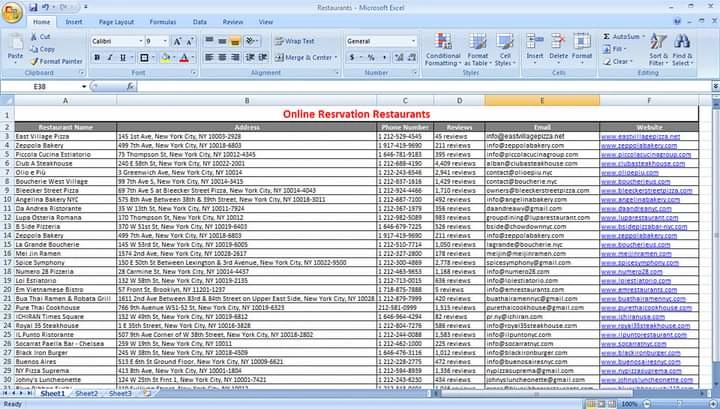
from bs4 import BeautifulSoup
import openpyxl
#! This code reads the daraz.html file and parses it with BeautifulSoup.
# Read the file and parse it with BeautifulSoup
with open('daraz.html', 'r', encoding='utf8') as f:
soup = BeautifulSoup(f.read(), 'html.parser')
# Find all divs with class="inner--SODwy"
divs = soup.find_all('div', class_='inner--SODwy')
# Create a new Excel workbook and select the active sheet
wb = openpyxl.Workbook()
ws = wb.active
# Write the headers to the first row
ws.append(['Product Name', 'Current Price',
'Previous Price', 'Discount', 'Reviews'])
# Loop through all the divs
for div in divs:
# Try to find the product name
try:
product_name = div.find('div', class_='title--wFj93').text
except:
product_name = ''
# Try to find the current price
try:
current_price = div.find('span', class_='currency--GVKjl').text
except:
current_price = ''
# Try to find the previous price
try:
previous_price = div.find('del', class_='currency--GVKjl').text
except:
previous_price = ''
# Try to find the discount
try:
discount = div.find('span', class_='discount--HADrg').text
except:
discount = ''
# Try to find the number of reviews
try:
reviews = div.find('span', class_='rating__review--ygkUy').text
except:
reviews = ''
# Write the data to the Excel sheet
ws.append([product_name, current_price, previous_price, discount, reviews])
# Save the Excel workbook
wb.save('output.xlsx')