Garcia
Overview
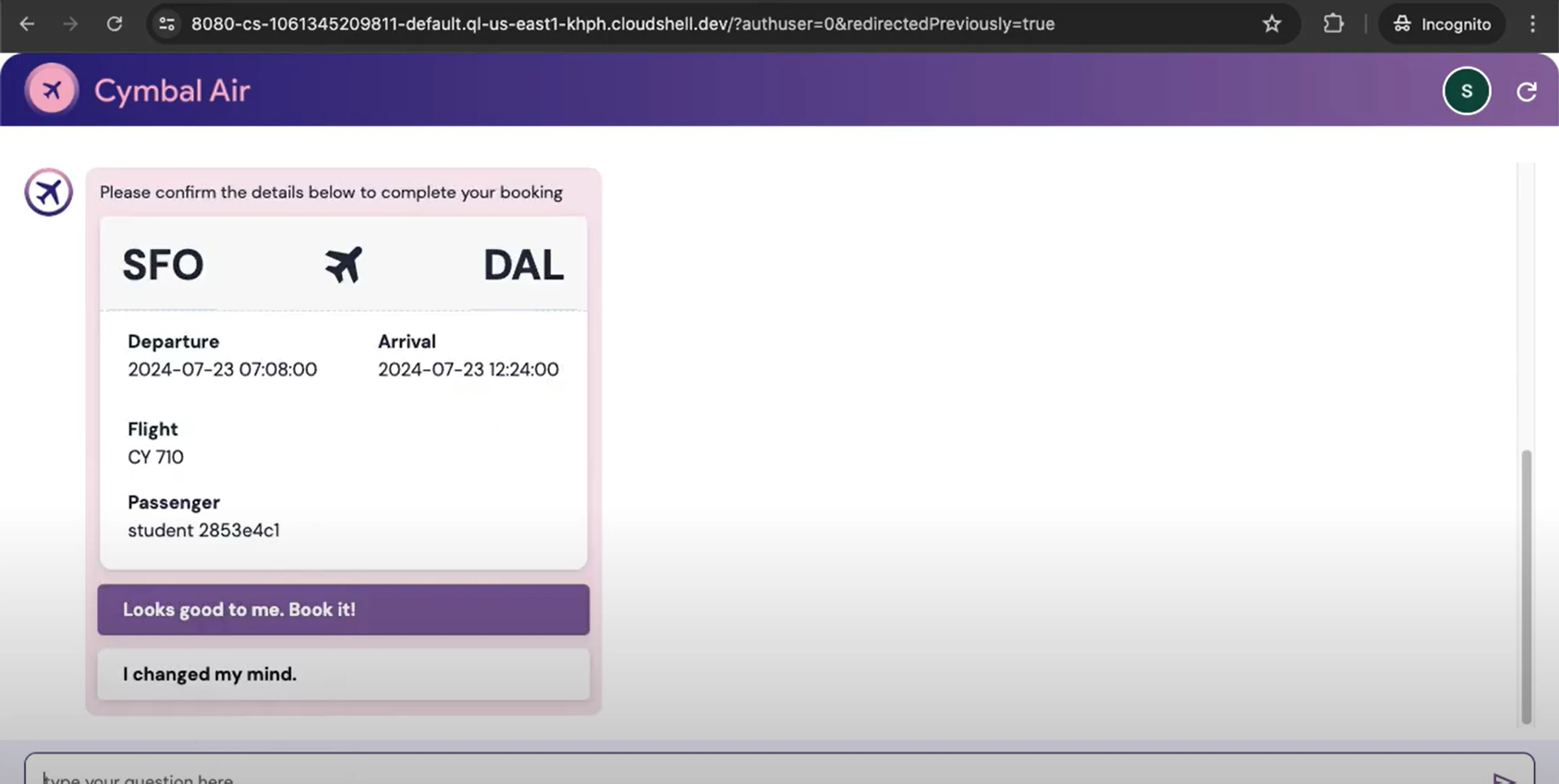
Designed and deployed a retrieval‑augmented chat application that pairs Vertex AI’s Gemini Pro with AlloyDB’s vector capabilities. The system embeds domain documents, performs semantic search in AlloyDB, and injects the most relevant passages into prompts—delivering accurate, context‑rich answers to natural‑language queries at scale.
Key Features
RAG Pipeline: Hybrid retrieval (semantic vectors + keyword filters) to fetch high‑signal context for each query.
Vertex AI (Gemini Pro): Grounded responses with citation snippets and guardrails against unsupported claims.
AlloyDB Vector Search: pgvector‑backed similarity search, ANN indexes, and metadata filtering for fast, precise retrieval.
Context Orchestration: Dedupes, ranks, and token‑budgets context chunks; builds concise, source‑linked prompts.
Citations & Traceability: Returns sources, passage IDs, and confidence scores to support auditing.
Conversation Memory: Short‑term windowing and summaries to maintain multi‑turn context without drift.
Evaluation Harness: Automated relevance/faithfulness tests and latency metrics; prompt/version tagging.
Security & Governance: Role‑based access, PII redaction, content filters, and request/response logging.
Scalability: Streaming responses, batching, and autoscaled workers for ingestion and query spikes.
Tech Stack
LLM: Vertex AI Gemini Pro (generation, summarization, intent classification)
Vector Store: AlloyDB + pgvector (HNSW/IVFFlat indexes, cosine/inner‑product distance)
Embeddings: Vertex AI or open‑source embedding models for document and query vectors
Backend: FastAPI/Node.js service for retrieval, prompt assembly, and response streaming (SSE/WebSocket)
Data Pipeline: ETL for PDFs/HTML/Markdown; chunking, cleaning, and metadata enrichment
Infra: GCP (Cloud Run/GKE), Cloud Storage, Pub/Sub/Cloud Tasks, Secret Manager, Cloud Logging/Trace
Frontend: React/Next.js chat UI with citations, source previews, and feedback thumbs
Workflow
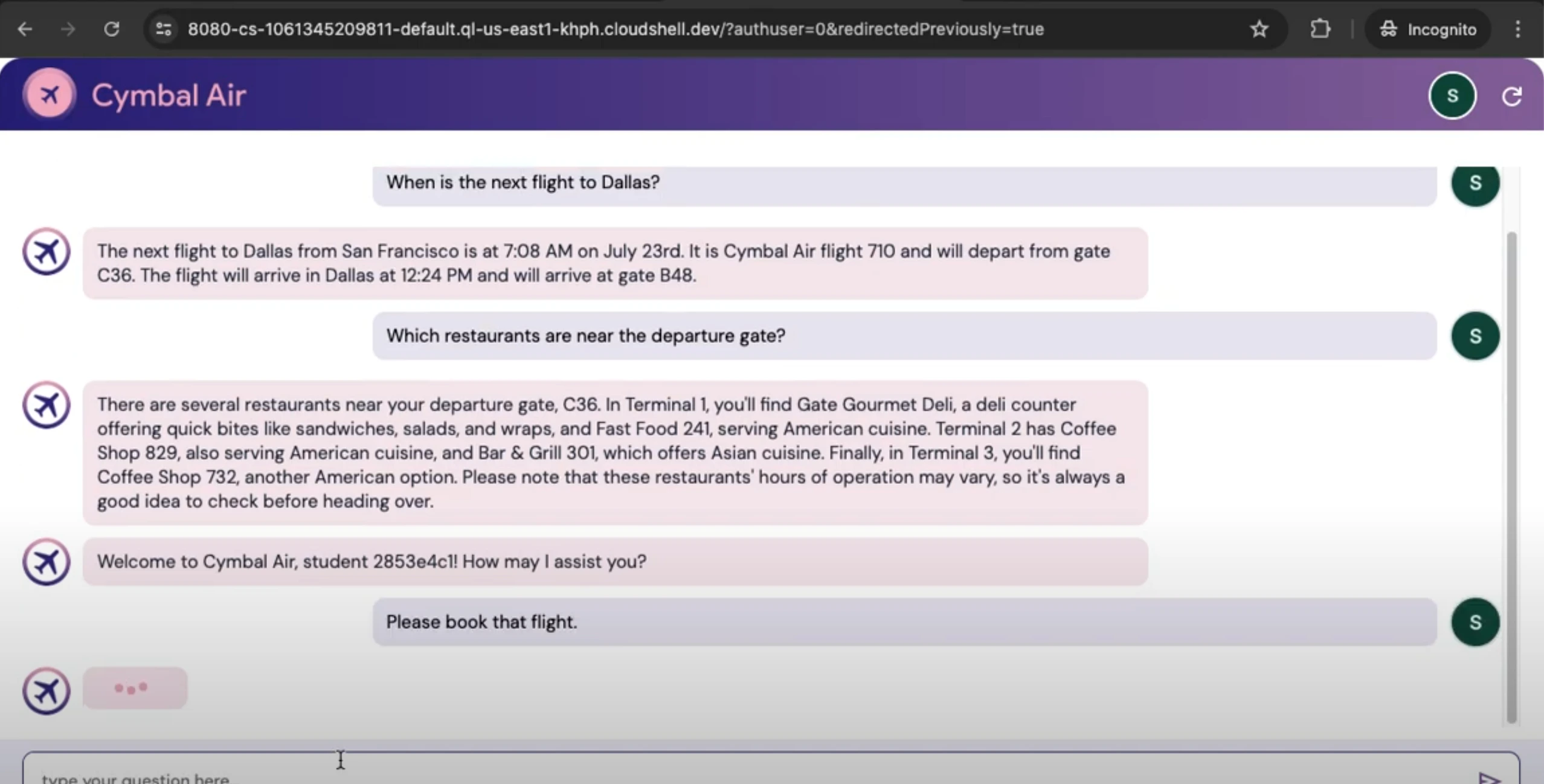
Ingestion: Parse documents, chunk by semantic boundaries, generate embeddings, store in AlloyDB with metadata (source, timestamp, tags).
Query: User asks a question; app embeds the query and runs vector + keyword retrieval with filters (e.g., doc type, recency).
Context Build: Rank by similarity and recency; compress/rewrite passages for token efficiency; attach citations.
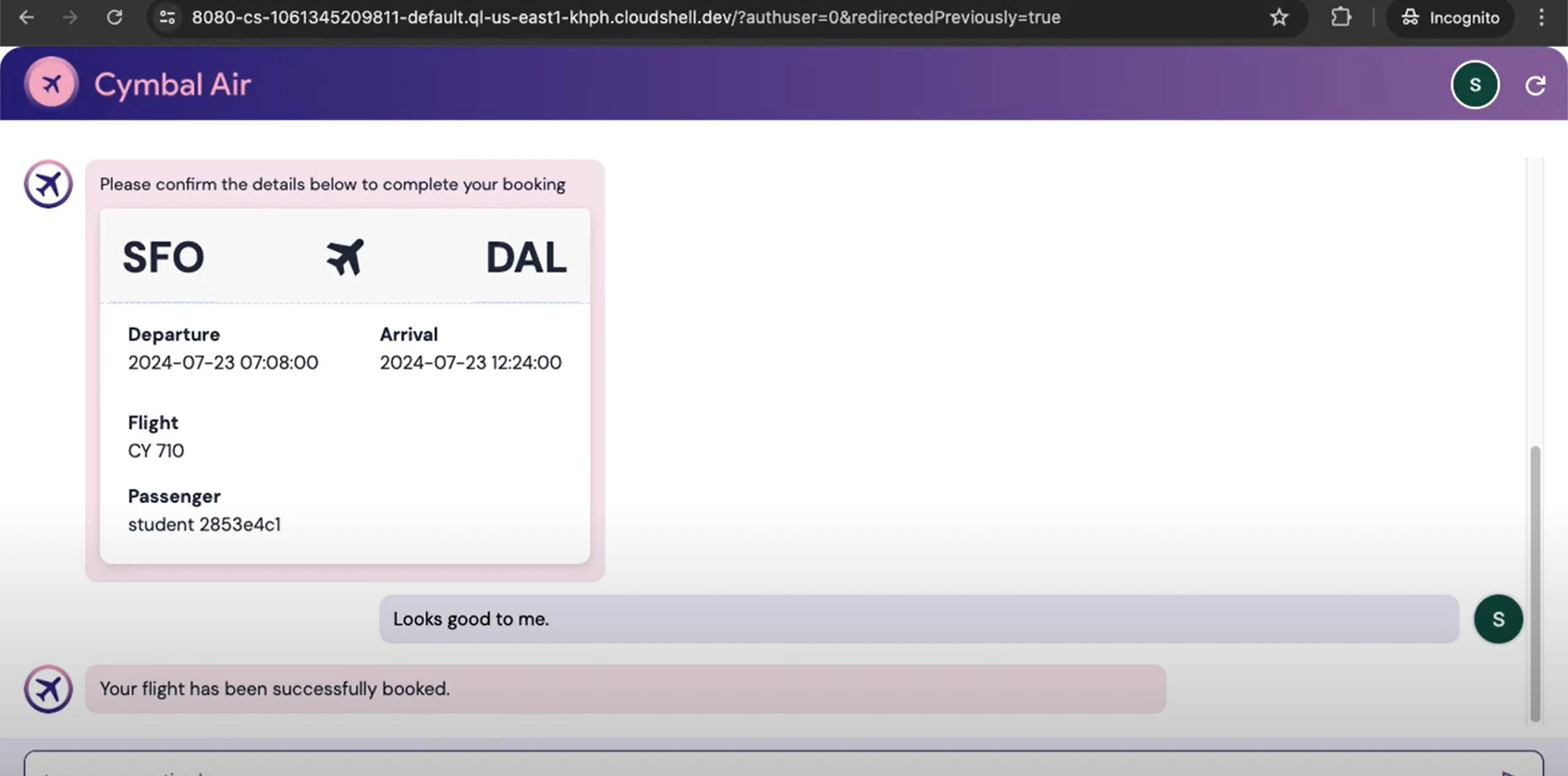
Generation: Send structured prompt to Gemini Pro with system instructions and context; stream the answer.
Post‑Processing: Add citations inline; detect hallucinations via rules/consistency checks; log metrics and feedback.
Memory: Maintain conversation state with rolling summaries to inform follow‑up questions.
Challenges & Solutions
Hallucinations: Enforced grounding by strict prompt templates, max‑context policies, and citation requirements; fallback to “no answer” when confidence is low.
Latency Under Load: Used ANN indexes, response streaming, and retrieval caching; pre‑computed reranker scores for hot content.
Context Bloat: Implemented chunk‑reranking and context compression (map‑reduce summarization).
Data Freshness: Incremental re‑indexing and TTL‑based retrieval prioritizing recent content.
Results
Higher answer accuracy and relevance versus baseline LLM prompting.
Transparent responses with citations and confidence indicators.
Production‑ready performance with scalable ingestion and low query latency.
Goal
Provide a robust, enterprise‑grade RAG chat system that reliably answers domain‑specific questions by grounding Gemini Pro with AlloyDB vector retrieval—combining precision, speed, and explainability.
Like this project
Posted Jan 12, 2026
Gemini Pro grounded by AlloyDB vector search delivers fast, citation‑backed, context‑rich answers to natural‑language queries at scale.
Likes
0
Views
7
Timeline
Oct 7, 2024 - Mar 11, 2025