KidFriendlySocial - Making social media a safe place for Kids
Hyacinth Ampadu
INTRODUCTION
With the rise of social media use among younger generations(in this case Twitter), it is important to ensure that the content they are exposed to is appropriate and free from harmful language that can negatively impact their development.
For a potential solution to the problem, I developed a simple web application called KidFriendlySocial which addresses this need by utilizing a predictive model and a generative model built using machine learning techniques to identify tweets that contain bad language content.
The app flags the tweet when they are composed, alerting the user(kid) of the potentially harmful content, and then offers recommendations on how to rephrase their tweets that are more kid-friendly or appropriate for children. This also helps children become more aware of what is acceptable and unacceptable online behavior, making them better digital citizens.
In this blog post, I will share my approach to building KidFriendlySocial, highlighting the MLOps best practices I used to ensure its reliability, scalability, and efficiency through the use of version control, CI/CD, data storage & management, automated testing, deployment, monitoring and logging, retraining, cloud integration, containerization & orchestration.
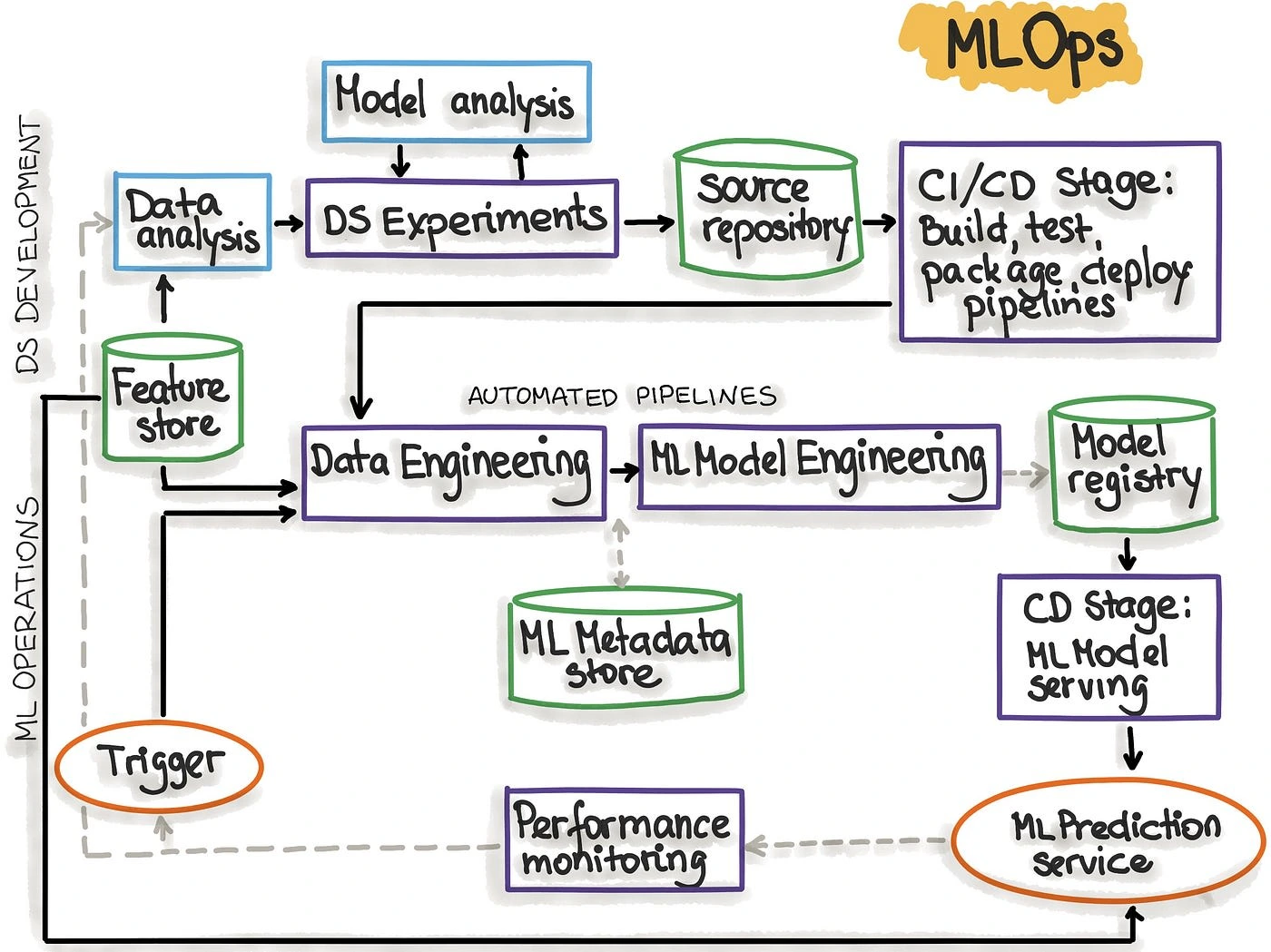
A point of note is this project was not intended for public release but rather as a personal project to showcase my skills in machine learning(MLOPS) and software engineering and also to teach others. It was made available to a select few for testing purposes only and has not been integrated into any systems or applications
TOOLS & TECHNOLOGIES

Below are the various tools and tech used to develop the solution:
Backend development: Python for building the whole backend application
Microservices: Used to separate the functionality of the application into smaller, more modular components, improving scalability and maintainability.
Frontend development: HTML and CSS for the frontend
NLP models: Distil-Roberta for bad language detection and GPT-3 for generating recommendations
Deep learning: Pytorch framework for building the NLP deep learning model
Web framework and APIs: Flask for building the web application and APIs
Data APIs: Twitter API to obtain real-time data
Containerization: Docker for packaging the application and dependencies
Container orchestration: Kubernetes for deploying and managing containers
Cloud hosting: Digital Ocean for hosting the application on the cloud
CI/CD: Github actions for continuous integration and continuous delivery
Database: MYSQL as the database
Version Control: Git for code version control and DVC for data and model version control
Testing: Pytest for unit and integration testing
Monitoring: Prometheus for monitoring metrics and Grafana for visualizing them
SOLUTION OVERVIEW

The model was built using the state-of-the-art natural language processing algorithm, DistilRoberta, to detect and classify bad language content. The app also leverages OpenAI’s GPT-3 to generate recommendations for users to improve their tweets when bad language is detected.
The application was built using Flask, a lightweight Python web framework, and containerized using Docker to ensure that it can be deployed easily on any infrastructure. The app is hosted on DigitalOcean Kubernetes, a highly scalable and efficient cloud platform that can handle a large volume of traffic. The application is also monitored using Prometheus and Grafana to ensure optimal performance, and all data is stored and managed in an MYSQL database also hosted on the digital ocean cloud platform.
KidFriendlySocial incorporates several MLOps best practices, including version control of models and data, continuous integration and continuous deployment (CI/CD), and automated testing
DATA
Dataset
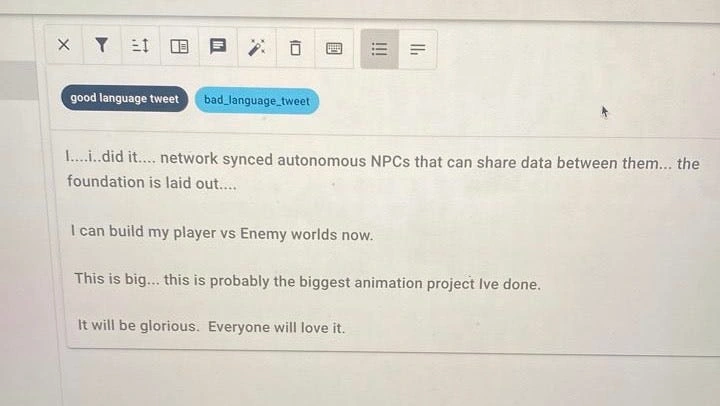
The data for this project was obtained from two distinct sources, firstly from available datasets on the internet, and from data extracted from the Twitter API. The data available on the internet was cleaned and put into a format that is usable, and it was already labeled, whiles I used Doccana, an open-source data labeling platform to label all the data extracted from the Twitter API. The data from Twitter API is very relevant in order to obtaining the latest data from Twitter to use to train the model.
An example of the way I used Doccana to label the dataset, by selecting good language tweet or bad_language_tweet and it gets labeled, is shown below:
Database
Relational database, MYSQL, is the database of choice to store all user details related to authentications and user feedback in order to score the model in production and also to add actual tweets from users to use as training data to improve the model in the next version(retraining). The MYSQL database was hosted on the digital ocean platform to ensure high availability.

ANALYTICS
Firstly, wanted to see the most common unique words(unigram) that appeared in tweets that contain bad language:
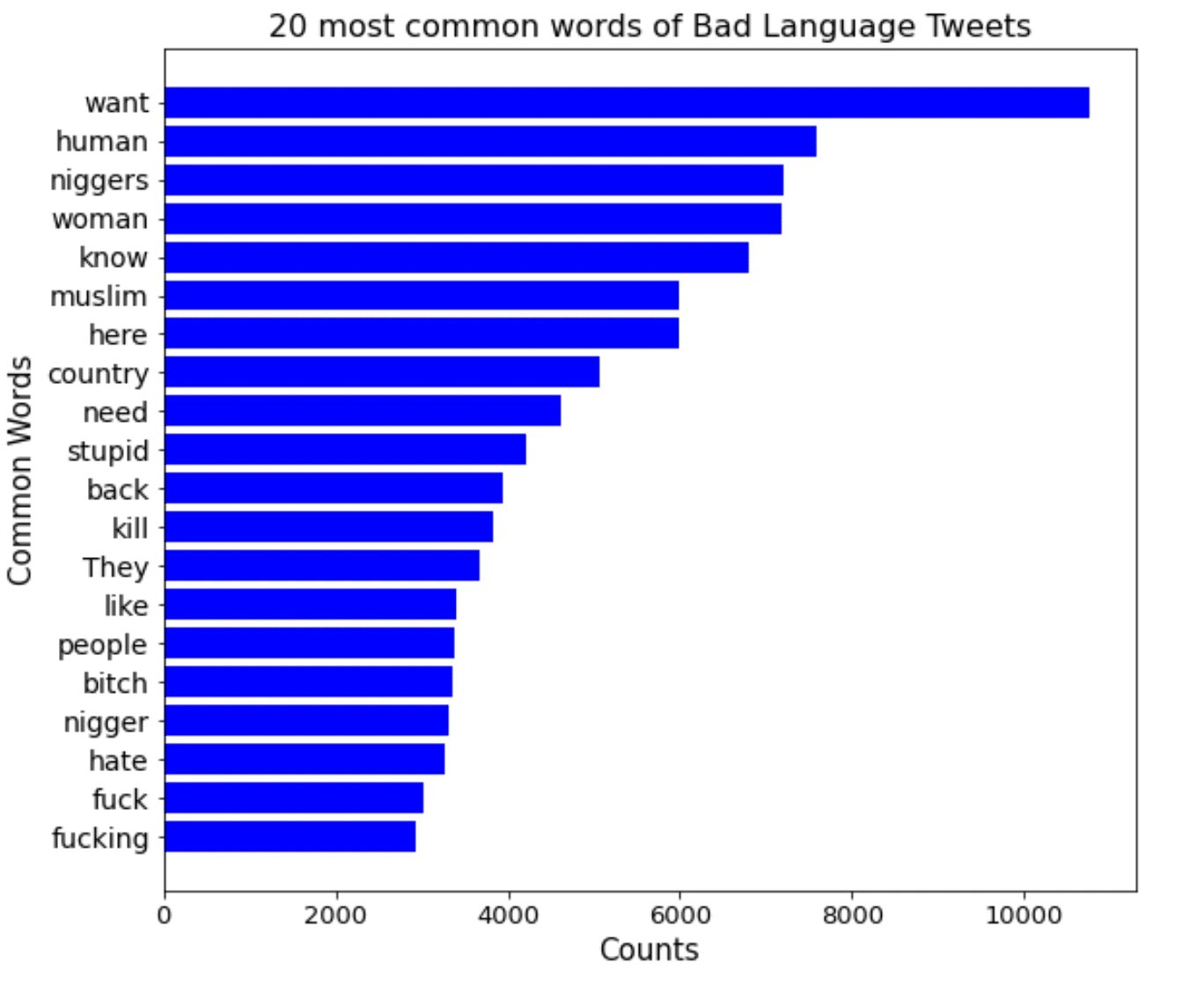
As can be seen, there are some words that are more general such as want, human, etc, these are included here because they were used in contexts of tweets that are not kid appropriate but the words themselves are appropriate but the words that are strictly for bad language can be seen in there such as fuck, stupid, niggers, etc.
Also, it was ideal to visualize a word cloud of tweets that contain good language and ones that contain bad language, to see how different they are:

As can be seen above, there is a clear difference between good and bad language texts, which is useful for us to differentiate and build a model to try and classify tweets according to this.
MODEL BUILDING & EVALUATION
Predictive Model
The Distil Roberta model which has been pretrained on a huge corpus of tweets(model name: vinai/bertweet-base) was used as the base model of choice for training, because the model already understands how tweets are constructed so it can easily generalize to our tweets, and also since its a distil roberta model, it's a smaller model that still has excellent accuracy, and most importantly, it's smaller in size, so it trains faster and the inference speed(latency speed) is lower. 4 metrics were used ( accuracy, recall, precision, and f1), but the most important metric here is recall, as the key is to identify as many potentially bad language tweets as possible to protect children. Here, the focus is on minimizing false negatives(the situation where the tweet contains bad language but the model predicts it to contain good language). It's okay to allow flag some good language as negative, but it's not good to allow bad language to get out there, so reducing this situation(higher recall) is the most important here. However, precision is also important to ensure that the recommendations provided by the application are accurate and trustworthy. Below are the metrics obtained:
accuracy: 0.949936717761215
precision: 0.9477199286616215
recall: 0.9464880338247377
f1: 0.9470952154920613
The performance seems good, with the recall being almost 95%, which suggests the model does well in catching bad language tweets. To visualize all these metrics, the confusion matrix was used, the result is below here:

As can be seen, a lot of bad language tweets were correctly predicted with only 376 out of 5483(false negatives) incorrectly predicted, also for good language tweets, only 336 were wrongly predicted as being bad language tweets. This shows the model would be robust in predicting if a tweet contains bad language or good language. The key here is to try to reduce the 376 false negatives to capture more bad language tweets, as that's the one we are most interested in predicting.
Generative Model
GPT3 was used for generating the recommendations when bad language is detected, the temperature(how random the generations should be) was set to 0.8 to allow for variations in modifications generated but not too much to distort the context, the max length to 256, to allow users to express themselves more, text davicni 003 which was the most advanced model at the time of building was used, and an excellent prompt written to generate the recommendations.

The GPT3 was finetuned using 150 tweets of bad language-good language pairs to enable the model to understand the context a little better to generate relevant recommendations.
CI/CD
GitHub actions was used as the CI/CD tool, to automate the process of building, testing, and deploying the web app.

It makes sure all the parts of the project work, are robust, and would not break in production. Any change made to the code or any aspect of the project, would need to build again, pass all tests and deploy the modified version of the app, this ensures the reliability and scalability of the application. For the pipeline made in this case, firstly, all dependencies are installed, so if any new version is released, it's updated here, then flake8 is run which makes sure the code is consistent, readable, and maintainable. The AWS credentials are configured as the predictive model is stored in an S3 bucket via DVC, and the model is then pulled from the s3 bucket, then all the tests are performed(which is discussed in the next sections). This is the current implementation of the Ci/CD pipeline.
TESTING
Pytest was used for performing all the tests in this project for both unit tests and integration tests. The testing is essential to catch any bugs or errors before pushing the app to production. It ensures a correct and robust app that works exactly how we want to and the users have a seamless experience.

The tests written were in three parts, the authentication aspect, the data aspect, and the model aspect. The authentication tests ensure all aspects of user authentication, such as signing up and logging in, work correctly without any issues. The data aspects test for the correctness and validity of the data to ensure the right format of data is being used and accessed. The model testing tests the model's performance to ensure it gives out correct predictions, and quality predictions, and the predictive model’s integration with the generative model is correct and it's working well. Various tests in these categories were written and added to the CI/CD pipeline, which ensures all the tests pass before any updates or changes are pushed to production.
MODEL IN PRODUCTION
Deployment
Flask was used to serve the model as a web service, Docker was used to package the Flask application along with its dependencies, and Kubernetes was used to manage the deployment and scaling of the Docker containers, and hosted on digital ocean.
The authentications(signup, login) were written using Flask, and jwt authentication was used to authenticate users to use the app, and all the passwords were hashed using bcrypt to protect user privacy. The app was made available to only 11 diverse users for a week, to interact with the app, in order to get feedback on how to improve the app, and also to use their feedback to score the performance of the model and improve the model.
WebApp Demo
Below is a demo of how the app works. PS: I had to take the app down since it costs money to host the app on digital ocean(the docker containers, the Kubernetes clusters, and the MySQL database).Demo of the model predicting good language(demo takes about 10 secs):
Demo of the model predicting bad language(also takes about 10 secs):
As can be seen in the demos, the good language prediction is straightforward, the focus is on detecting the bad language, the model correctly detects that the tweet contains bad language that is not useful for kids, and generates appropriate recommendations for them to use to improve their tweets.
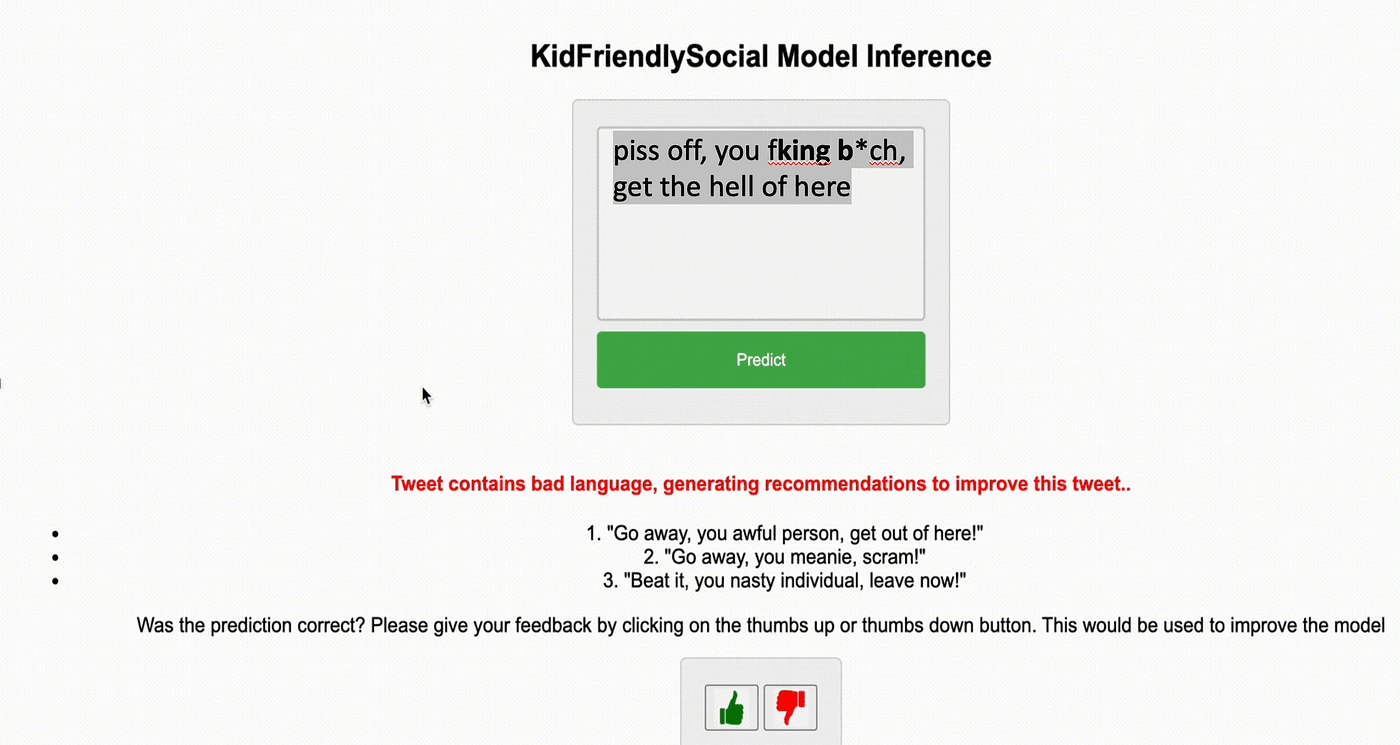
The image above shows the recommendations generated when bad language is detected, so in the demo, the actual tweet was :
“piss off, you fking b*ch, get the hell of here”,
and the generated recommendations were :
“Go away, you awful person, get out of here”
“Go away, you meanie, scram!”
“Beat it, you nasty individual, leave now!”
As can be seen, the recommendations contain the same meaning and context as the original tweet, but it is a more kid-friendly version and contains no bad language, which is what we seek to accomplish.
Monitoring
The performance of the model and the system was monitored using Prometheus and Grafana and the digital ocean internal monitoring tool. System metrics such as server response time, CPU, and memory metricswere monitored using the digital ocean internal monitoring tool, and the model metrics were monitored using Prometheus and Grafana.
The performance of the model was based on user feedback, as they are the ones the app is for, so their feedback is the most important to know how well the model is doing. As already explained, the app was made available to 11 unique individuals to use who performed 43 predictions, and these were the metrics monitored:
The total number of feedbacks received: This can give an indication of the overall engagement with the app.
The number of feedbacks categorized as bad language: This helps to track the frequency of bad language.
The number of correct bad language predictions: This shows how effective the model is at identifying bad language.
Percentage of correct bad language predictions: This gives a more accurate representation of the model’s effectiveness, taking into account the total number of bad language predictions.
Number of feedbacks categorized as good/normal language: This helps to understand the overall capacity of the model to determine the good language
The number of correct good/normal language predictions: This can show how effective the model is at identifying appropriate language.
Percentage of correct good/normal language predictions: This gives a more accurate representation of the model’s effectiveness, taking into account the total number of good/normal language predictions.
The image below shows the monitoring of the model in production:
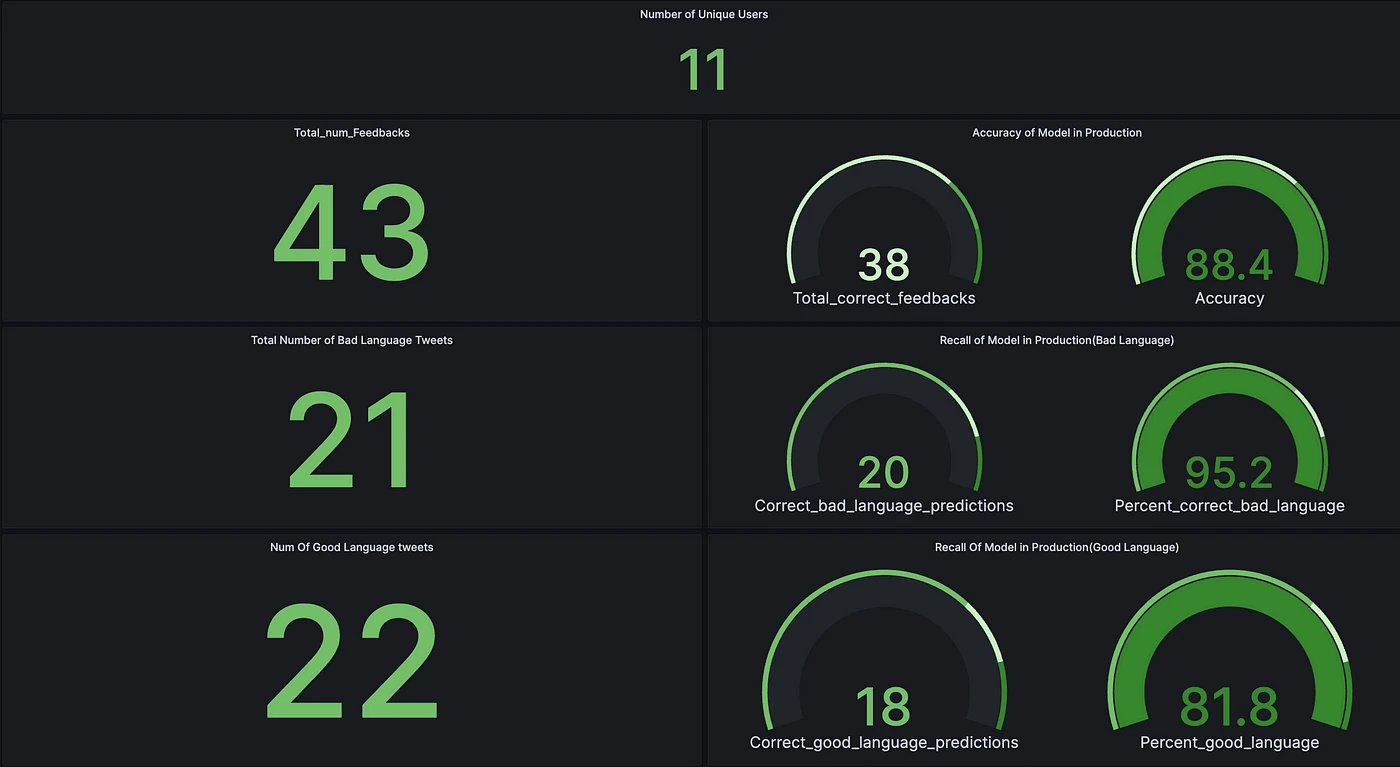
The model so far is very good at predicting bad language, with only one instance where a tweet containing good language was predicted to contain bad language. This is where we are most interested in, catching all bad languages so bad tweets aren't sent out there for kids to consume, as can be seen with the 95.2% performance of the model. Good language tweets scored a little worse, even though our focus isn't solely on that, an improvement in that aspect is required. Because recall is the most important here, that is what was monitored.
This is the way model monitoring is done so far to keep track of the metrics of the model as users are interacting with the app, to get a sense of how the model is doing, and if the performance starts declining, appropriate measures are taken. The metrics update in real-time as users keep interacting with the app which allows you to monitor and make decisions about whether the model is working well in production.
Model Retraining

The pipeline was set such that after a prediction and recommendations are given to the user, and the user gives feedback, the data is sent to the MYSQL database, and based on the feedback, if the users think the prediction is correct, the feedback data is sent directly and added to the training data. If the users think the prediction is wrong, it's sent to the wrong prediction section to be analyzed and the label is corrected and added to the training data to kick off retraining.
POTENTIAL FUTURE WORK
This was just a personal project, but there are several avenues for future development to make it available for public release to derive value, including:
Incorporating KidFriendlySocial as a browser extension
Integrating it directly into Twitter
Incorporating multilingual support
CONCLUSION
KidFriendlySocial is a web application that aims to make social media safer and more child-friendly. By using machine learning models(NLP), web technologies, container technologies, and cloud hosting, I was able to create a minimal viable product(MVP) application that can detect and flag bad languages and provide recommendations to improve the language used in social media posts, which can potentially help parents and guardians feel more at ease with their children’s social media usage and contribute to a safer and more positive online community.
This blog focuses on explaining the various processes required to develop your own models(in this case large language models) and make them available for users as an app, utilizing MLOPS best practices. It explains the relevance of each component and how they integrate with each other to get a working app that is reliable, maintainable, and scalable. You can use and build upon these concepts in your projects and applications, as it's important for us engineers to follow these practices to develop robust applications.
All the code used in this project can be found here → https://github.com/JoAmps/KidFriendlySocial
Like this project
Posted Mar 24, 2024
Developed a web app to promote safe social media use among kids by flagging harmful content and offering kid-friendly tweet suggestions.
Likes
1
Views
30