Build A Custom AI Based ChatBot Using Langchain, Weviate, and S…
Sriniketh J

As multiple organizations are racing to build customized LLMs, a common question I have been asked is — what are the tools out there to streamline this process?
In this article, I show you how to build a fully functional application for engaging in conversations through a chatbot built on top of your documents. This application employs the power of ChatGPT/GPT-4 (or any other large language model) to extract information from document data stored as embeddings in a vector database, and Langchain for prompt chaining. Here’s a preview:
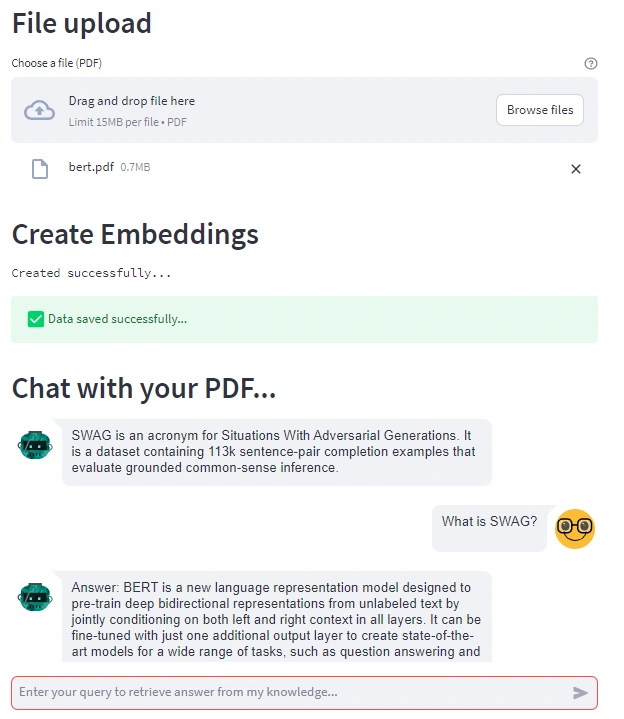
| Skanda Vivek
So let’s dive in!
Building the app🏗️
First, create a new folder named `app` where the source code for the application resides. This acts as the entry point for the streamlit application. Then create folders that perform different tasks like extracting text from PDF, creating text embeddings, storing embeddings, and finally — chatting. The `app` directory looks like this:
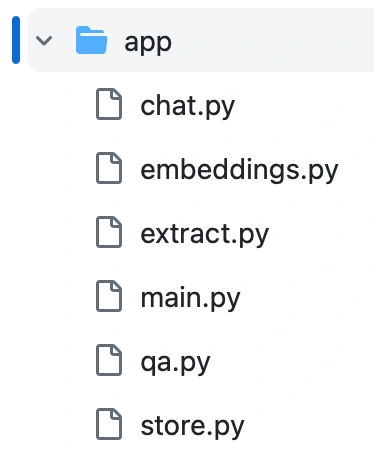
App Directory Structure | Skanda Vivek
PDF Upload
Upload a PDF and extract text for further processing.
from PyPDF2 import PdfReader
import streamlit as st
@st.cache_data()
def extract_text(_file):
"""
:param file: the PDF file to extract
"""
content = ""
reader = PdfReader(_file)
number_of_pages = len(reader.pages)
# Scrape text from multiple pages
for i in range(number_of_pages):
page = reader.pages[i]
text = page.extract_text()
content = content + text
return content
Code Link:
Like this project
Posted Aug 23, 2023
A streamlit app that enables users to interact with the uploaded PDF. You can ask questions or doubts regarding the PDF and our Chatbot would answer them.
Likes
0
Views
29
Clients
Streamlit