Robots.txt Checker Tool Build
Bree Sharp
Overview
I built the Robots.txt Checker as a focused technical SEO utility for answering one common audit question: can this crawler request this specific URL, and which robots.txt rule decides the answer?
Robots.txt can create expensive confusion. A single disallow rule can block important pages, while missing sitemap declarations can make discovery harder than it needs to be.
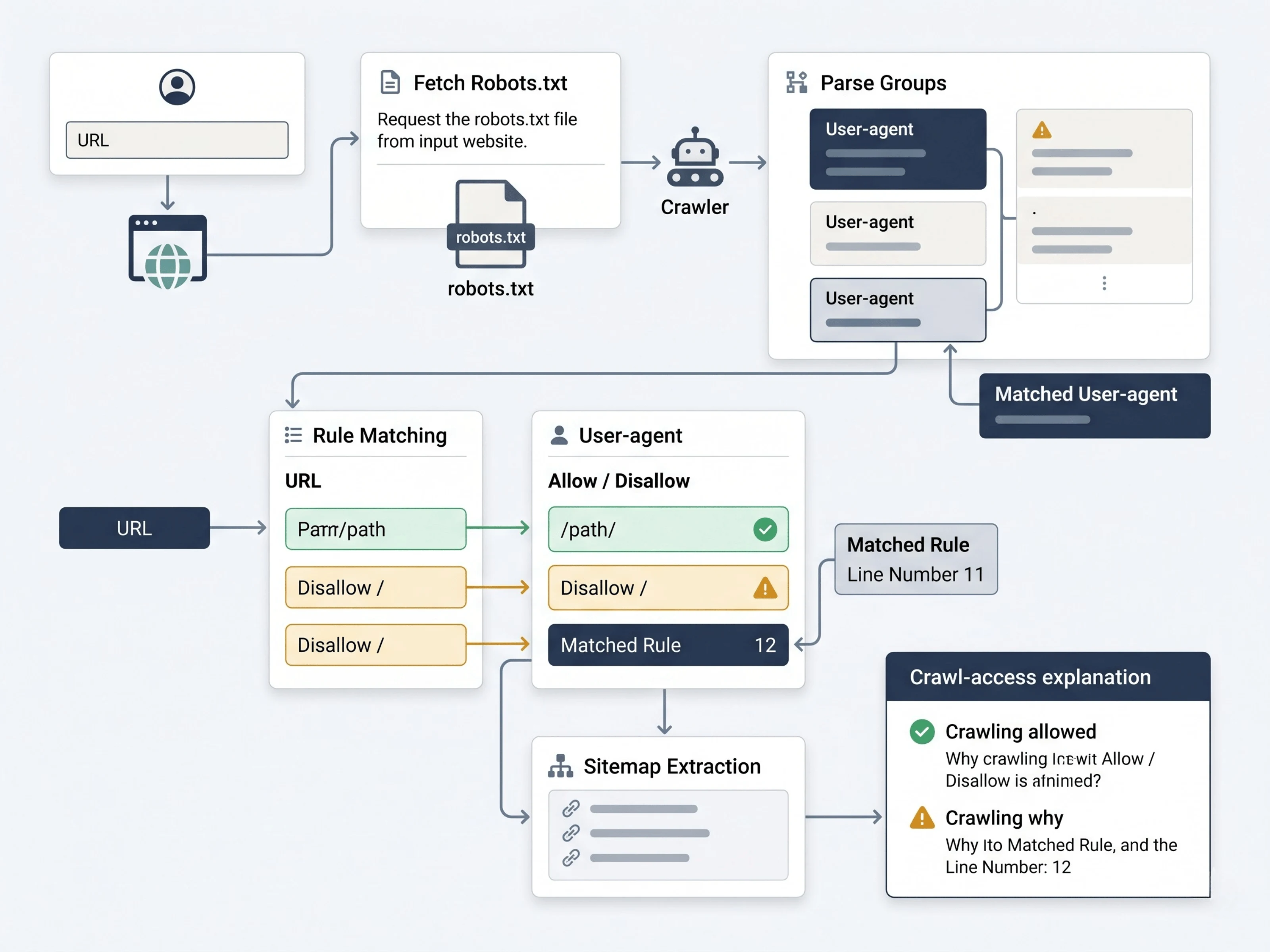
Robots.txt Checker overview
What It Checks
URL status and robots.txt availability
Googlebot, Googlebot-Image, Bingbot, and wildcard user-agent behavior
Matching allow and disallow directives
The deciding robots.txt rule and line reference
Sitemap declarations found in robots.txt
Plain-English crawl guidance for the tested URL
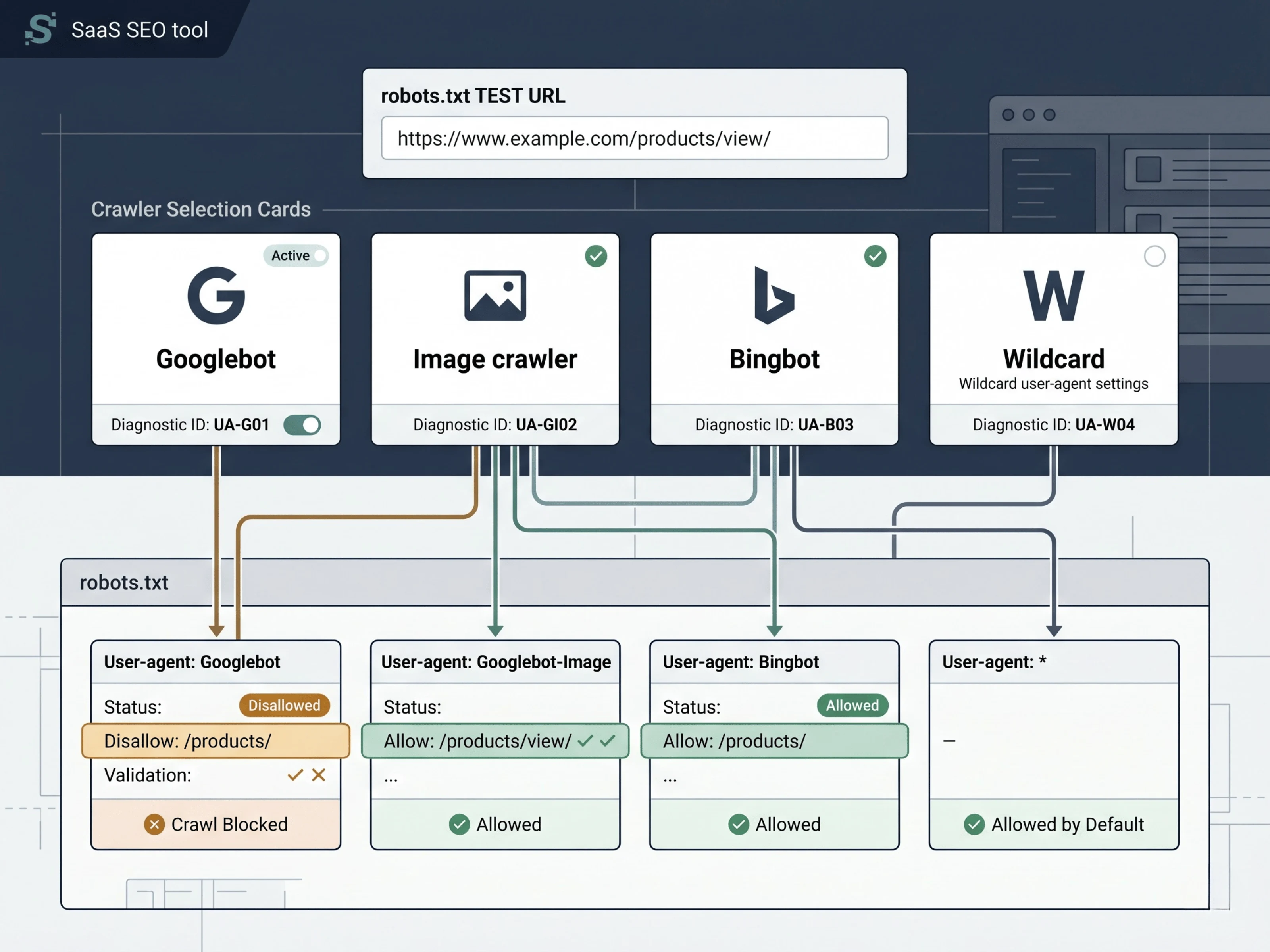
Robots.txt Checker checks
Build Decisions
The public page runs in Astro. The server-side check runs through a Cloudflare Worker, because robots.txt fetching and URL testing need to happen outside the browser for reliability.
The Worker fetches the site's robots.txt file, parses user-agent groups, applies allow/disallow rule matching, and returns the rule that actually controls the result. The UI then explains the outcome without forcing the user to interpret raw directives.
The tool is intentionally narrow. It does not claim a page is indexed, ranking, or guaranteed indexable. Robots.txt controls crawl access. That distinction matters, so the interface keeps the verdict scoped to crawl permission.
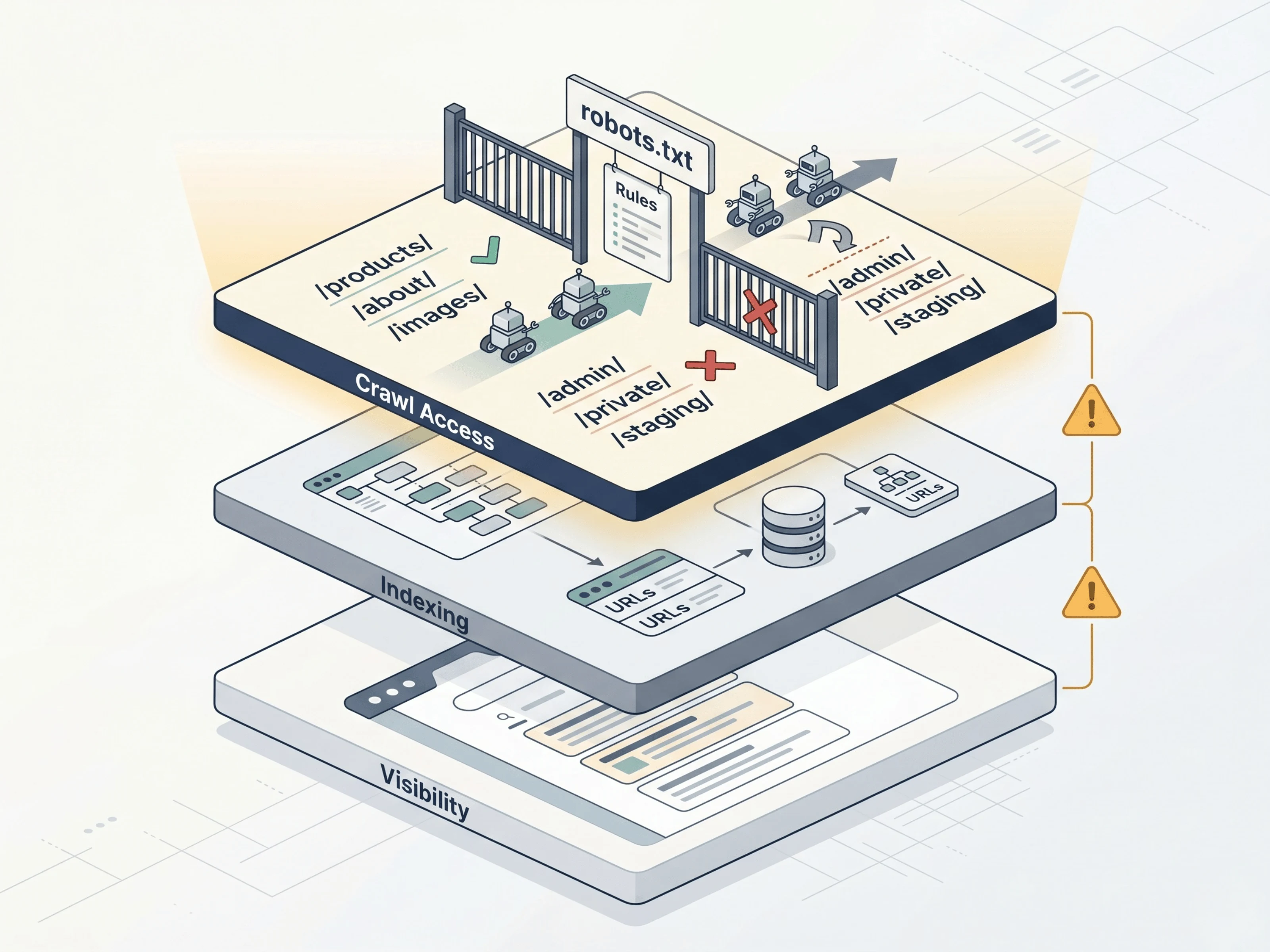
Build decisions
Product Outcome
This turns a small but high-impact SEO check into a repeatable workflow: enter a URL, choose the crawler, see whether it is allowed, and understand which rule caused the result.
Paired with the sitemap validator and indexability checker, it helps connect the crawl-discovery chain: what the site asks crawlers to find, what crawlers may request, and what the page itself tells search engines.
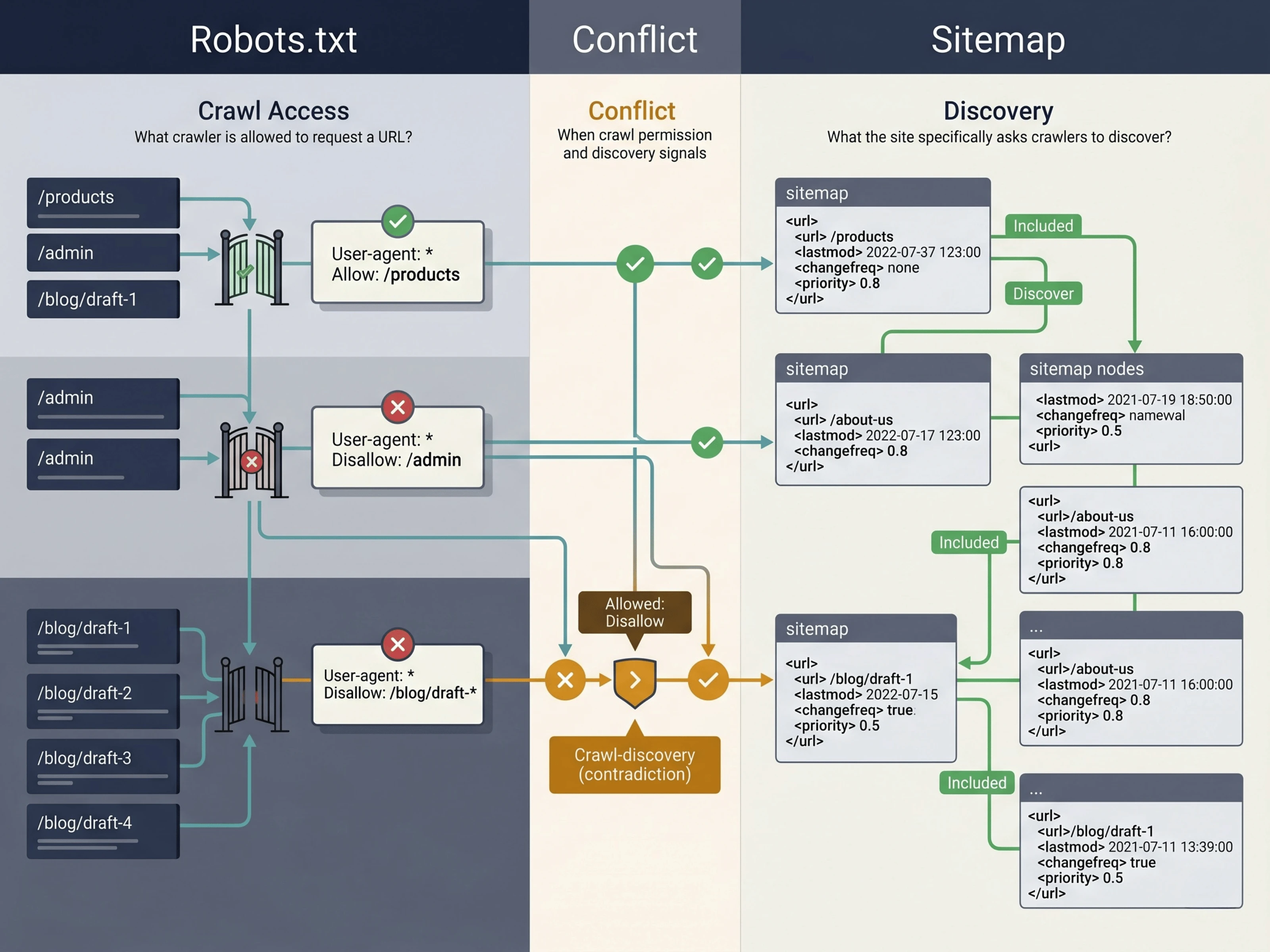
Product outcome
Like this project
Posted May 14, 2026
Built a robots.txt checker that tests crawler access, matched rules, sitemap hints, HTTP status, and plain-English crawl guidance.