AI-Driven Fraud Detection System for Hospital Claims
Jijo Maitra
Fraud, Waste & Abuse Detection for Hospital Claims
Thirty minutes per case. Every case. No exceptions.
That was the baseline when I joined. Every fraud, waste, and abuse review in hospital claims required an analyst and a doctor to manually work through the same stack: invoices, item lists, diagnosis notes, tariff books, drug pricing references, and insurance policy conditions. Analysts checked whether the numbers were right. Doctors checked whether the medicine made sense. Neither had a tool that did any of this for them.
The workflow depended entirely on individual expertise. A senior analyst could spot a price markup instinctively. A junior one might miss it entirely. There was no system to close that gap, which meant detection quality was inconsistent, the learning curve was steep, and as claim volume grew, the team could not keep up.
The volume made consistency impossible. The learning curve made scaling expensive.
The breaking points
01 — Review time that could not shrink
Every case took 30 minutes minimum because every line item, every diagnosis code, every drug reference had to be checked manually. There was no triage. Reviewers started from a blank document every time.
02 — Expertise that could not be transferred
Detection quality varied by reviewer. What a senior analyst caught in two minutes could take a junior analyst twenty. There was no mechanism to systematize that knowledge or apply it consistently at scale.
03 — Two roles, one broken workflow
Analysts and doctors had fundamentally different jobs inside the same claim but were reviewing the same documents in the same unstructured way. Neither had a view tailored to what they actually needed to decide.
Discovery: mapping where fraud actually appears
I led the discovery process by interviewing analysts and doctors directly, mapping how fraud patterns appeared in daily operations rather than in theory. The goal was not to understand what the workflow was supposed to be. It was to understand what actually happened when a reviewer opened a case.
What I found was that the highest-value catches — duplicate bookings, mismatched patient details, unjustified procedures, price markups — all had signals that could be detected automatically before a human ever looked at the file. The reviewers were not doing analysis first. They were doing extraction first, then analysis. The extraction was the bottleneck.
The full claim workflow mapped during discovery. Every branching path became a design requirement
A two-layer system built around how each role actually works
The solution was a two-layer AI-assisted workflow where the system does the extraction and humans do the judgment.
Layer one — Pricing and policy review for analysts.
Automated comparison runs against live tariff books and drug pricing databases before the analyst opens the case. The analyst arrives at a pre-filtered list of flagged anomalies, not a raw document. Every flag includes the reference it was checked against so the analyst can verify rather than re-research.
Layer two — Clinical relevance review for doctors.
The AI surfaces questionable procedures, lab tests, and medications based on ICD codes and clinical logic before the doctor reviews. Doctors see only the items that warrant their attention, grounded in structured clinical data rather than freeform notes.
Both layers feed into the same case but the views are entirely separate. Each reviewer sees exactly what their role requires and nothing else.
Inside a claim: three stages, every check automated
Once a reviewer opens a case, the workflow moves through three structured stages: Claim Eligibility, Monitor Progress, and Final Claim. Each stage has a defined scope. Nothing bleeds into the next until the current stage is resolved.
Stage 1 — Claim Eligibility
The first thing the system checks is whether the claim should exist at all. AI validates the claim against policy conditions: waiting period, blacklist status, policy coverage, and claim history. The result is surfaced immediately before any document review begins.
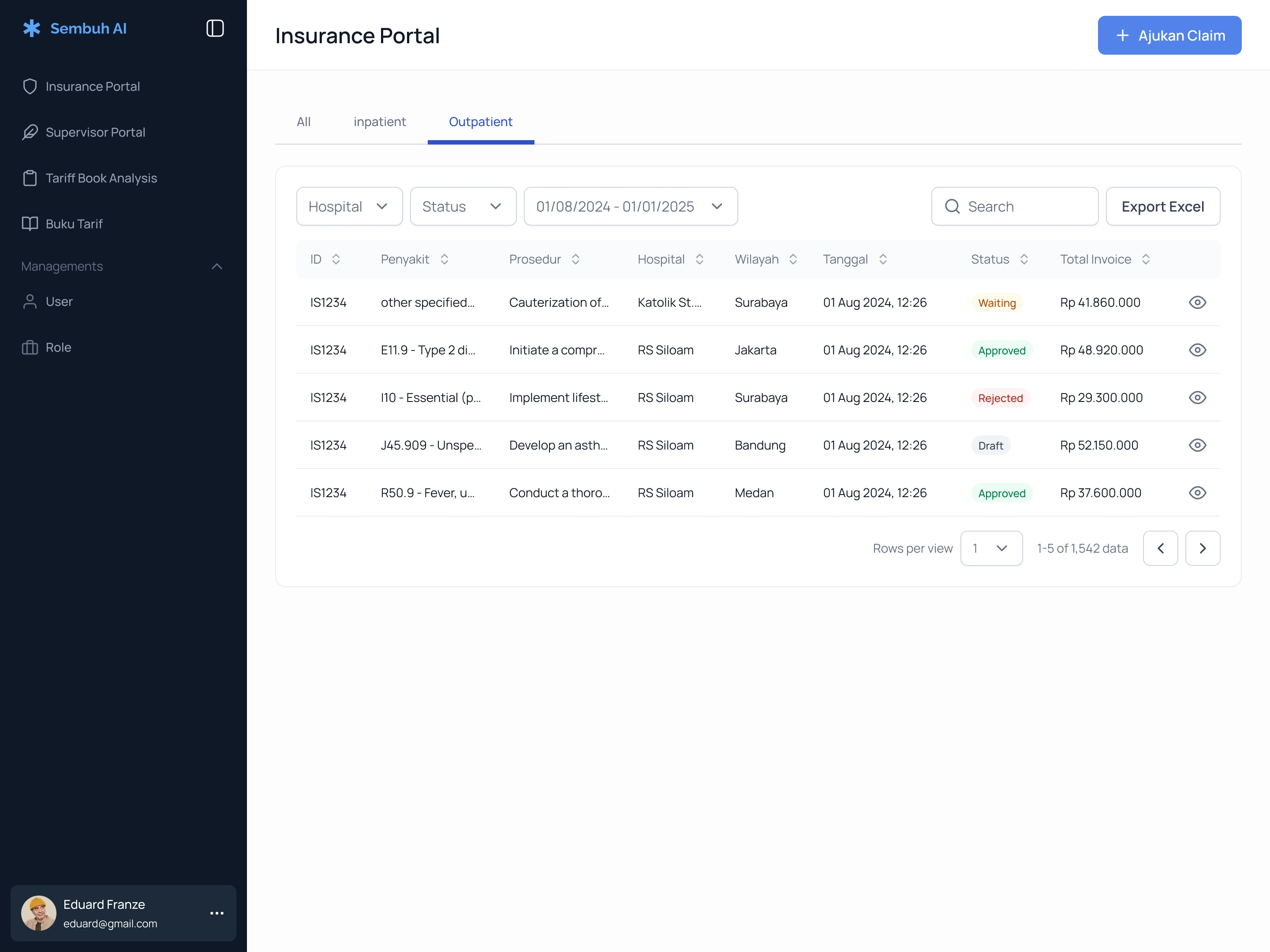
The analyst entry point. Claims organized by type, status, hospital, and region for immediate triage
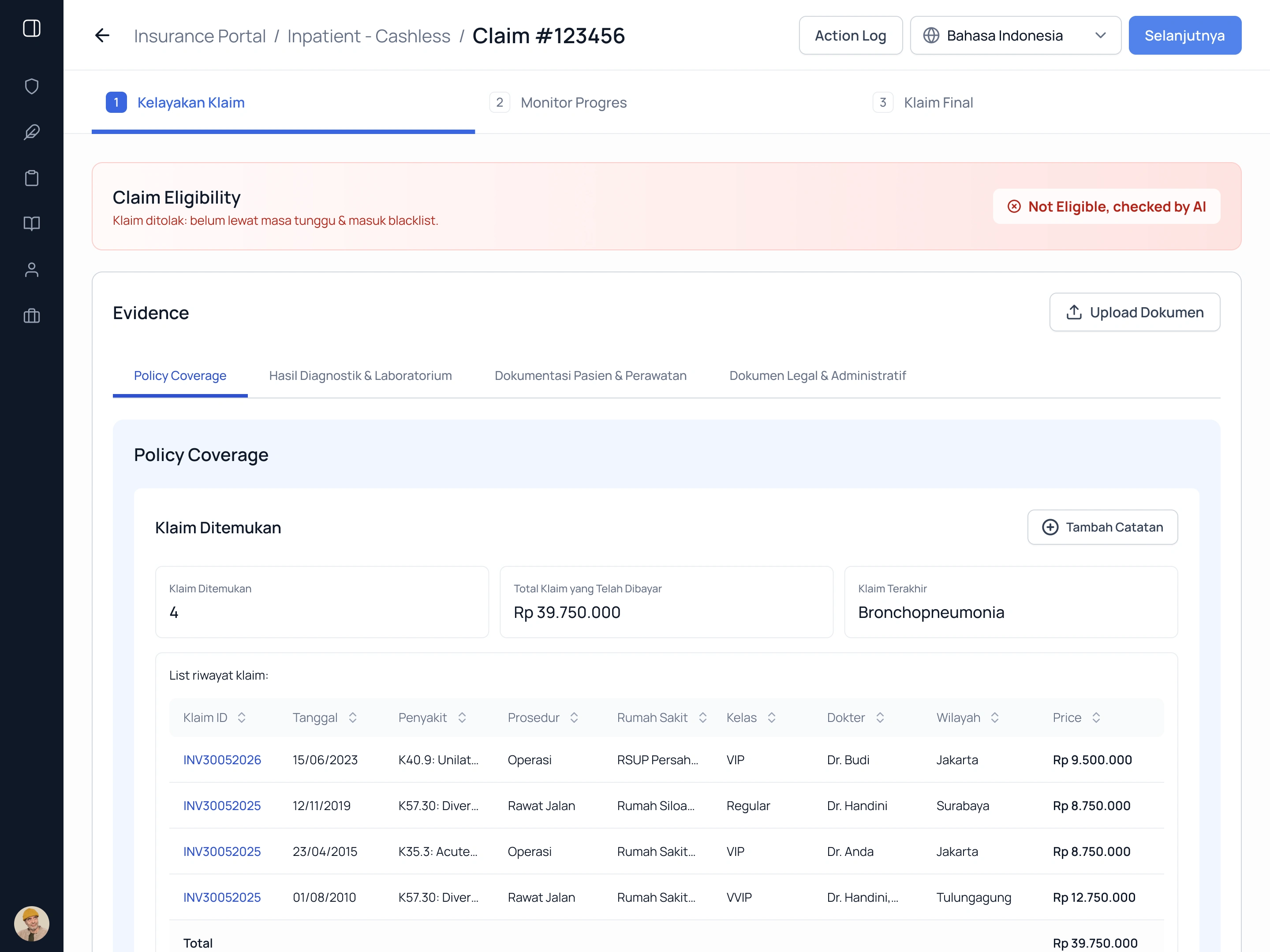
AI flags the claim as not eligible before a human reviews a single document
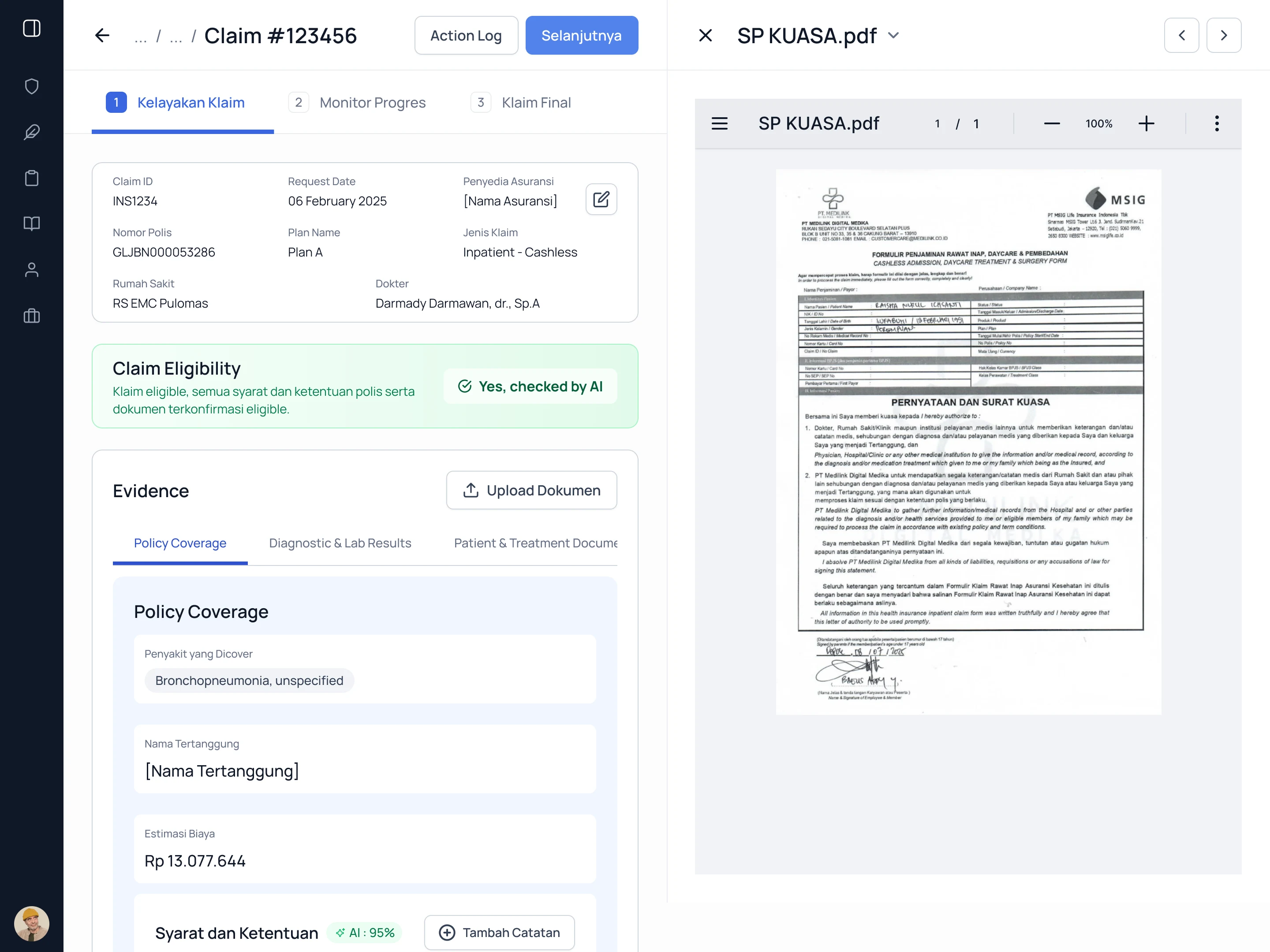
When eligible, uploaded documents sit alongside structured claim data. No tool switching
Stage 2 — Monitor Progress
During the active claim period, the system tracks costs in real time against the policy benefit table and flags any line items that deviate from expected ranges.
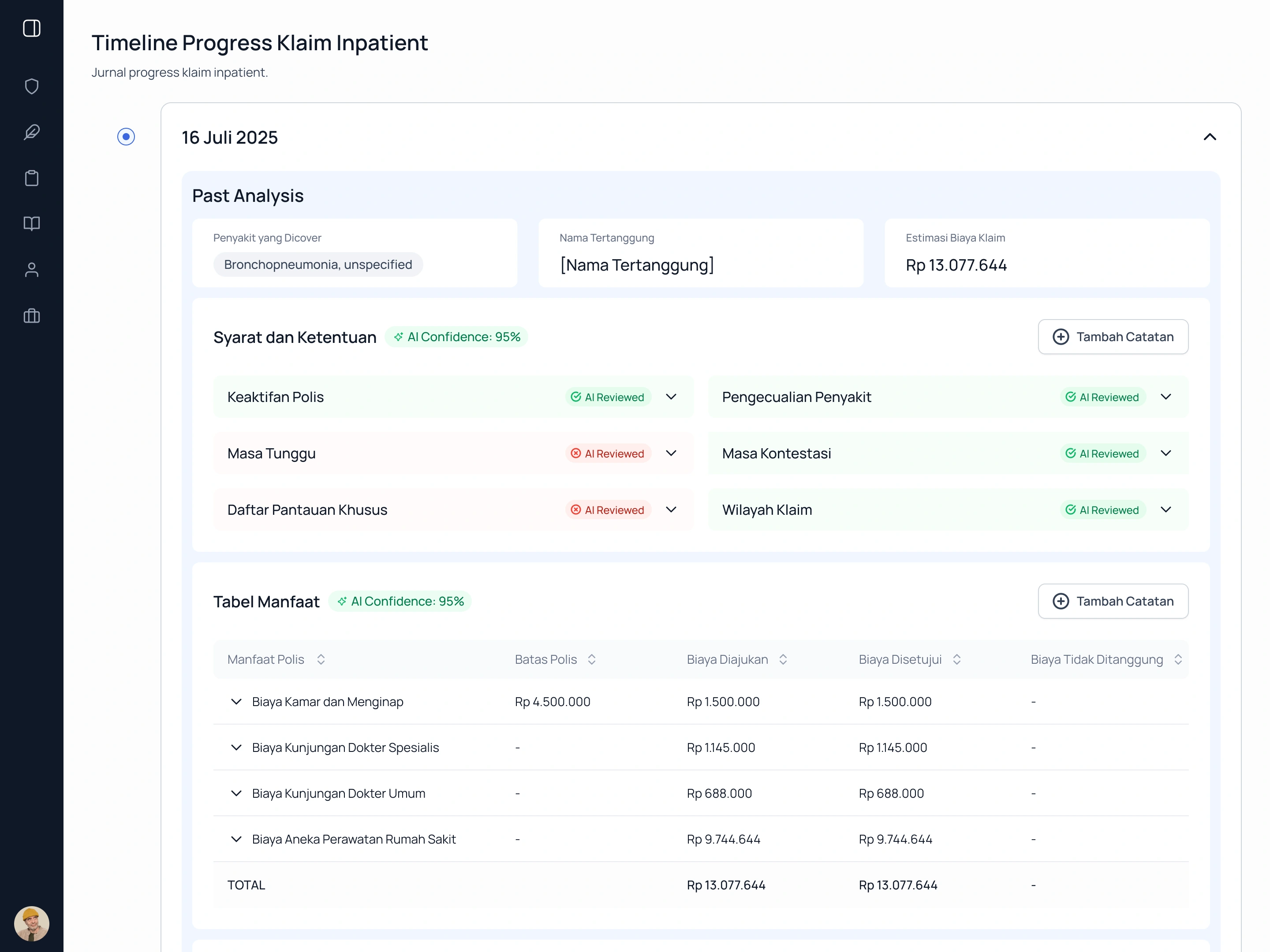
Policy conditions checked automatically and marked AI Reviewed. Costs tracked against coverage in real time
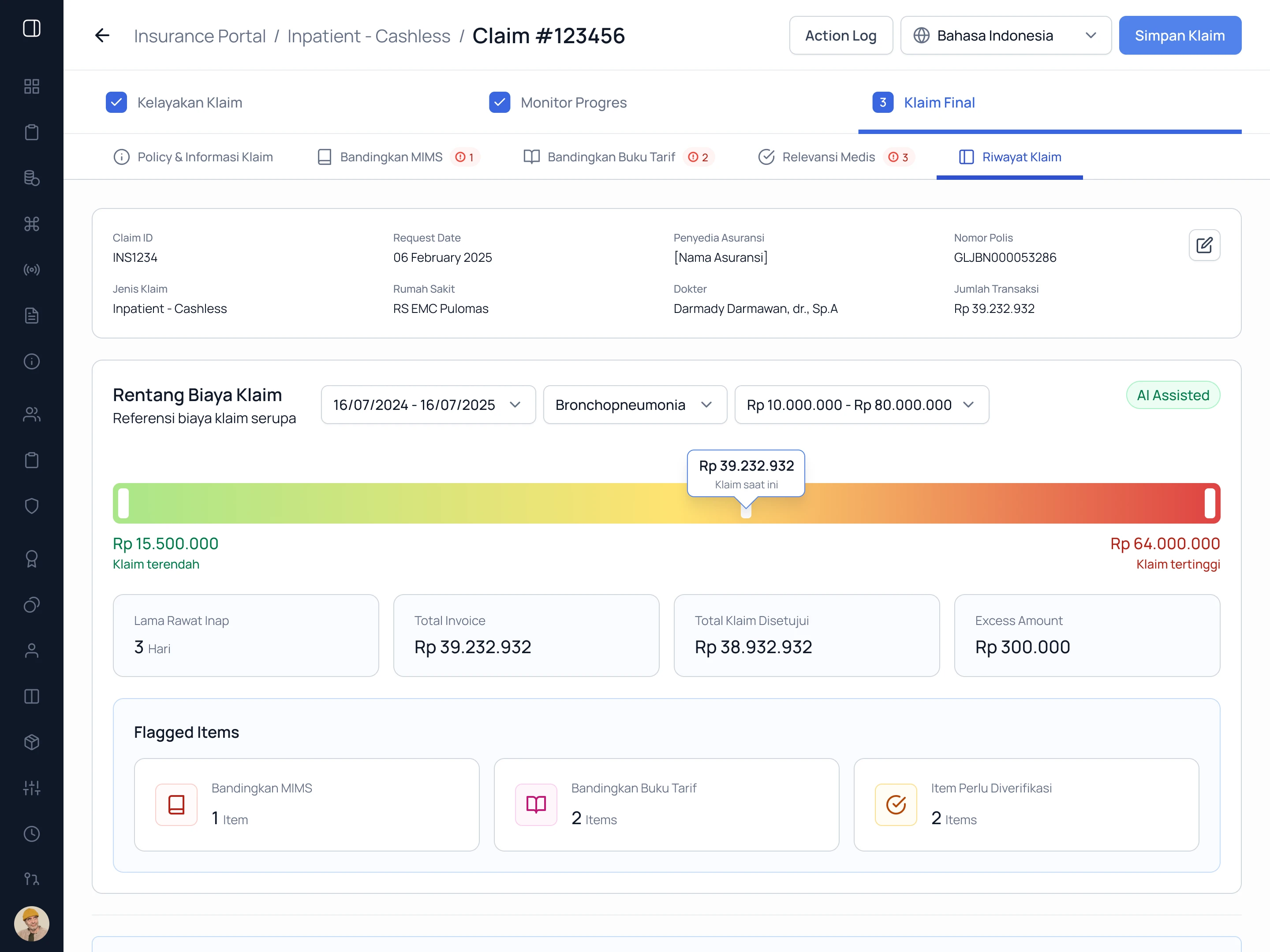
Stage 3 — Final Claim
The final stage consolidates all flags across the claim. Drug pricing anomalies, tariff book deviations, and clinical relevance issues are presented in a single summary with individual item-level flags for analyst and doctor sign-off.
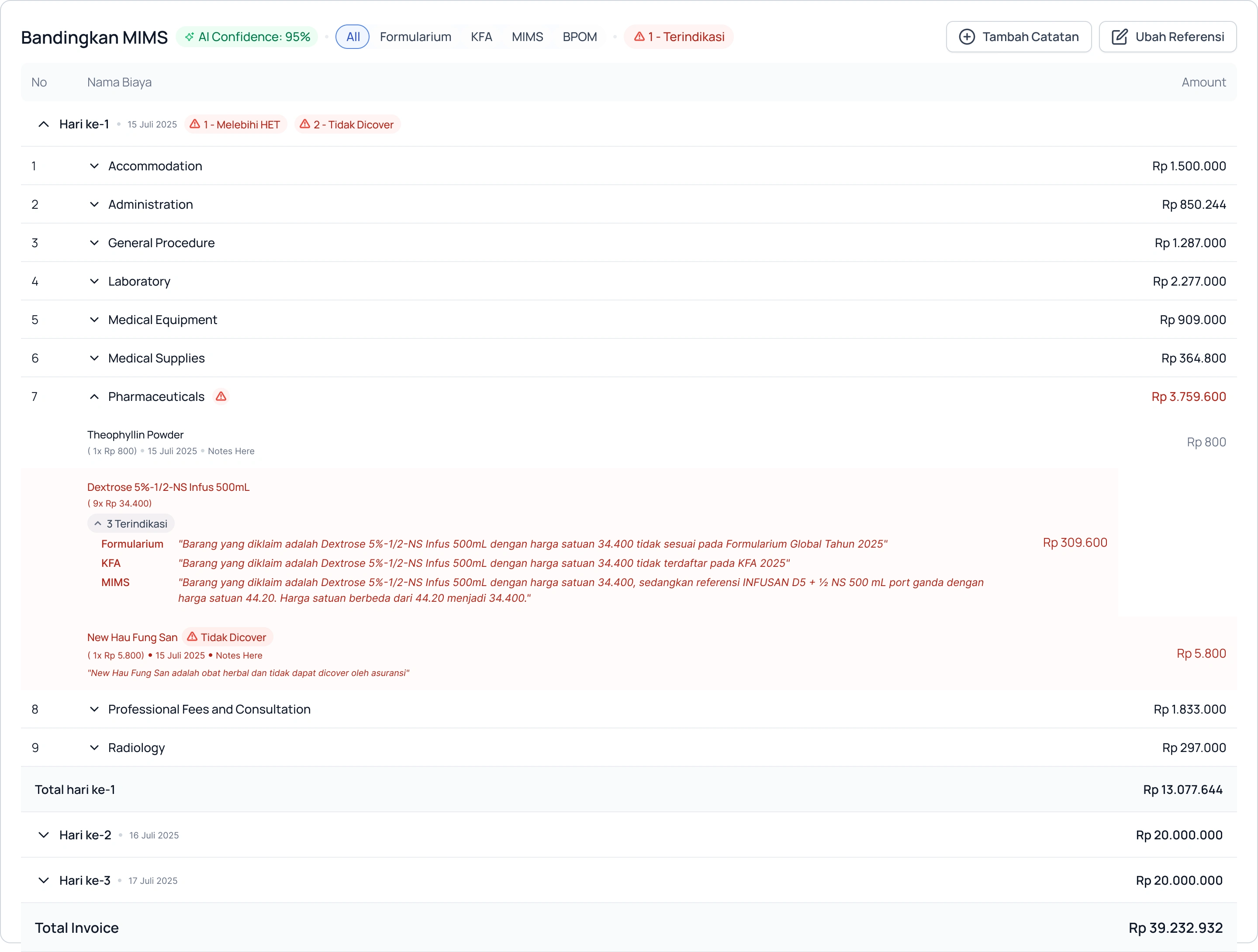
Drug pricing flagged against Formularium, KFA, and MIMS simultaneously. Discrepancy reason pulled from source
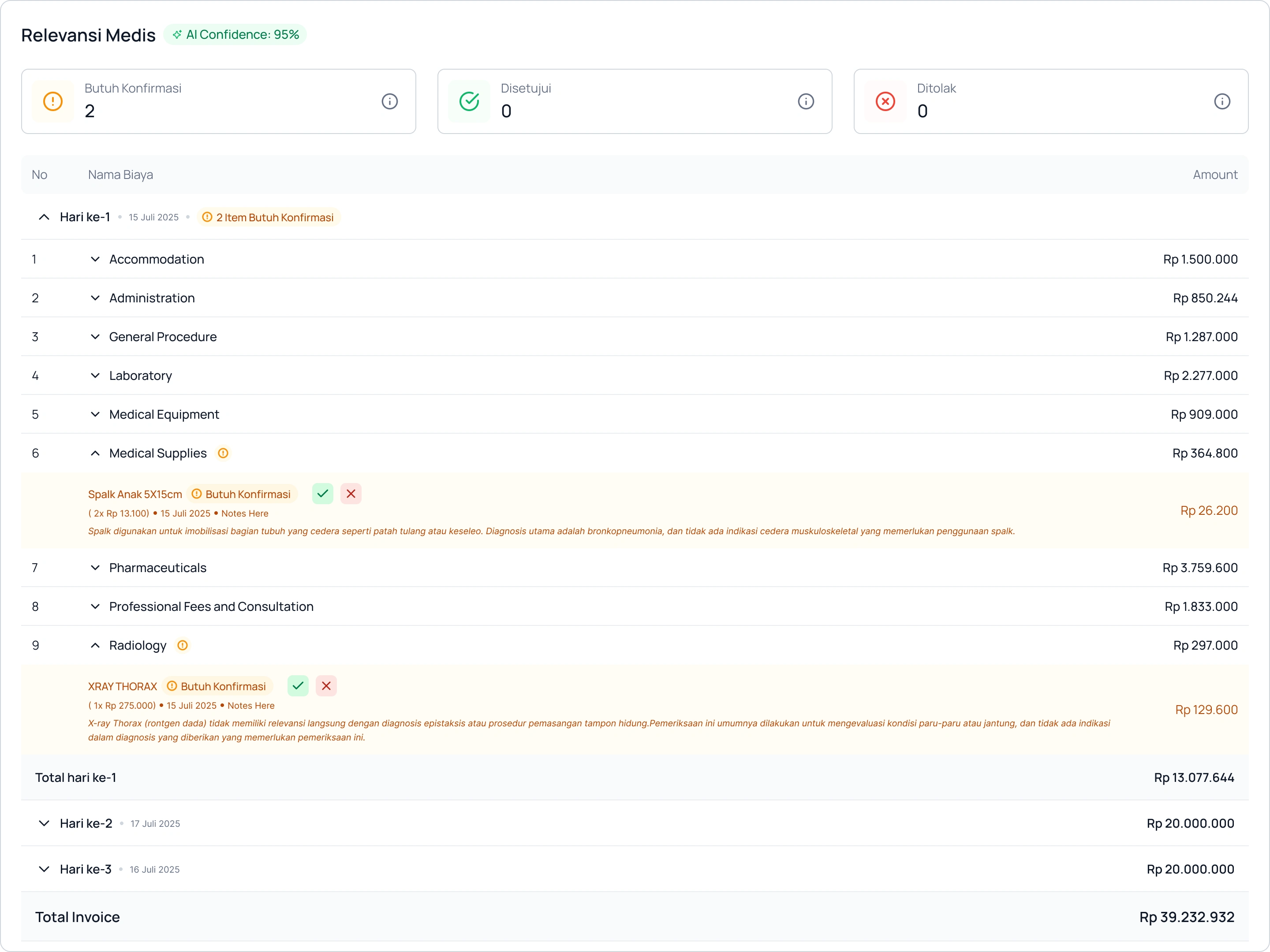
Only items requiring clinical judgment are surfaced. Each flag includes the AI's reasoning in plain language
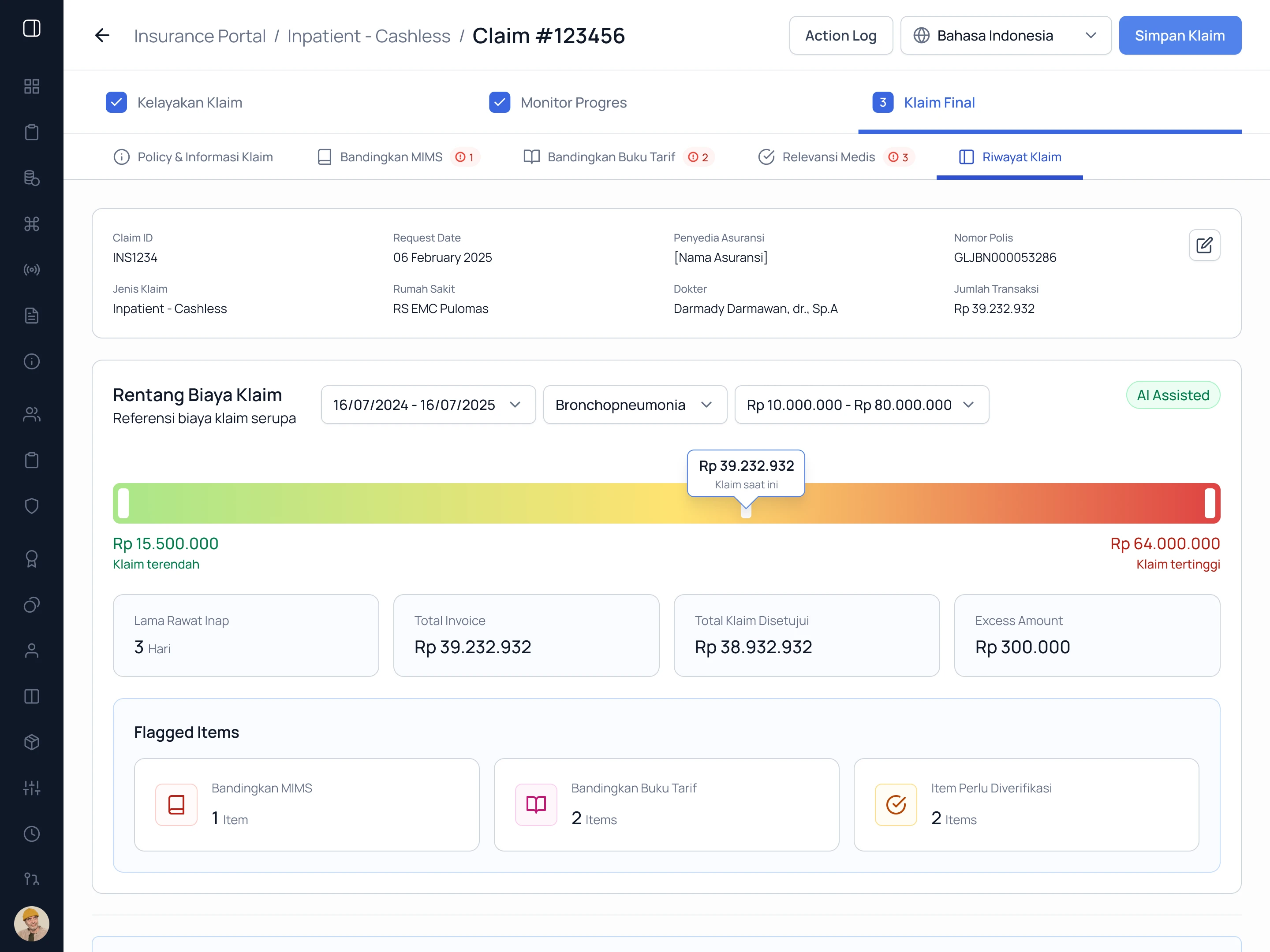
All flags consolidated. A cost range benchmark gives market context before the reviewer approves
Design Decisions
Two-layer review by role.
Analysts and doctors have fundamentally different jobs inside the same claim. Combining them into one view creates noise for both. Separating by role means each reviewer sees only what is relevant to their expertise, reducing cognitive load and review time without reducing coverage.
AI flags before human eyes.
The system surfaces anomalies before a reviewer opens a case, not after. This inverts the default workflow where humans read everything first and flag manually. Starting from a pre-filtered list changes the entire nature of the work from extraction to verification.
Automated comparison against authoritative references.
Pricing checks run against live tariff books and drug pricing databases rather than analyst memory. This removes the expertise dependency that made the old workflow unscalable and produced inconsistent results across reviewers.
Minimal training requirement by design.
Discovery revealed a steep learning curve as a core operational problem. Every interface decision prioritized clarity over feature density so new analysts and doctors could be productive quickly without extended onboarding.
ICD code and clinical logic as structured inputs.
Medical review is grounded in coded clinical data rather than freeform notes. This gives the AI a structured layer to reason against and gives doctors a consistent reference point, removing the interpretive variance that made manual review inconsistent.
Impact
Review time per case — 30 minutes → 6 minutes
Team throughput — Baseline → 5x with same headcount
Case assignment speed (analysts) — Baseline → 2x faster
Medical check completion (doctors) — Baseline → 50% faster
Detection consistency — Varied by reviewer expertise → Consistent across all reviewers
The boundary between system and human is where the efficiency came from.
Claims fraud detection failed not because reviewers lacked expertise but because the process asked them to apply that expertise to everything equally. Every invoice, every line item, every diagnosis note reviewed from scratch. The volume made consistency impossible and the learning curve made scaling expensive.
The redesign separated the work clearly. Anomaly detection, reference matching, and pre-filtering belong to the system. Clinical judgment and final decisions belong to the reviewer. Putting the right work on the right side of that boundary is what reduced review time by 80 percent and lifted throughput fivefold without adding a single person to the team.
The result is a claims review process that scales with claim volume rather than headcount, and produces more consistent outcomes than a workflow built entirely on individual expertise ever could.
Tools
Figma, Jira
Like this project
Posted May 25, 2026
Developed an AI-assisted two-layer fraud detection workflow for hospital claims.