Sitemap Validator Tool Build
Bree Sharp
Overview
I built the Sitemap Validator to answer the question many XML validators skip: not just whether a sitemap exists, but whether it is helping search engines discover the right URLs.
A sitemap can be valid XML and still be bad SEO. It can list redirected URLs, blocked URLs, noindex pages, canonical variants, or stale pages that no longer belong in search discovery.
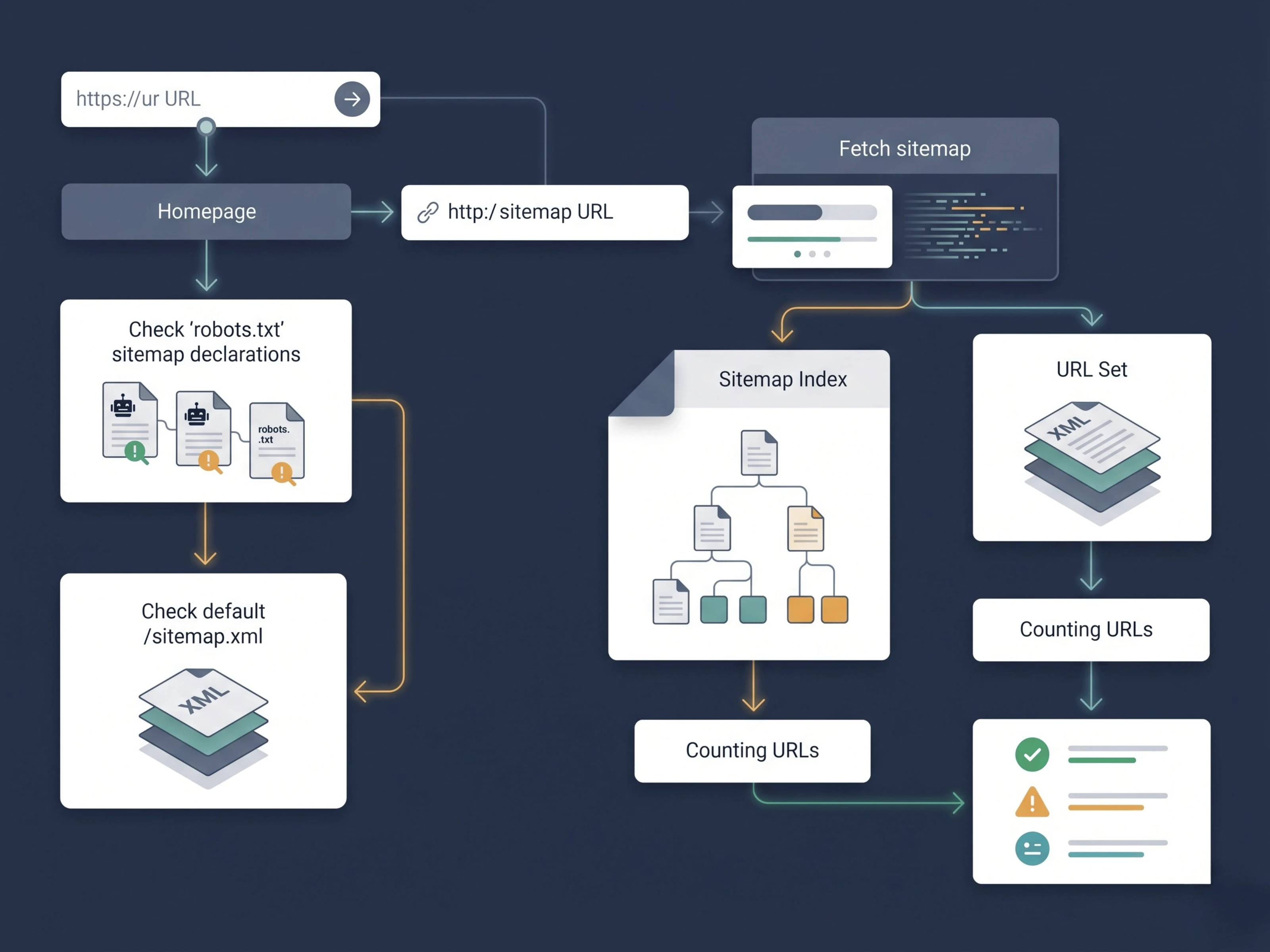
Sitemap Validator overview
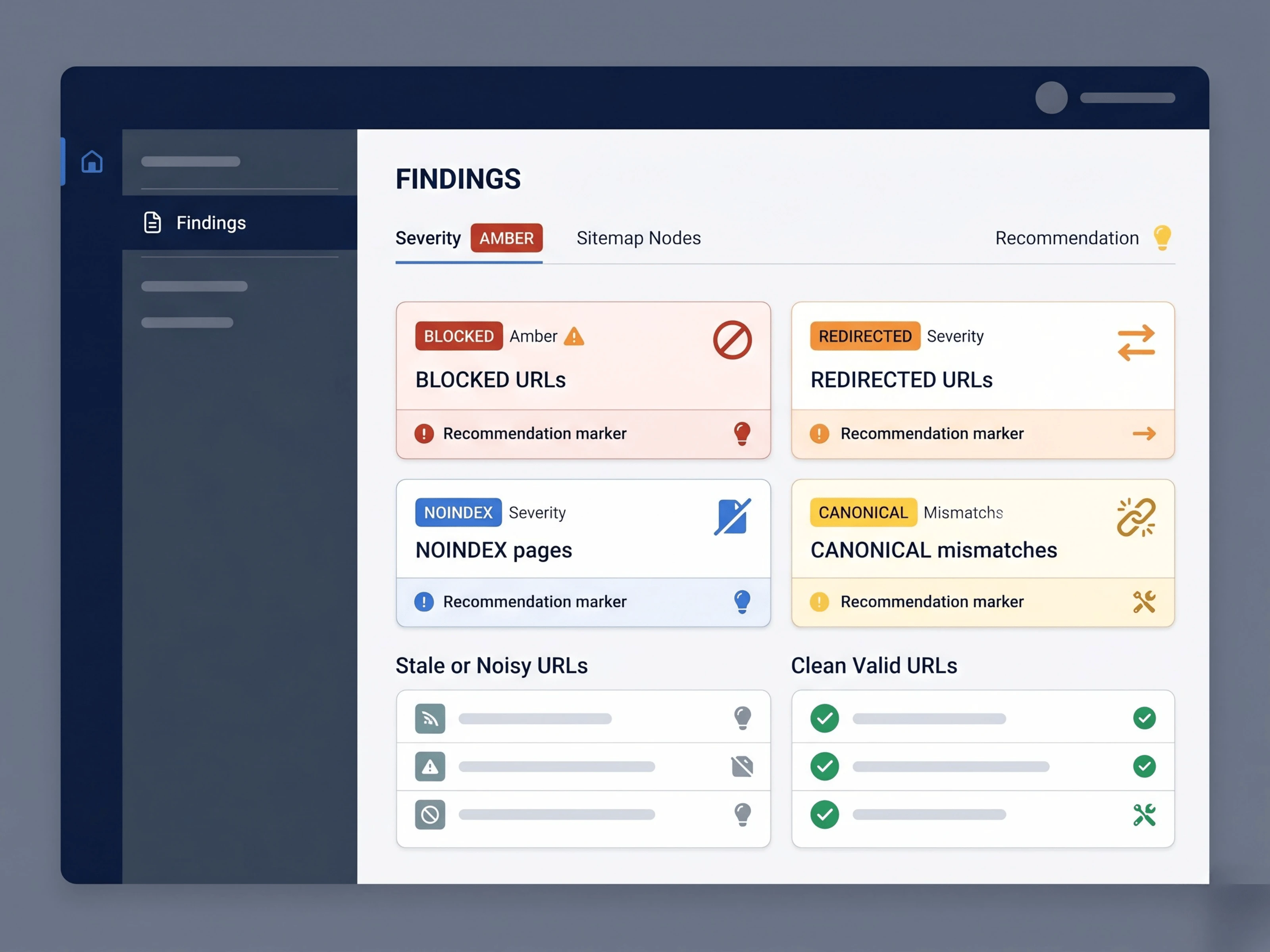
What It Checks
Direct sitemap URLs and homepage-based sitemap discovery
robots.txt sitemap declarations
XML sitemap vs sitemap index structure
URL counts and key sitemap fields
Sampled URL HTTP status and redirects
robots.txt conflicts
noindex tags
canonical mismatches
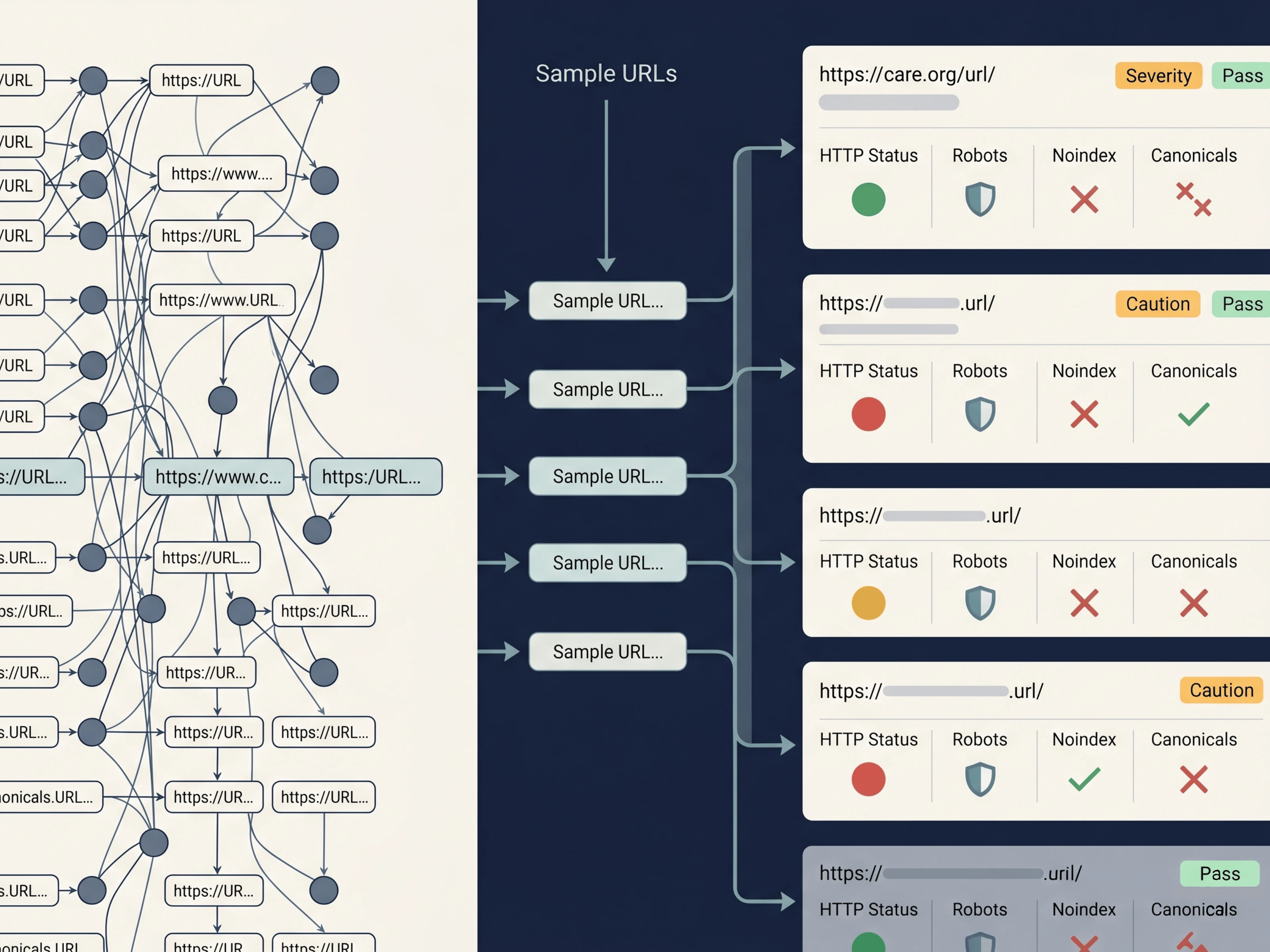
Sitemap Validator checks
Build Decisions
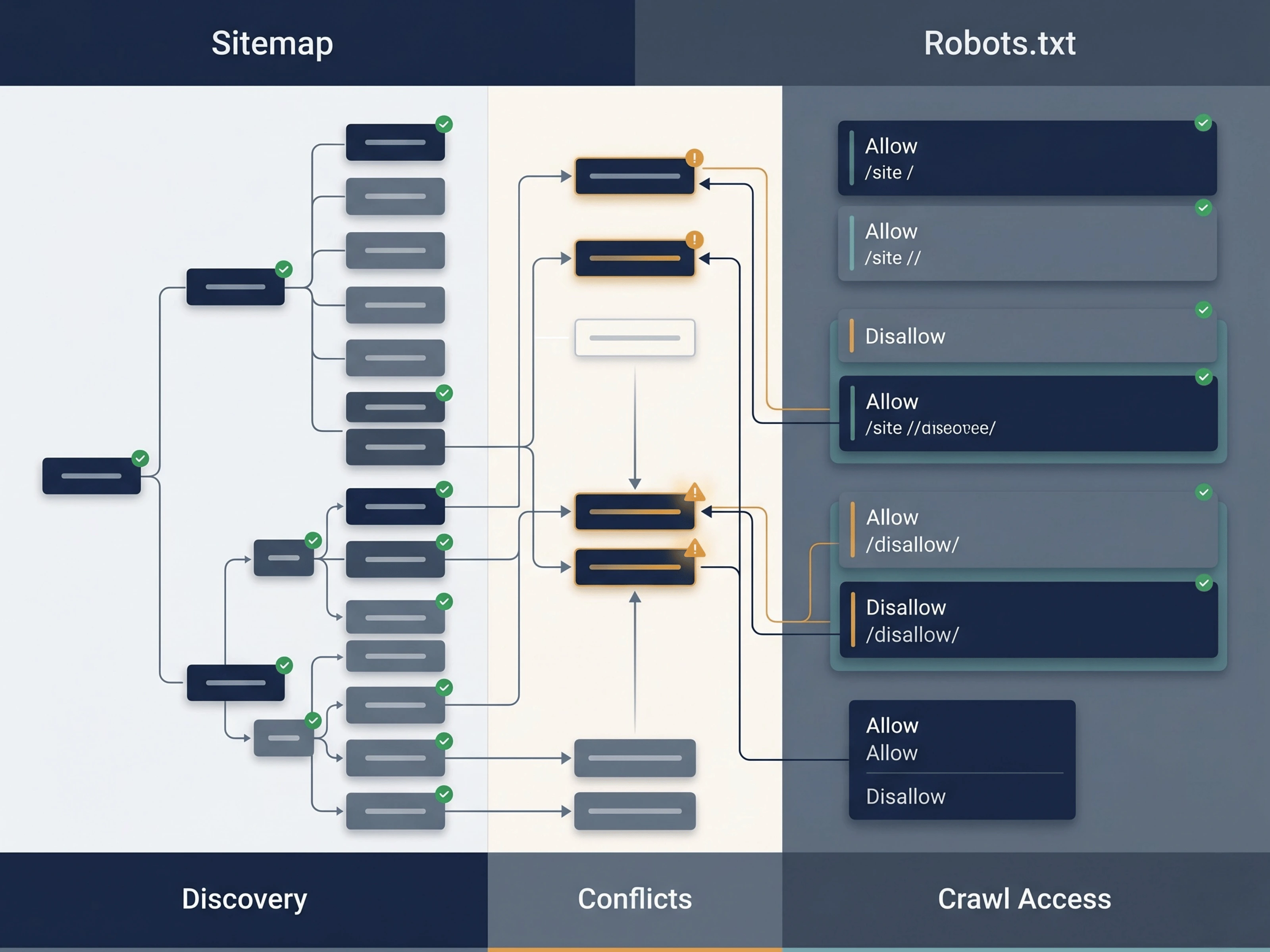
The public tool page runs in Astro, while the validation work happens through a Cloudflare Worker. Users can paste a sitemap URL or a homepage URL. If they start from a homepage, the Worker checks robots.txt first, then falls back to the common /sitemap.xml path.
The validator samples listed URLs instead of pretending every sitemap needs a slow full crawl. That keeps the tool fast for a first-pass audit while still catching the patterns that usually explain sitemap quality problems.
The results are organized by severity so the report points users toward the issues most likely to waste crawl attention or send mixed search signals.
Build decisions
Product Outcome
The tool turns sitemap QA into a repeatable workflow: find the sitemap, identify the structure, sample the listed URLs, and connect XML health with crawl/index signals.
Paired with the robots.txt checker and indexability checker, it forms a practical crawl-discovery suite for technical SEO audits.
Product outcome
Like this project
Posted May 14, 2026
Built a sitemap validator that checks XML health, URL status, robots conflicts, noindex directives, and canonical issues.