A lightweight alternative to Amundsen for your dbt project
Louis Guitton
If you've been using
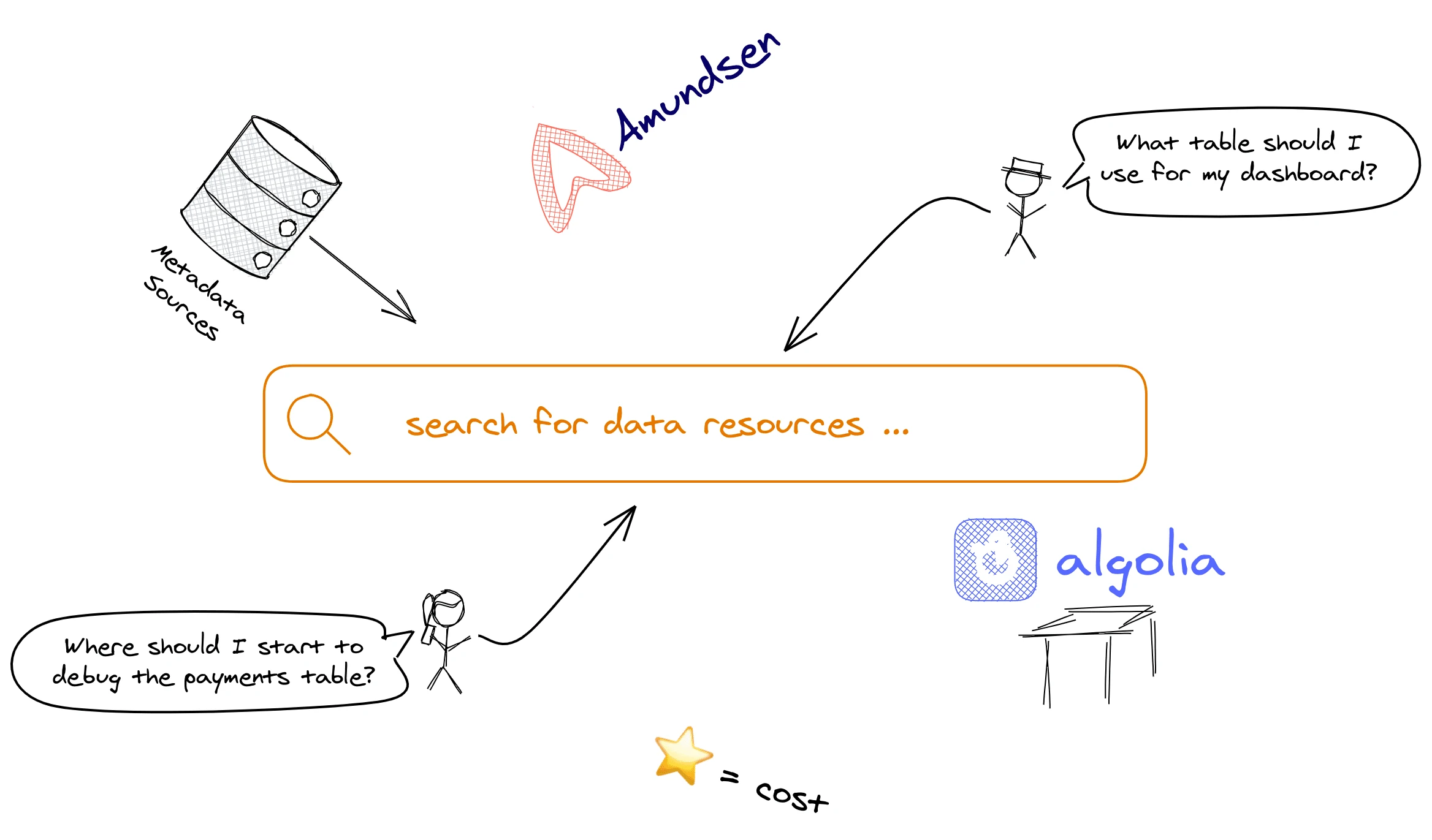
dbt for a little while, chances are your project has more than 50 models. Chances are more than 10 people are building dashboards based on those models.In the best case, self-service analytics users are coming to you with repeting questions about what model to use when. In the worst case, they are taking business decisions using the wrong model.
In this post, I will show you how you can build a lightweight metadata search engine on top of your dbt metadata to answer all these questions. I hope to show you that data governance, data lineage, and data discovery don't need to be complicated topics and that you can get started today on those roadmaps with my lightweight open source solution.
LIVE DEMO: https://dbt-metadata-utils.guitton.co
Data Governance is Ripe
In his recent post The modern data stack: past, present, and future, Tristan Handy - the CEO of Fishtown Analytics (the company behind
dbt) - was writing:He later also points out that dbt has its own lightweight governance interface: dbt Docs. They are a great starting point and might be enough for a while. However, as time goes by, your dbt project will outgrow its clothes. The search in dbt Docs is Regex only, and you might find its relevancy going down with a growing number of models. This can become important for Data Analysts building dashboards and looking for the right model but also for Data Engineers looking to "pull the thread" when debugging a model. Those use cases can be summarised with the two following "Jobs to be done":
Data discovery can solve 2 'Jobs to be Done'
When I want to build a dashboard, but I don’t know which table to use, help me search through the available models, so I can be confident in my conclusions.
When I am debugging a data model, but I don’t know where to start, help me get data engineering context, so I can be faster to a solution.
These days, the solution to those two problems seems to be rolling out "heavyweight" tools like
Amundsen. As Paco Nathan writes p.115 of the book Data Teams by Jesse Anderson (you can find my review of the book here):Amundsen and other heavyweight tools are the go-to solution for data discovery
Those tools come on top of an already complex stack of tools that data teams need to operate. What if we wanted a lightweight solution instead, like
dbt Docs?More on metadata engines
Related tools:
Amundsen (Lyft)
DataHub (LinkedIn)
Metacat(Netflix)
Marquez (Wework)
Databook (Uber)
Dataportal (Airbnb)
Data Access Layer (Twitter)
Lexikon (Spotify)
Other products:
Collibra
Alation
Intermix
data.world
montecarlodata.com
Great resources to go further:
More on self-service analytics
The Features of Amundsen and other Metadata Engines
In his great Teardown of Data Discovery Platforms, Eugene Yan summarizes really well the features of Amundsen and other metadata engines. He splits them in 3 categories: features to find data, features to understand data and features to use data.
Architecture of your friendly neighbourhood metadata engine
Its friendly UI with a familiar search UX is one of the key factors behind Amundsen's success. But another one is its modular architecture, which is already being reused by other metadata open source projects like the project whale (previously called metaframe).
We can further split the 3 categories of features into 10 features of varying implementation difficulty. Those features have also varying returns, not represented here.
Taxonomy of 10 features from metadata engines, cost opinions are my own
The key thing to realise is that Lyft might have spent a 15⭐️-cost on Amundsen to assemble all those features. But what if we wanted to build a 3⭐️-cost metadata engine? What features and technologies would you pick?
2021-02-09 Update: The Ground paper from Rise labs
In the seminal paper Ground: A Data Context Service - RISE Lab, Rise labs have outlined those features with much better terminology that I wasn't aware of at the time of first writing this post: the ABC of Metadata
Application - information on how the data should be interpreted
Behavior - information on how the data is created and used
Change - information on the frequency and types of updates to the data
A Lightweight Alternative to Amundsen
Although it's possible that the feature completeness (everything is in one place) makes the USP of Amundsen and others, I want to make the case for a more lightweight approach.
Documentation tools go stale easily. Or at least in situations where they are not tied with data modeling code. dbt has proven with dbt Docs that data people want to document their code (hi team 😁). We were just waiting for a tool simple and integrated enough for the culture of Data Governance to blossom. It reminds me of those DevOps books showing that the solution is not the tooling but rather the culture (if you're curious check out The Phoenix Project).
Additionally, dbt sources are a great way to make raw data explicitly labeled. The dbt graph documents data lineage for you at the table level and I will leverage later that graph to propagate tags with no additional work.
In other words, with schemas, descriptions and data lineage, dbt Docs covers the category
Features to Understand
from the above diagram. So what is missing from dbt Docs to rival with Amundsen? Only a way to sublime the work that is already happening in your dbt repository. And that is Search.
Algolia market themselves as a 'flexible search platform'
A good search engine will cover the Features to Find category. Fortunately, we don't need to build a search engine. This is where we will use Algolia's free tier in addition to some static HTML and JS files to build our lightweight data discovery and metadata engine. Algolia's free tier allows you for 10k search requests and 10k records per month. Given that for us 1 record = 1 dbt model, and 1 search request = 1 data request from a user, my guess is that the free tier will cover our needs for a while.
Note: if you're worried that Algolia isn't open source, consider using the project typesense.
How to get at least one feature in the Features to Use category? Well, a
dbt project is tracked in version control, so by parsing git's metadata, we can for example know each model's owner.More generally, to extend our lightweight metadata engine, we would add metadata sources and develop parsers to collect and organise that metadata. We would then index that metadata in our search engine. Examples of metadata sources are:
dbt artifacts (_See my post on how to parse dbt artifacts _)
git metadata
BI tool metadata database (e.g. who queries what, who curates what)
data warehouse admin views (e.g. for Redshift:
stl_insert, svv_table_info, stl_query, predicate columns)...
What does good Search look like
Search is going to be key if our metadata engine is to rival with Amundsen, so let's look at Amundsen's docs. We know from their architecture page that they use ElasticSearch under the hood. And we can also read that we will need a ranking mechanism to order our dbt models by relevancy:
A bit further in the docs, we learn that Amundsen has three search indices and that the search bar uses multi-index search against those indices:
We even get examples for searchable attributes for the documents in the tables index:
Presumably, there's not much point in reverse engineering an open source project, so I'll spare you the rest: it also supports search-as-you-type and faceted search (applying filters).
More on search
The Flask Mega-Tutorial Part XVI: Full-Text Search - miguelgrinberg.com: Flask and ElasticSearch
To build this search capability, you could use different technologies. I attended a talk at Europython 2020 from Paolo Melchiorre advocating for using good-old PostgreSQL's full text search. To my knowledge though, you don't get search as you type. This is one of the reasons why people tend to go for ElasticSearch or Algolia. To choose between them, this is then a buy or build decision: more engineering resources vs "throwing money" at the serverless Algolia. As we saw though for our use case, the free tier will be enough so we get the best of both worlds.
Remains the question of structuring our documents for search. Attributes in searchable documents are one of three types: searchable attribute (i.e. matches your query), a faceting attribute (i.e. a filter) or a ranking attribute (i.e. a weight).
Keys in searchable documents are 1 of 3 types
Our searchable attributes will be table names and descriptions.
Our faceting attributes will be "tags" on our models: these could be vanilla dbt tags if you have good ones, or materialisation, resource type or any other key from the
.yml file. Assuming there is a conscious curation effort happening from the code maintainers when they place a model in a folder in the dbt codebase, we can hence use folder names as a faceting attribute too. Lastly, we can use the dbt graph to propagate from left to right the source that models depend on; this will serve as a useful faceting attribute.For ranking attributes, we will build metrics important to us to prioritise tables for our users. Keep in mind that we started with 2 use cases ('Jobs to be Done'), so each persona could benefit from a different metric. For example, for "dashboard builders", the goal could be to downrank the corner case models so that only models that are "central" are used. But for "data auditors", the goal might be to prioritise the models that need attention first. In our case, we will focus on the first persona, and we will use a PageRank-like algorithm (degree centrality as shown in my previous post). This is great at the start of your self-service analytics journey: dashboard builders might not know what are the good tables yet, so a good proxy is to look at which models are reused by your dbt comitters. Later, you could do like Amundsen and rely on the query logs to boost the models that are used the most.
Putting it together in the dbt-metadata-utils repository
I have assembled a couple of scripts in the (work in progress) repository called
dbt-metadata-utils. I will walk through a couple of key parts here, but feel free to check out the full code there, and if you want to use it on your own project, hit me up.All you will need is:
your already existing dbt project in a git repository locally
clone dbt-metadata-utils on the same machine than your dbt project
create one Algolia account (and API key)
create one Algolia app inside that account
run the commands laid out later
For the dbt project, we will use one of the example projects listed on the dbt docs: the jaffle_shop codebase.
I had no clue about Jaffles, and then I used dbt
Create an environment file in which you will need to fill in the values from the Algolia dashboard:
And then run the 4 make commands:
If you navigate to https://localhost:3000, you should see a UI that looks like this:
I didn't dwell on details, but our metadata engine's features are:
search as you type by table name, table descriptions, the model's folder in the dbt codebase, or its sources
uses DAG algorithms to propagate tags using the loader and sources keys from the dbt .yml files
faceted search by those tags
ranking by degree-centrality, and by boosting dbt models that are in a mart or have a docs description
enrich the tables documents with git metadata parsed from the git repository using the python git client
advanced search using dynamic filtering: if you enter a query with a loader (e.g. "airflow payments"), it will use rules to filter documents with loader=airflow
Conclusion
LIVE DEMO: https://dbt-metadata-utils.guitton.co
There you have it! A lightweight data governance tool on top of dbt artifacts and Algolia. I hope this showed you that data governance doesn't need to be a complicated topic, and that by using a knowledge graph of metadata, you can get a head start on your roadmap.
Leave a star on the github project, and let me know your thoughts on twitter. I enjoyed building this project and writing this post because it lies at the intersection of three of my areas of interest: NLP, Analytics and Engineering. I cover those three topics in other places on my blog.
Resources
Like this project
Posted Aug 23, 2024
In this post, I'll show you how to build a lightweight data catalog on top of dbt artifacts using Algolia.
Likes
0
Views
23



