Development of Google Maps Data Scraper
Ali Shan
Overview
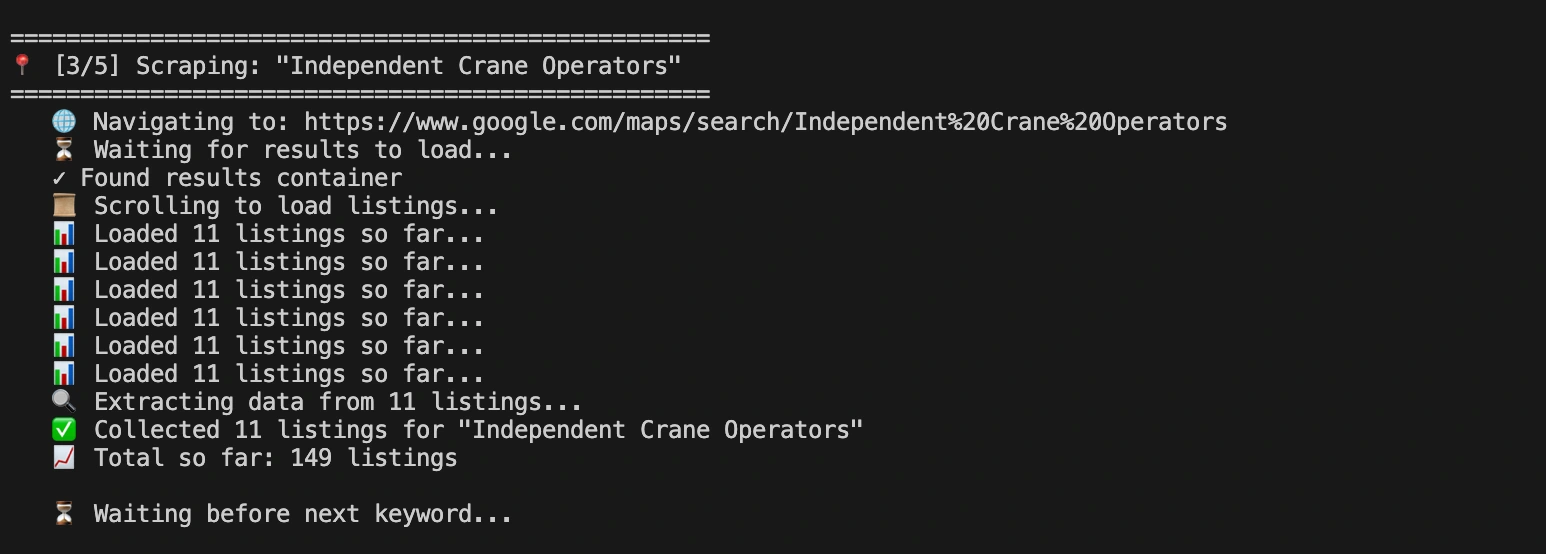
An automated lead-generation tool that scrapes business data from Google Maps and turns it into clean, structured sales leads. I built it in Node.js and TypeScript using Playwright for reliable browser automation, designed to run at scale without tripping detection or breaking on layout changes.
The Challenge
Manually copying business details off Google Maps is slow and error-prone, and naive scrapers get blocked or return messy data fast. The client needed a dependable pipeline that could extract names, contact details, ratings, and locations consistently — and export them in a format the sales team could actually use.
What I Built
A Playwright-driven scraper in Node.js / TypeScript that navigates Google Maps like a real user
Resilient extraction logic that handles dynamic loading, pagination, and layout variation
Clean data normalisation into structured, exportable records (CSV/JSON)
Rate-limiting and anti-detection patterns for stable, repeatable runs
A reusable tool the team can re-point at new locations and search terms
Tech Stack
Node.js, TypeScript, JavaScript, and Playwright.
Outcome
The client replaced hours of manual prospecting with a one-click scraper that delivers clean, structured business leads on demand — feeding the sales pipeline with accurate data pulled straight from Google Maps.
Like this project
Posted Dec 22, 2025
Automated lead-generation scraper built with Node.js, TypeScript & Playwright extracts business data from Google Maps, turning listings into sales leads.