📊[Data Modeling]Prediction Model for BigMart Product Sales
Pei-Han Hsu
Project Overview
About the project
As we manage a company, we not only have to produce products, but also we need to understand the sales status of each type of product in different regions, different channels, and additional merchants, which enhances the importance of analyzing datasets. Therefore, the project will analyze different tiers, types of products, and areas and build models to predict sales.
The Key Question
Depending on several factors (Reviews, Price, Location, etc.) to predict the ranking of the property.
Show total sales in each outlet
Predict the sales of different item types in each outlet next time
Show total sales in each tier
Predict the sales of different item types in each tier(location) next time
Analyzing sales in different types of store
Help the store owner find the problems
Approach
Data scraping
Model creation - multiclass classification
Data visual creation including heat map, pie chart, bar chart, and plot bar.
Data collecting
First, I used the data set sourced by The Devastator.
Feature collected include:
Amount of item type, item identifier, outlet identifier, and outlet location type
Sales of the above types
Items of weight, fat content, and visibility
Eventually, there are 12 columns in our data and 14204 rows of data collected.
Data cleaning
After collecting data, I found out there are 2439 rows of data containing missing value, I need to clean the data by using the following skills:
Column elimitation: 132 inessential columns emitted.
Replace null values: delete rows of nulls.
After conducting data cleaning, our final dataset contains 11765 rows of data, and 12 features left.
Part 1
1. Show total sales in each outlet
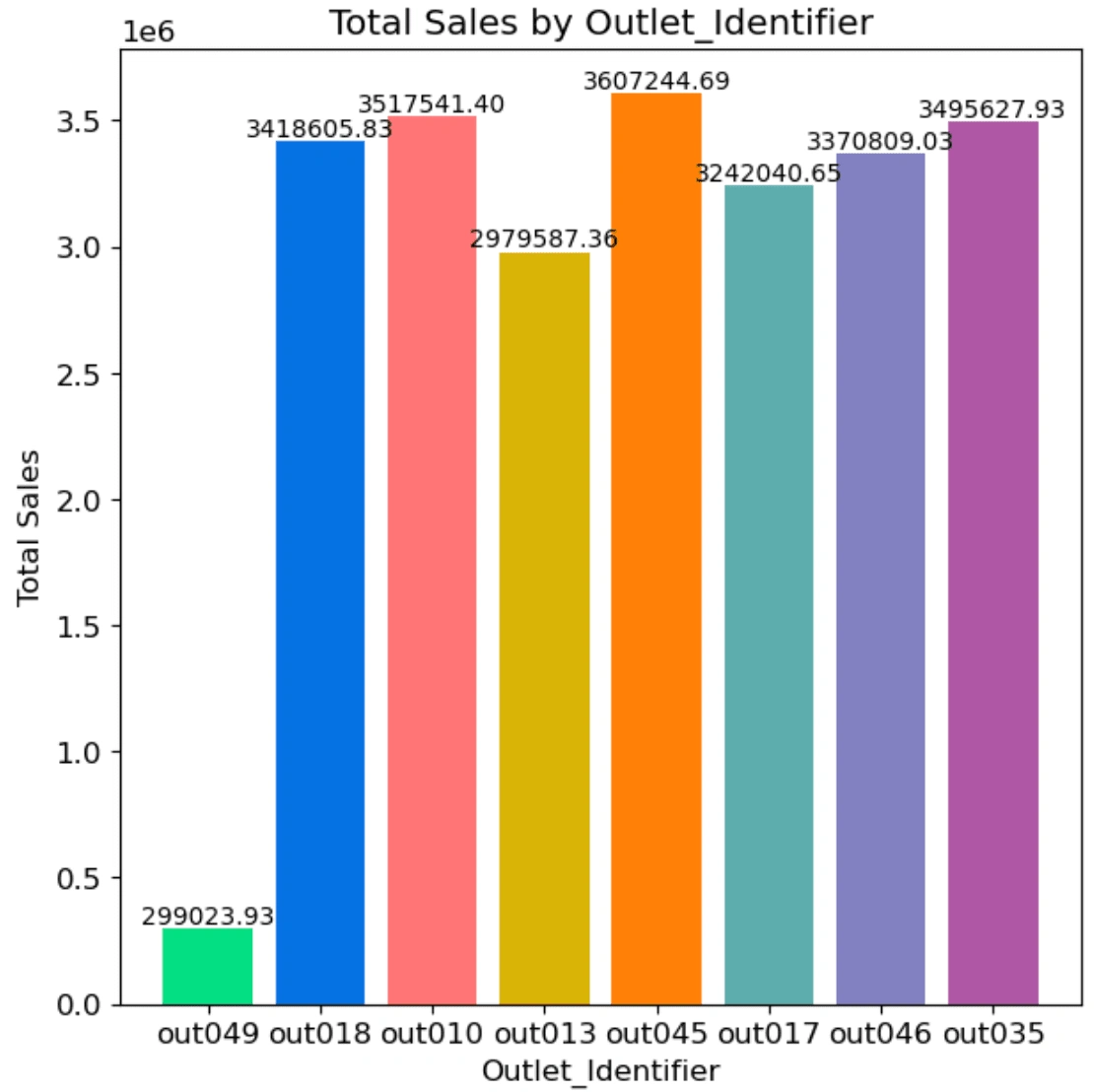
2. Predict the sales of different item types in each outlet next time
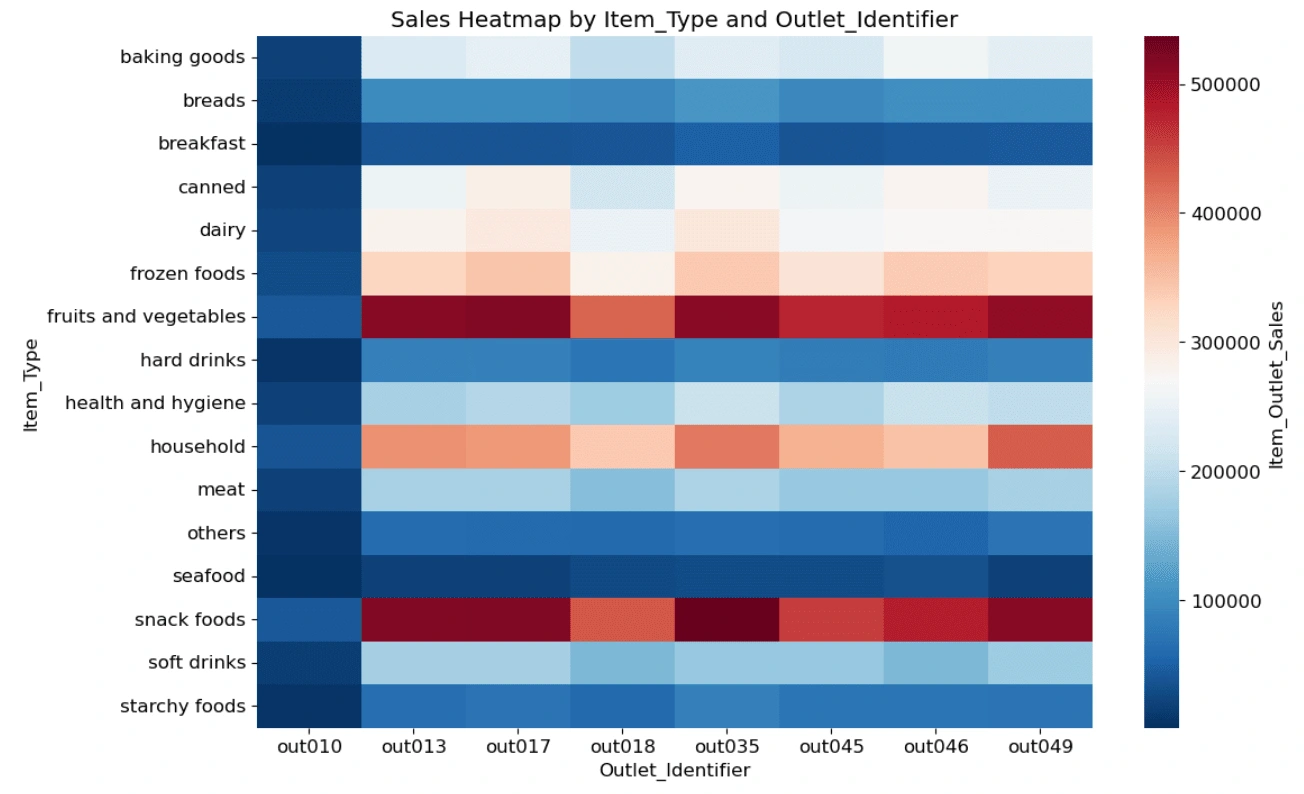
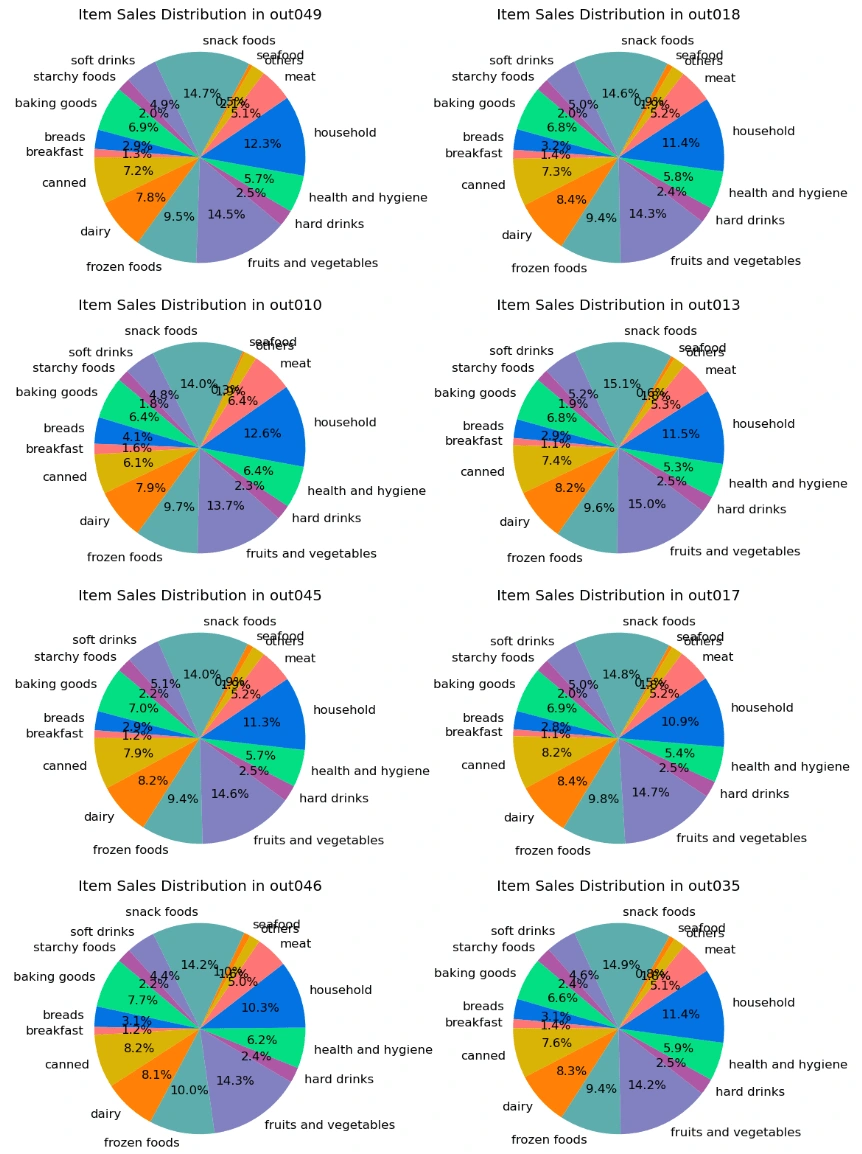
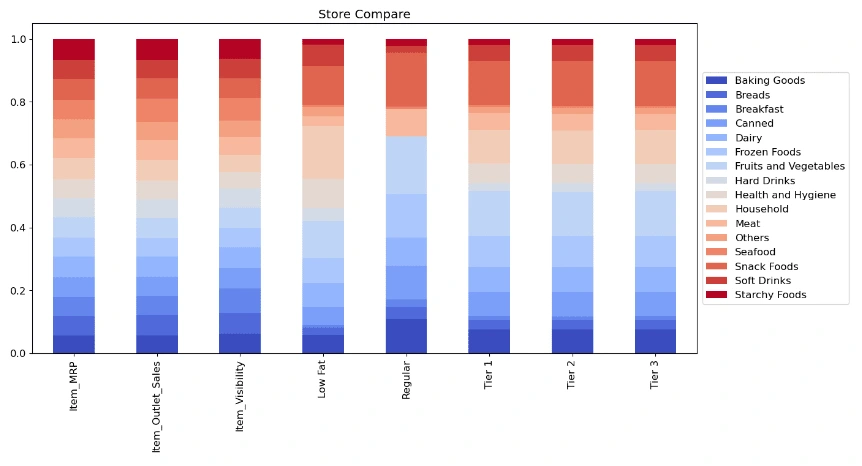
2.1 Using pie chart to appear the proportion of the sales of different item type in each outlet.
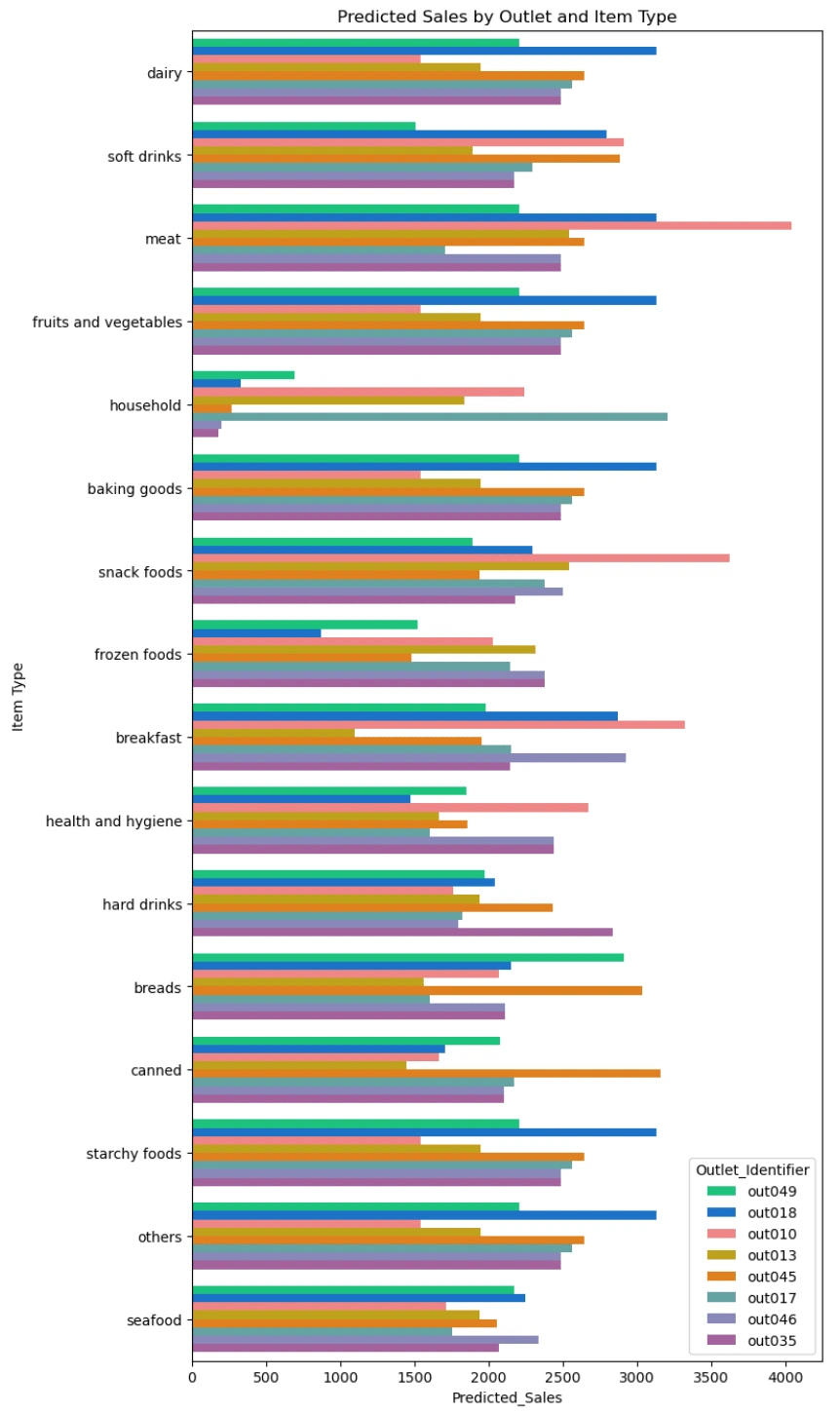
2.3 Predict the sales of different item types in each outlet next time.
2.4 Using bar chart to appear the predicted price of different item types in each outlet next time.
3. Total sales in each tier
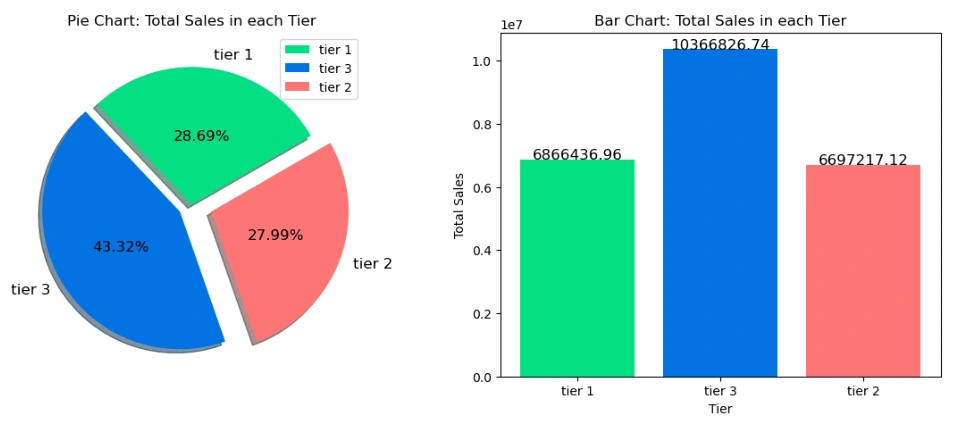
It shows that the total sale of Tier 3 is obviously higher than Tier 1 and Tier 2. If BigMart, the company, would like to invest other businesses, our suggestion is to set up more stores in Tier 3.
4. Predict the sales of different item types in each tier(location) next time
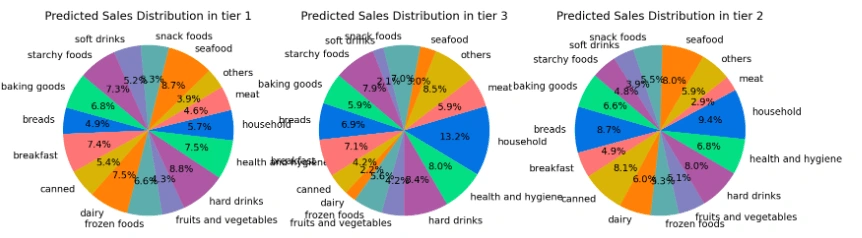
Part 2 Analyzing sales in different type of store
Part 3 Is it true people that are wealthier eat healthier?
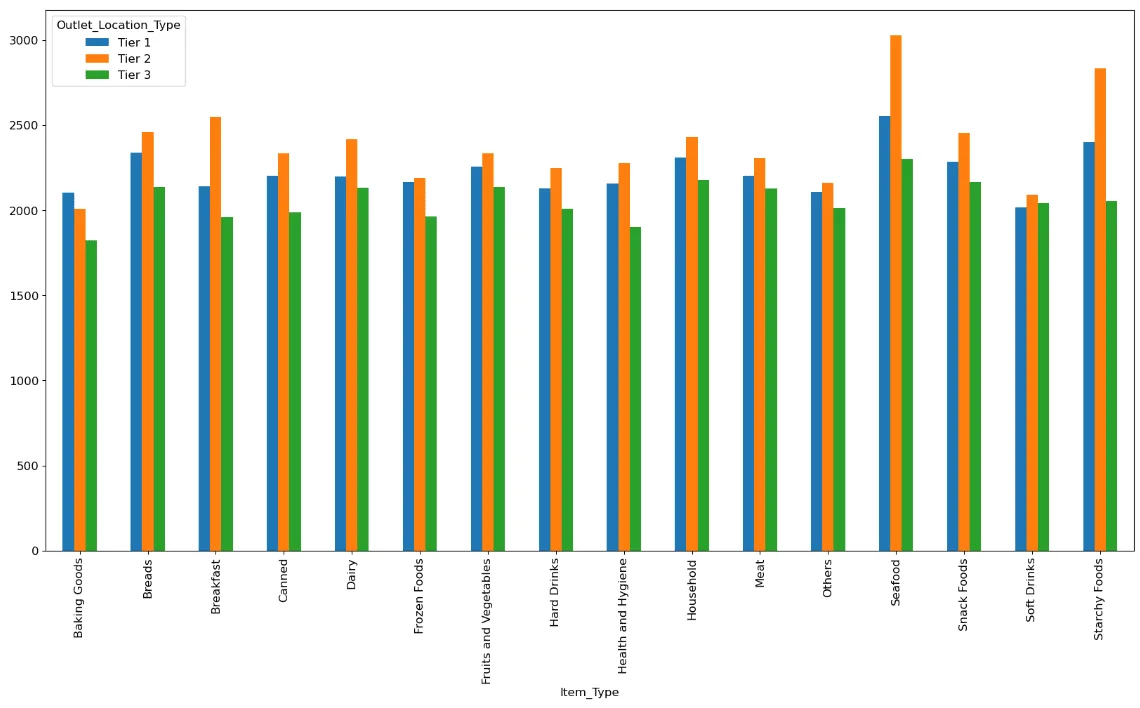
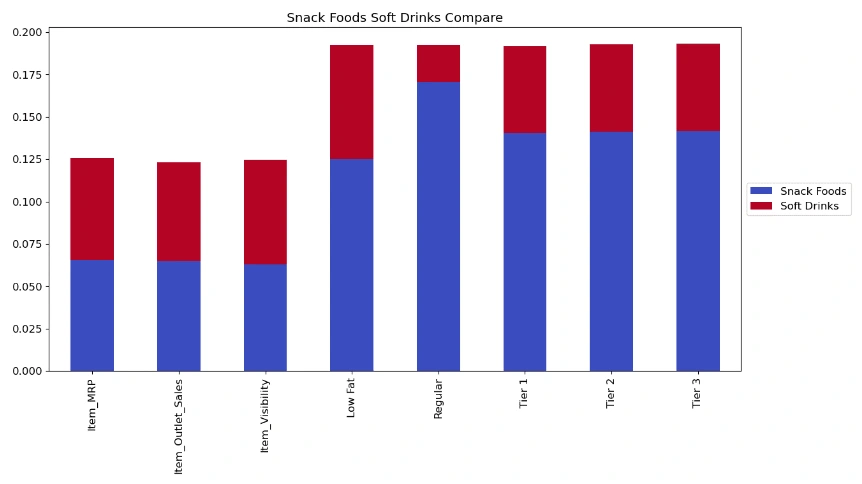
Snack food outperform soft drink in tier 2 In contrast to soft drinks, snack food also sales more product in tier 1 than tier 3. Maybe soft drinks sales more product in tier 1 because the store has more regular fat product in tier 1 and more low fat product in tier 3? based on what we learned before.
Like this project
Posted Jan 5, 2024
The data set comprises store attributes for BigMart, a grocery store chain with several stores in different cities.
Likes
0
Views
4



![[Software Development]Food Delivery App](https://media.contra.com/image/upload/w_700,c_fill/yavh7lyreht6pnc30hns.avif)