Rewriting tests from Cypress to Playwright using GPT3
Gajus Kuizinas
Cypress and @playwright/test are two competing integration testing frameworks. We have been using Cypress for a long time but recently made a decision to migrate our Cypress tests to Playwright, all 400 of them. It is absolutely worth it for the speed and reliability gains (a future post)... However, it meant a lot of manual work! Or so I thought...
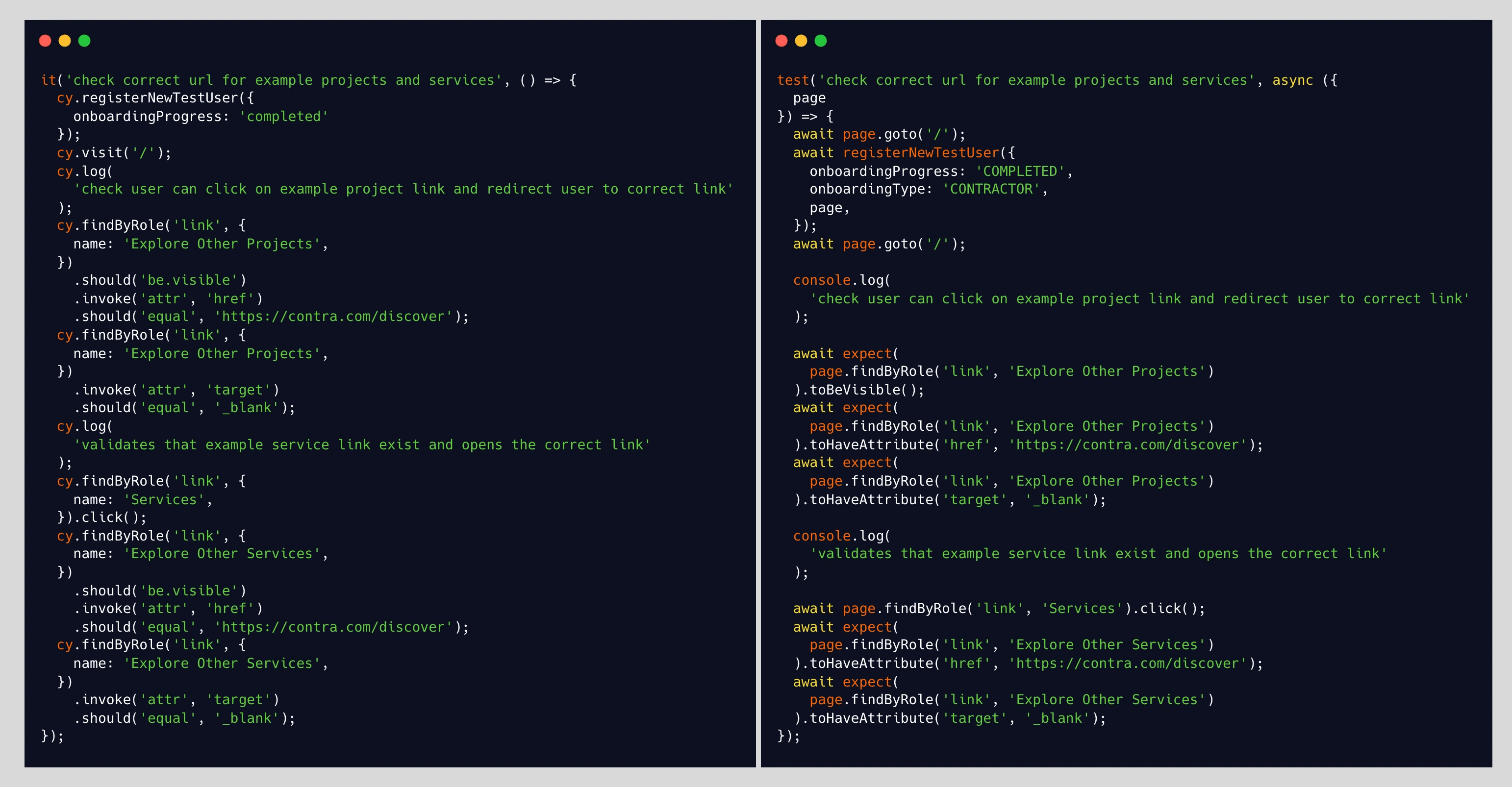
Left: Cypress, Right: Playwright. There are a lot of structural similarities between how both tests are written.
The Discovery
The thought of using GPT3 for rewriting tests came to me while manually rewriting tests and observing GitHub's Copilot suggestions. They were really good. 🤯 So good I made a video and shared it with our team.
As I explain in the video, this was mostly an accidental discovery. Without copying old Cypress tests into the same file, the suggestions were pretty random and not particularly useful. Copilot only started making smart suggestions when I would copy the commented-out Cypress code into an empty Playwright spec file before starting to write the tests.
That day I used Tab (to complete suggestions) more than I have ever used in the past. However, what made Copilot less useful was:
It sometimes worked, and sometimes it didn't
The suggestions became worst as the file size increased
The suggestions lost the context of previous code in a new file
Side note: It was fascinating to reflect on how quickly I got spoiled by these suggestions. The process quickly became [tab] [wait for suggestion] [validate the suggestion] [apply the suggestion].
Knowing that Copilot is implemented using GPT3+Codex, it got me thinking... given that we've already rewritten a handful of the tests manually, how hard would it be to write a prompt for GPT3 that automates (or semi-automates) rewriting tests in their entirety?
I decided to try using OpenAI's Playground.

Of course, using Dalle to generate illustrations for the article.
OpenAI Playground
If you are not familiar with OpenAI's Playground interface, it is basically a text input with a few toggles. You enter an instruction (in a way that your teammate would understand) and watch the API respond with completion that attempts to match the context and pattern you provided, e.g.
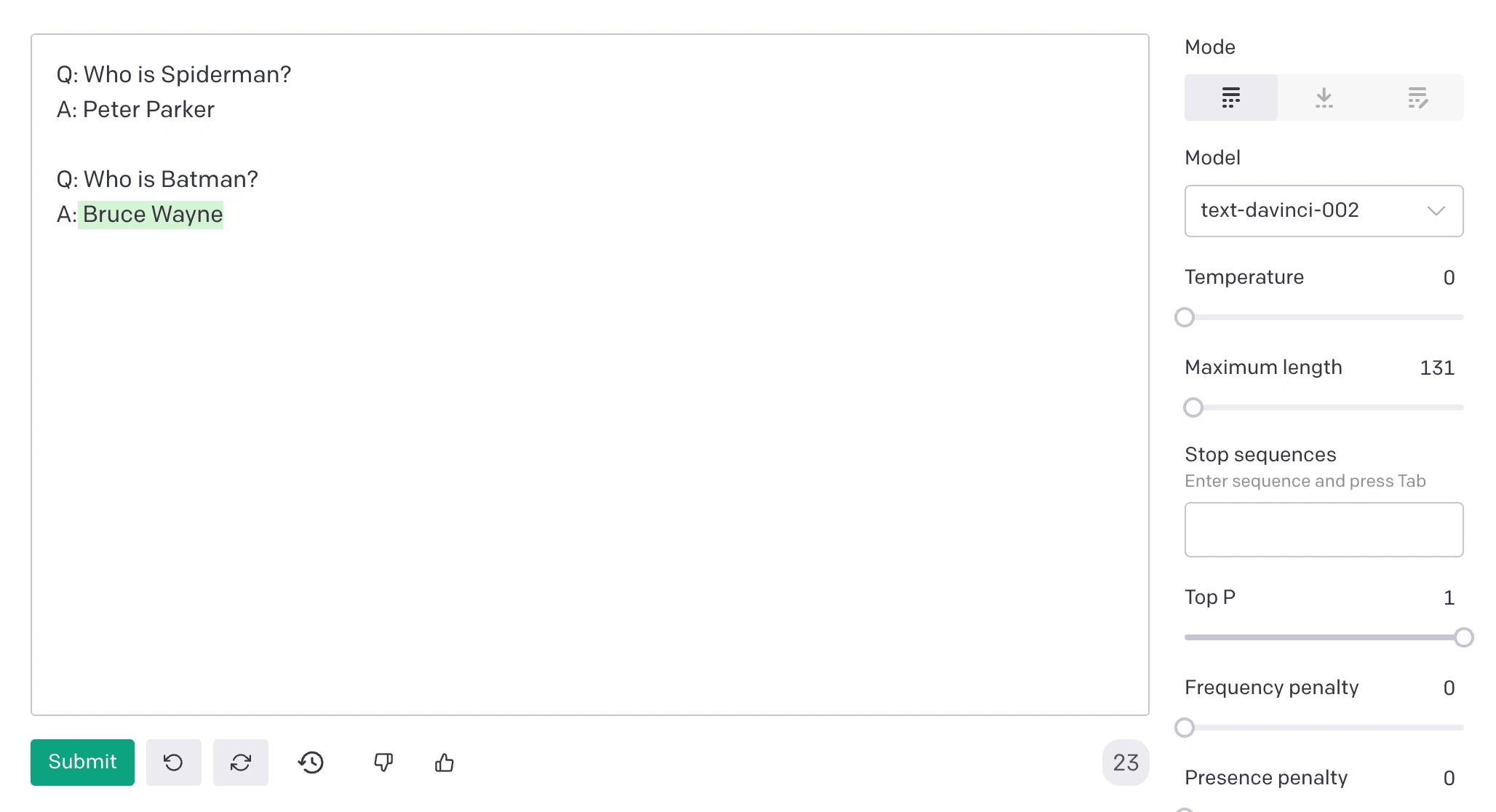
Regular text is a user-entered prompt. Highlighted text is the response.
All I needed was a prompt and a few examples. Here is what I've put together:
I skipped the code examples for the article's brevity, but you can find the complete prompt here.
It is worth noting that the training example is not a valid test (it would fail if executed) but rather a collection of patterns that we use across all tests. Also, to remove any biases, I've used only the tests that we've already migrated by hand for the inputs.
Using just one training example, here are the results, listed in the order of increasing complexity.
A simple test, no new patterns:
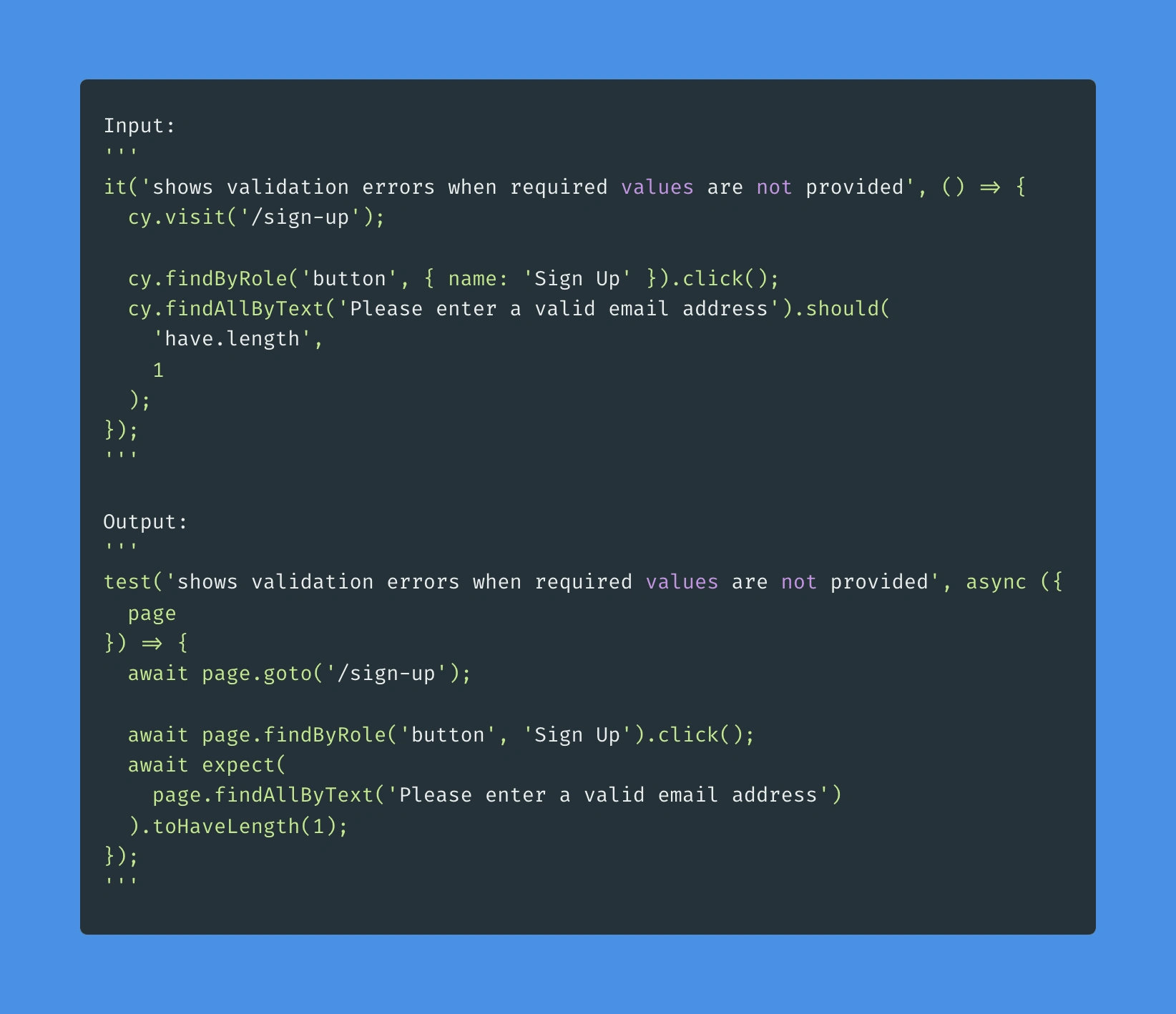
10/10 precisely what I would have written... and what I did write.
The output of the above test is exactly what I've written in our codebase. 🤯
Off to a good start!
A simple test, introducing only a few easy-to-deduce concepts:
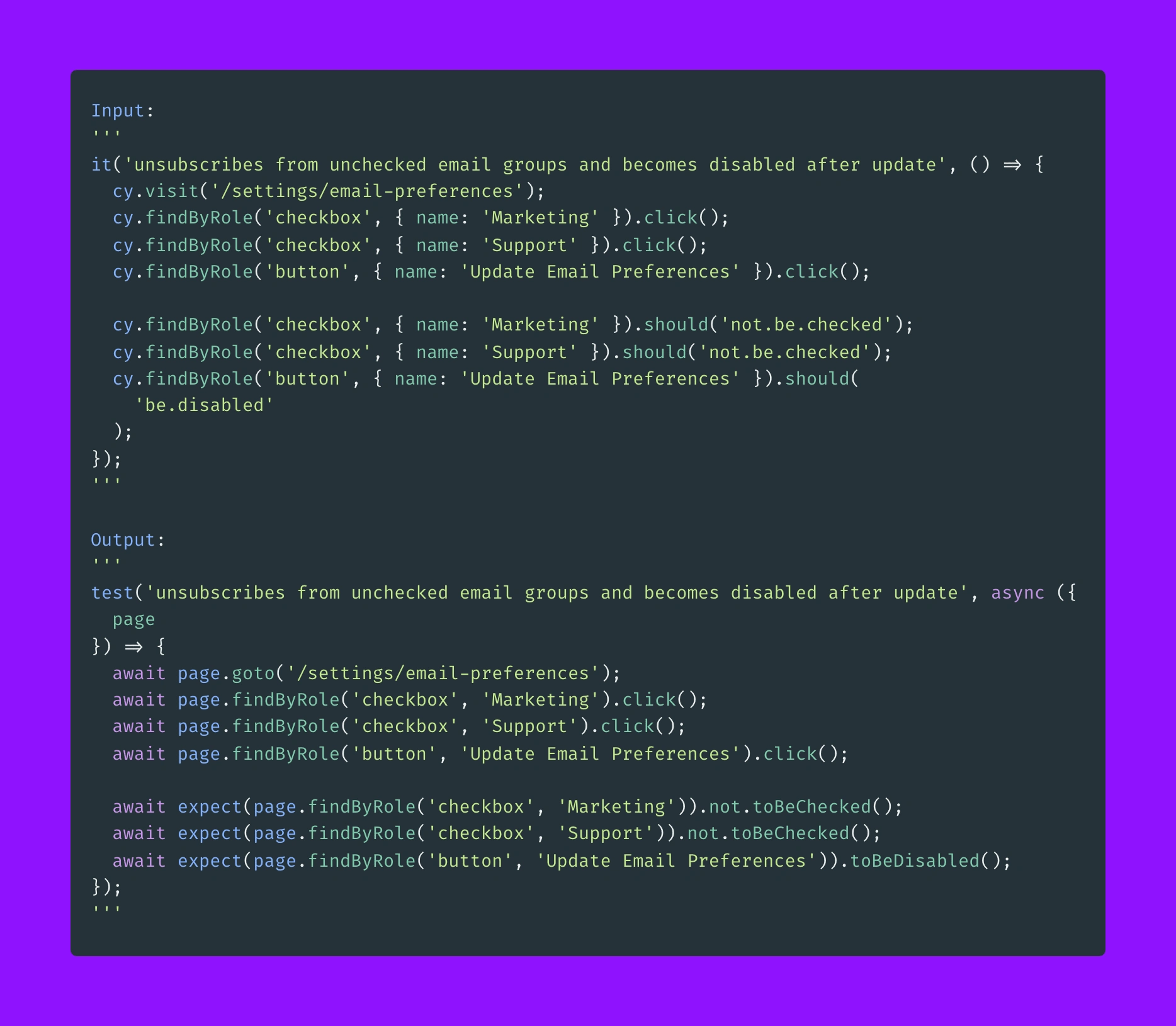
Example input/output #2
And this is what we already had in our codebase. 🤯
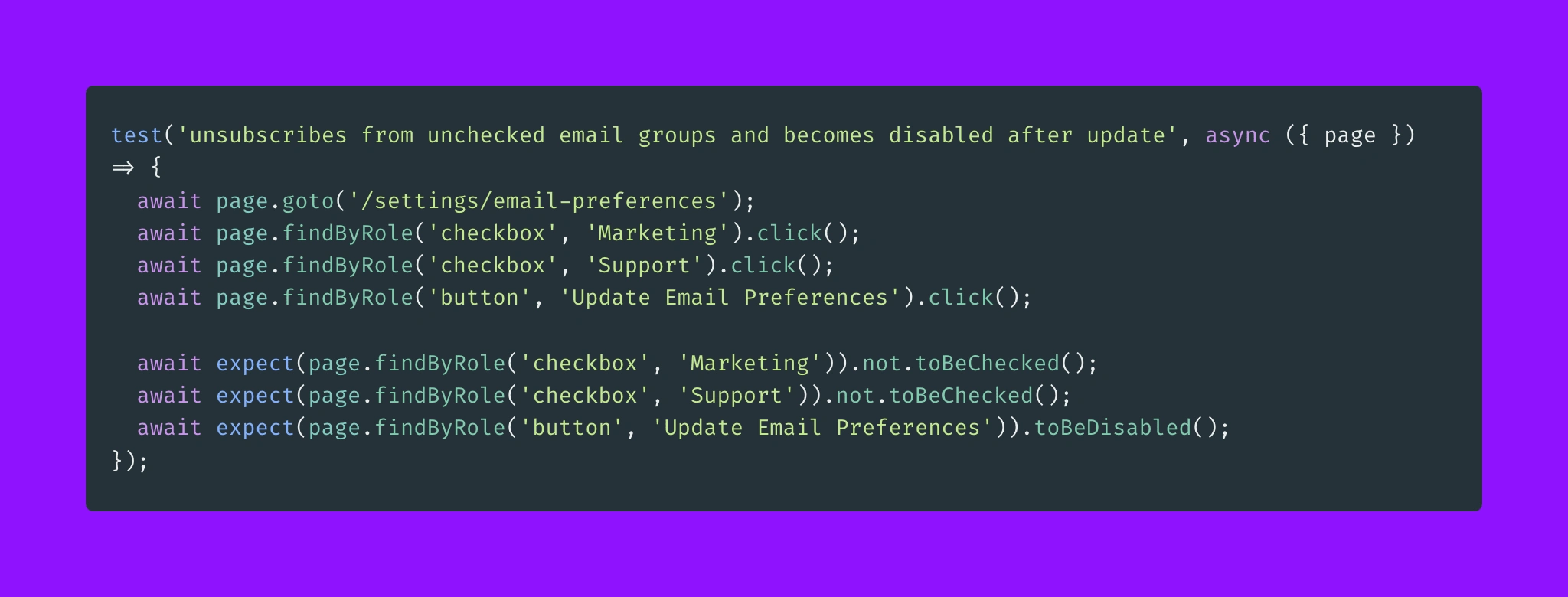
Migration written by us prior to using GPT3.
What is interesting about the above example, is that the training data has never seen toBeChecked or toBeDisabled.
A more complicated test with a bunch of unseen concepts:
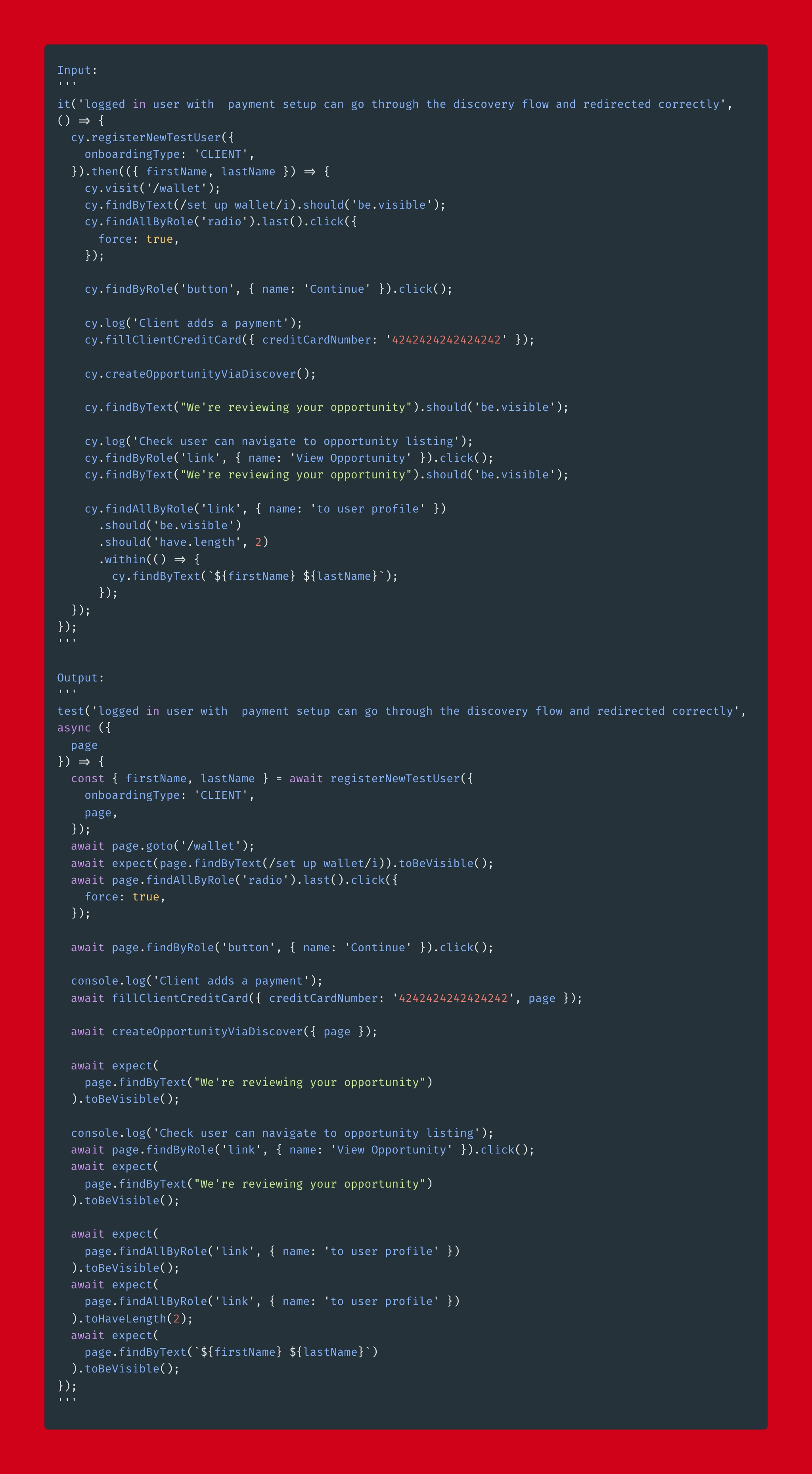
A handful of mistakes, but overall really close!
And in our codebase it was:
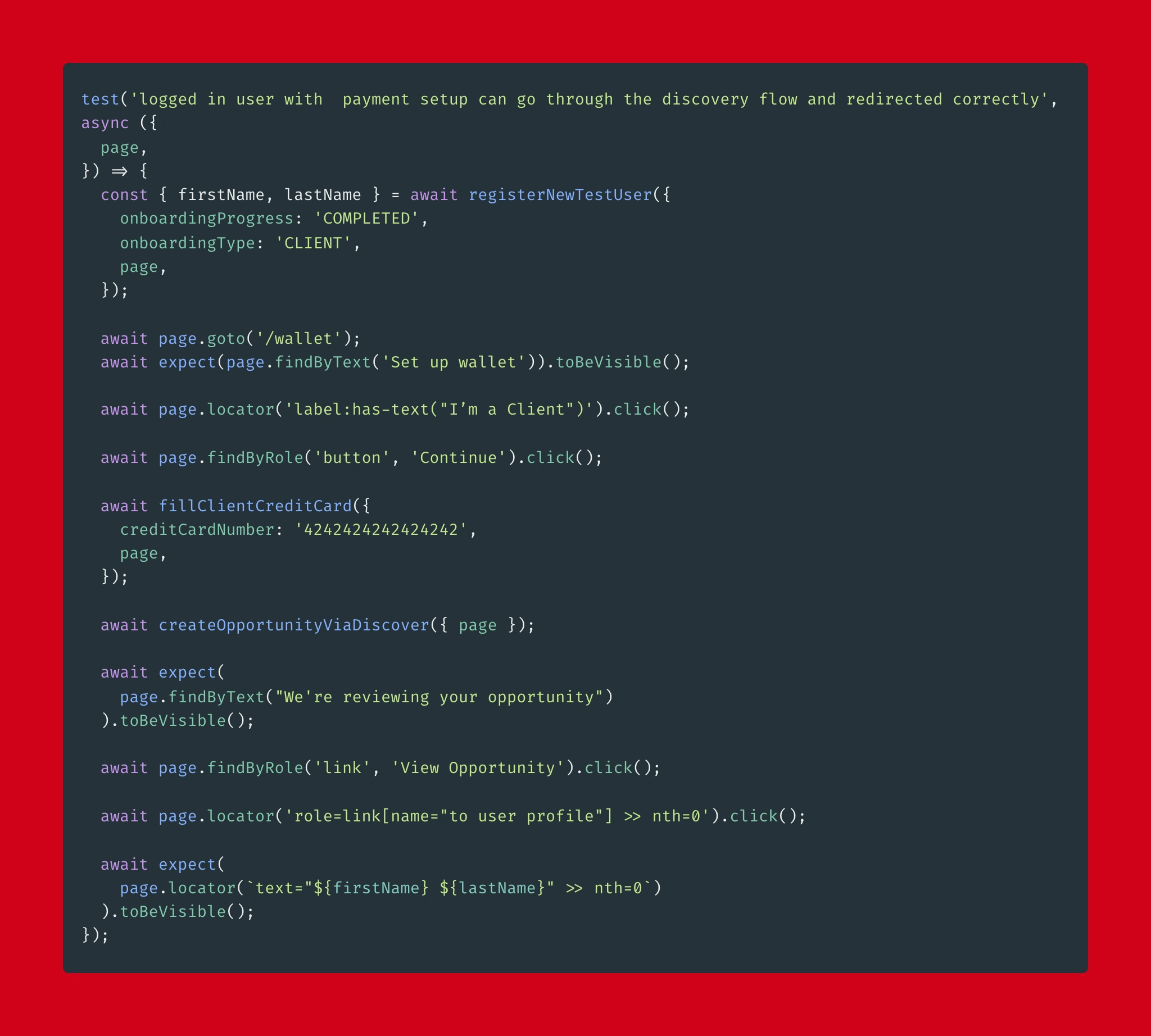
Manually migrated test.
Similar to the purple example, what is really impressive about GPT3 is how it handles scenarios that it has not seen before. The whole registerNewTestUser callback is not something that was available in the training dataset.
The implementation of the last test is quite different. Still, it is mostly because the human migrating the tests made opinionated choices when rewriting the tests (e.g., subsiding nth-based selectors with has-text). Otherwise, they are functionally equivalent.
Overall, this is really cool! It took longer to write this article than to train GPT3 to do something that saves hundreds of hours. In practice, the only time I observed GPT3 give an unexpected suggestion was when it had not seen that pattern/helper before. In those instances, I simply extended the training example with that particular use case example.
For us, this is quite a (pleasant) change to the workflow. As we continue to rewrite the remainder 300~ tests, the workflow is mostly [copy-paste], [evaluate], [apply][, extend training example for new cases].
Watching OpenAI Playground type out the response never gets old!
We will initially migrate all tests mostly following GPT3 suggestions and then go back and look for opportunities to improve.
All in all, this is a very neat application of GPT3 and also a huge time save for our team, and I cannot but feel that we are only scratching the surface of what is possible!
Like this project