Transforming Leads into Customers with Predictive Modeling
Hyacinth Ampadu
INTRODUCTION
Lead conversion is a crucial aspect of business, especially for companies that deal in apps and websites. Identifying and predicting which leads are likely to become paying customers is important since those individuals contribute a lot to the company’s profit margin. A lead conversion rate of around 11% is deemed to be a good percentage, so every company wants to achieve that and even more, and the best way to do that is to predict these so that the required and appropriate arrangements are made to enable them to complete the process of converting, to keep making profits for the company and business.
For a lead to convert, there are various processes, one of the ideal processes is, the lead hears about the app, leads checks out the app, leads reads more about the app elsewhere, leads registers with the app, and hence lead converts. During this process, the lead can stop at any time, so it’s important to be able to predict the ones that are likely to convert to enable them to complete the converting process successfully. The ability to identify and target leads that are likely to convert can be the difference between a profitable venture and a failed one.

In this project, the use case was a mobile company trying to improve its lead conversion by utilizing ML techniques, and in this blog, I will discuss my approach to helping this company improve its lead conversion by diving into the technical details of how I built and deployed the system to a simple streamlit web app.
TOOLS & TECHNOLOGIES
Below are the tools and technologies employed in this project:
Backend development: Python
ML models: Random forest, Logistic regression, Decision trees, Xgboost, LightGBM
Frontend: Streamlit
Containerization: Docker
Experiment tracking: Weights and biases(WandB)
API: Fast API
Version Control: Git
Testing: pytest
CI/CD: Github actions
ANALYTICS
The first and most important thing was to look at the characteristics of leads that converted
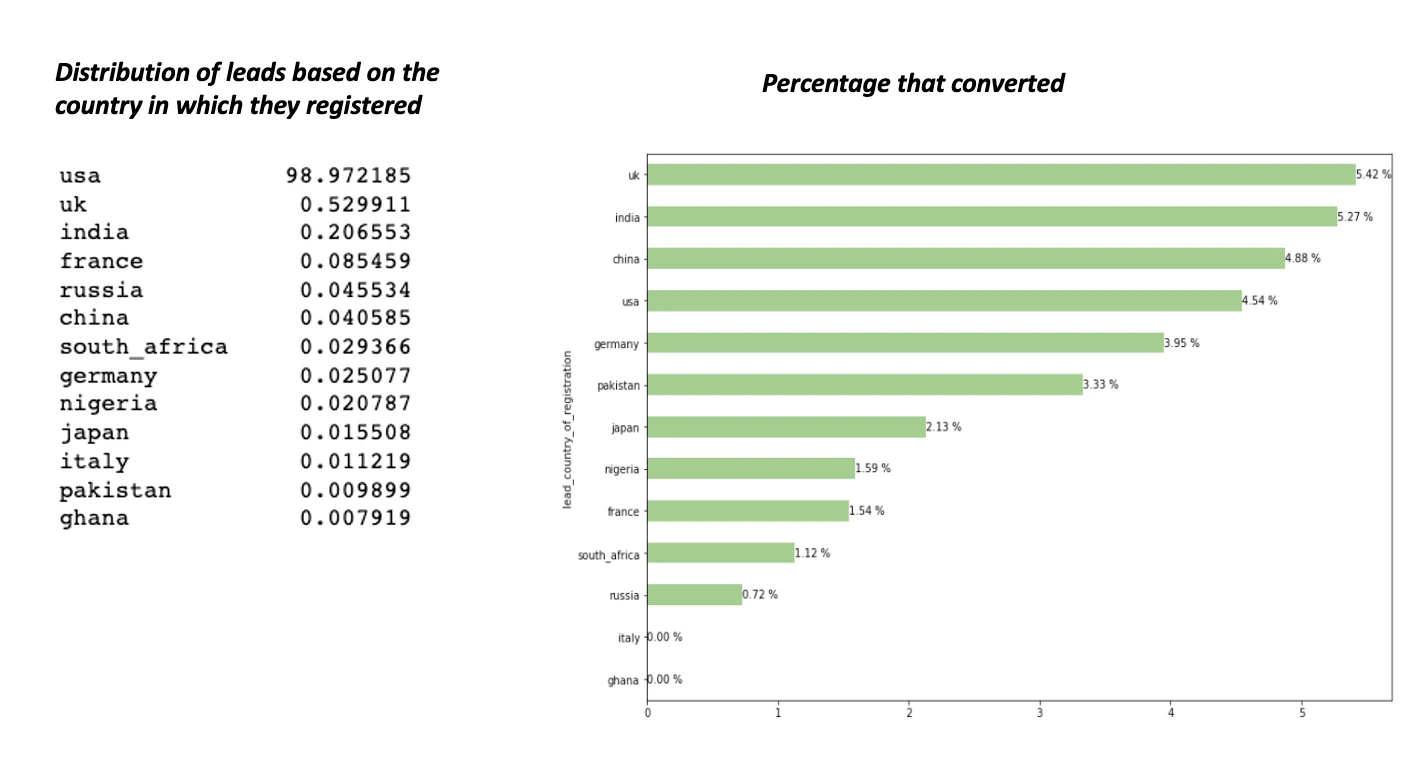
From the image above, most leads reside in the United States, with over 98% of leads, but only less than 5% of them converted, compared to the Uk which accounted for less than 1% of all leads, had the most leads converting, with around 5.27% of leads converting, which suggests leads registering in the UK are to be targeted more since they tend to convert the most.
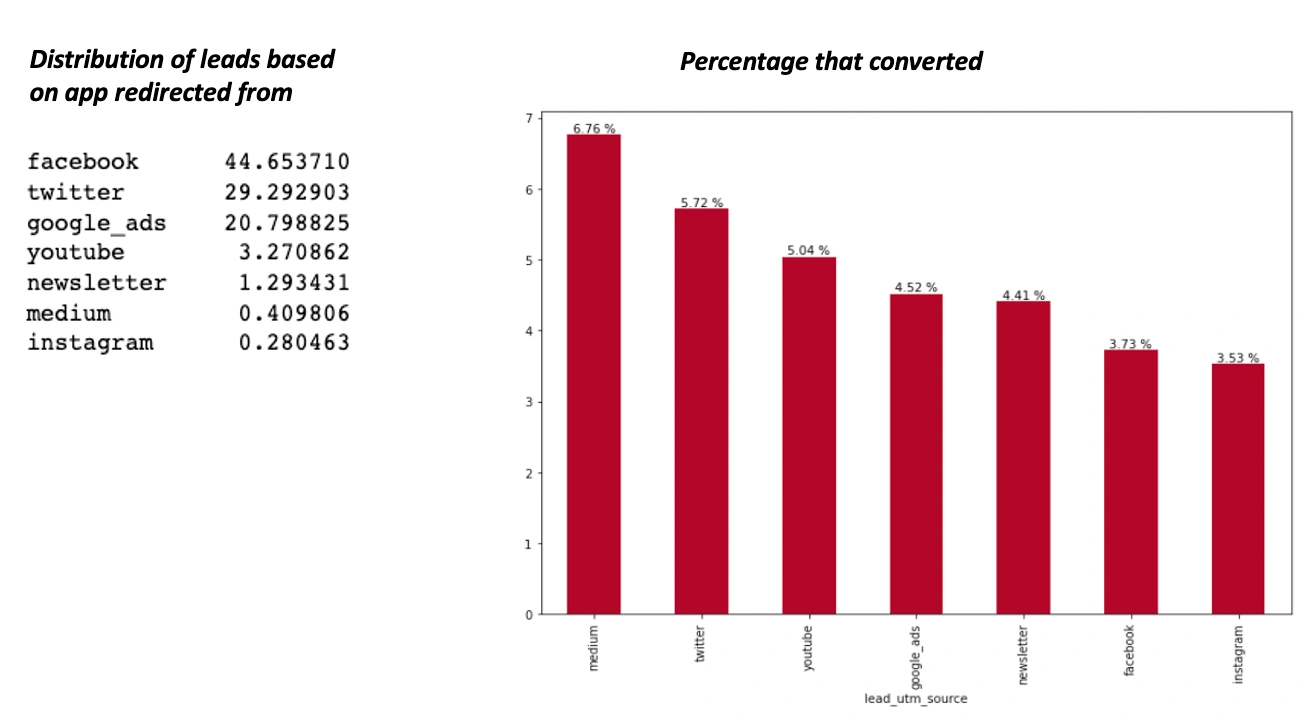
From the image above, Facebook is the source that most leads redirect from, with almost half of all leads redirecting from there, but only 3.73% of leadsconvert from there. Medium redirection accounts for the most lead conversion with 6.76%, even though less than 1% of all leads redirect from there, so leads that redirect from medium should be given the most attention.
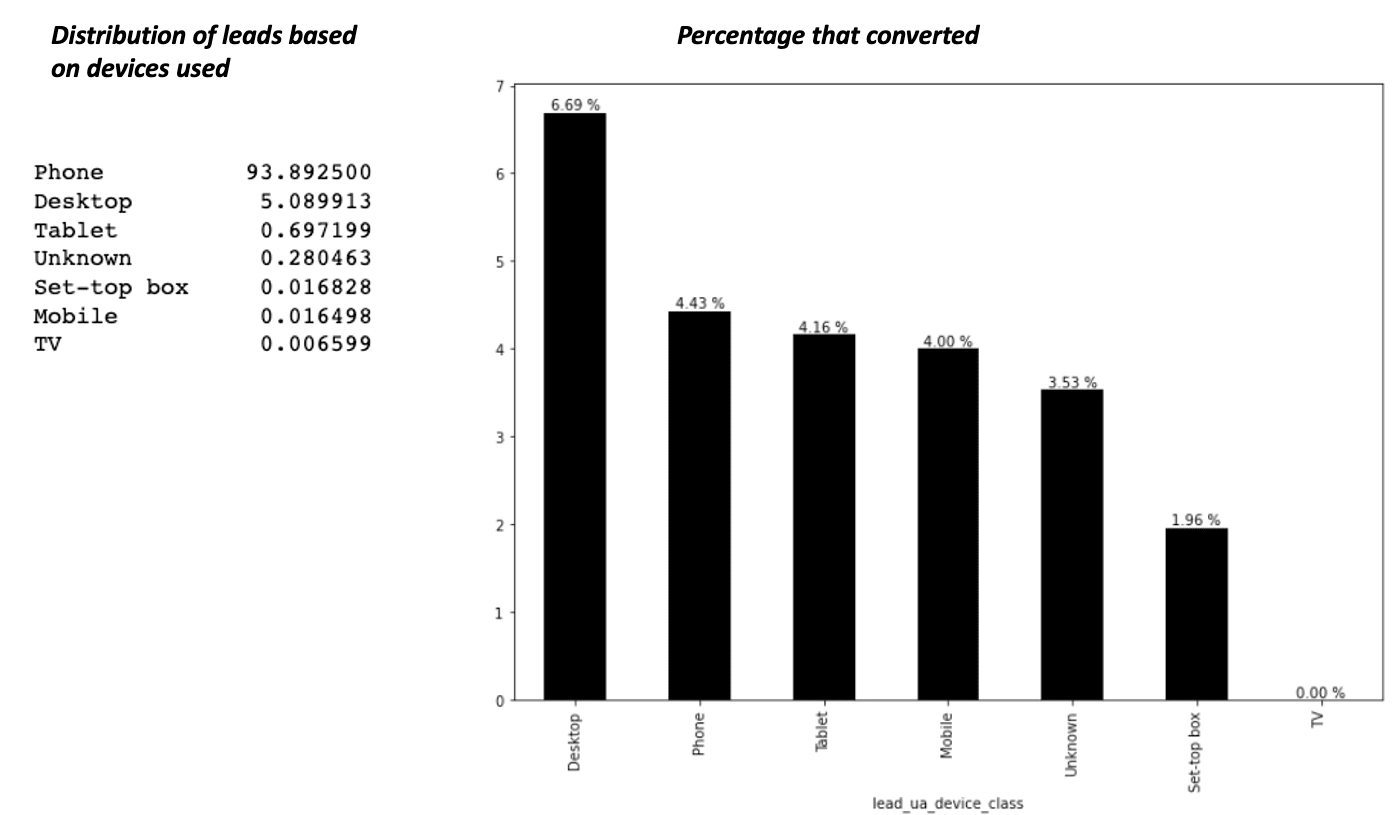
From the image above, the phone is the device most leads use to register for the app, with almost 94% of all leads registering with it, but only 4.43% of such leads are converted. The desktop has the highest conversion rate, with around 6.69% of all leads converting when they used the desktop to sign up, but only 5% of all leads signed up using the desktop, this could be due to the fact that leads who use the desktop have a bigger screen to look at the app and see all its features, and its easier to navigate, for example clicking a link on the app could just redirect to a new tab, keeping the other tab open, whereas, in the phone, the old tab probably would be closed. So the best option here is to target leads using desktops as they are more likely to convert.
MODEL BUILDING & EVALUATION

In building the models, 5 algorithms were used: Random forest, Logistic regression, Decision trees, Xgboost, and LightGBM. These were chosen for the following reasons:
Random Forest: Random Forest was selected for binary classification of unbalanced data because it's an ensemble model that can handle high-dimensional data, it can capture complex interactions, and successfully address the class imbalance problem in this project
Logistic Regression: Because of its computing efficiency, interpretability, and ability to handle linear relationships in the data, logistic regression is well suited for this project which is a binary classification with unbalanced data.
Decision Trees: Decision Trees are selected for binary classification of unbalanced data as they can handle both numerical and categorical features, capture non-linear relationships, and effectively address the class imbalance.
XGBoost: XGBoost was also selected due to its optimized gradient boosting approach, strong regularization techniques, and ability to handle class imbalance effectively while preventing overfitting.
LightGBM: LightGBM is chosen here also because of its speed, efficiency, and ability to handle large datasets. Its leaf-wise tree growth strategy and histogram-based feature binning make it suitable for addressing the class imbalance in the data.
Final Features
These are the final features used to build the predictive model:
Time of day user interacts with the app: This feature captures the specific time of day when users engage with the app, which can provide insights into their behavior patterns and preferences.
App lead is redirecting from: This feature tracks the source or channel through which leads are coming to the app. It helps understand the effectiveness of different social marketing channels.
Country of origin: This feature captures the geographical location of leads, which can be valuable for tailoring marketing strategies, understanding regional preferences, and localizing campaigns.
Weekday or weekend: This feature categorizes leads based on whether their interaction occurs on a weekday or weekend, allowing you to analyze if conversion rates differ based on the day of the week.
The time between the lead first opening the app and returning: This feature measures the time interval between a lead’s first interaction with the app and their subsequent visits. It provides insights into user engagement and helps identify active or potential leads.
Device lead is using: This feature captures the type of device (e.g., mobile, tablet, desktop) that leads are using to access the app. It can help optimize the user experience and tailor marketing campaigns for different device types.
Experiment Tracking

Weights and biases was used to track the experiments. Experiment tracking is relevant to keep track of all the experiments I performed, recording the various parameters and configurations I tried, and comparing the performance of different models. I run a lot of experiments, so having this experiment tracker is vital in order to keep track of what I did, and know what worked and what didn't. This ultimately helps to increase efficiency, productivity, and accuracy in developing these machine learning models.
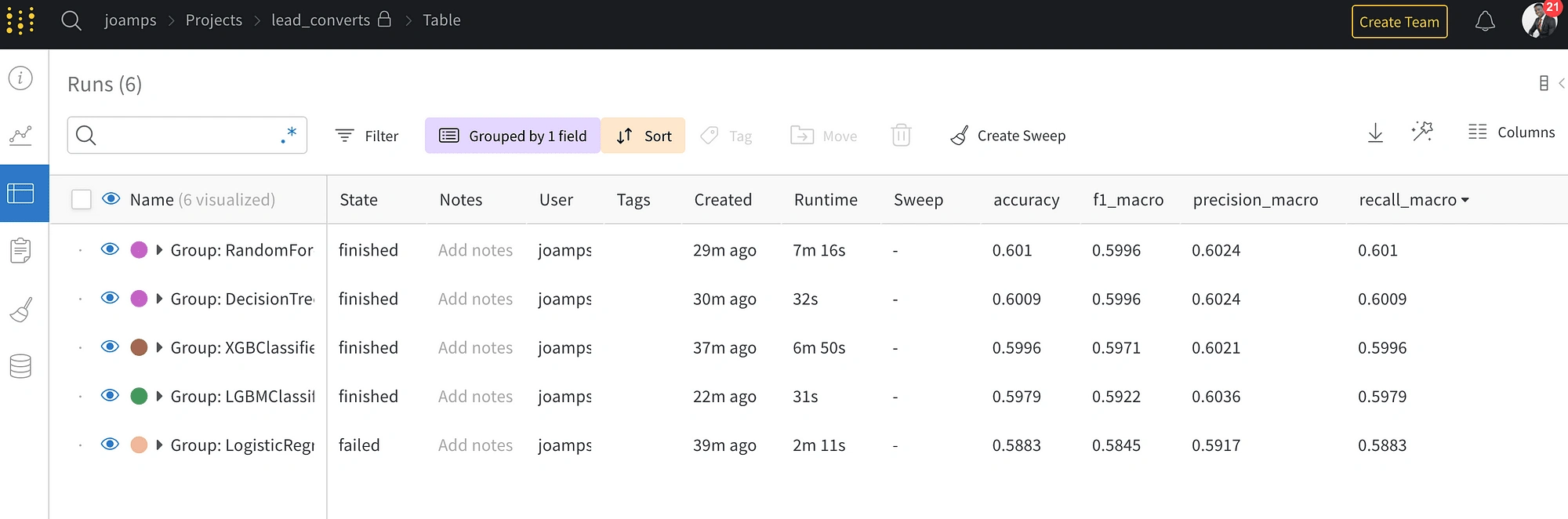
The figure above shows the experiments of the models built being tracked by wandb, and the best-performing model was the random forest algorithm, so that’s the model chosen for further development.
Model Evaluation
The performance of the model was evaluated on 5 metrics, accuracy(which isn’t a good metric for unbalanced datasets), recall, precision, f1score, and roc_auc. The model does not do quite that well in general, achieving scores of around 60% for the metrics, as it’s hard to predict leads that would convert as leads have very unique characteristics, but it makes an effort to predict them. The recall is the most important metric here, as we are interested in predicting all leads that convert, even if it means having a few leads that did not convert predicted as converted, so here having a few more false positives is acceptable. The Roc curve with the AUC score is shown below.
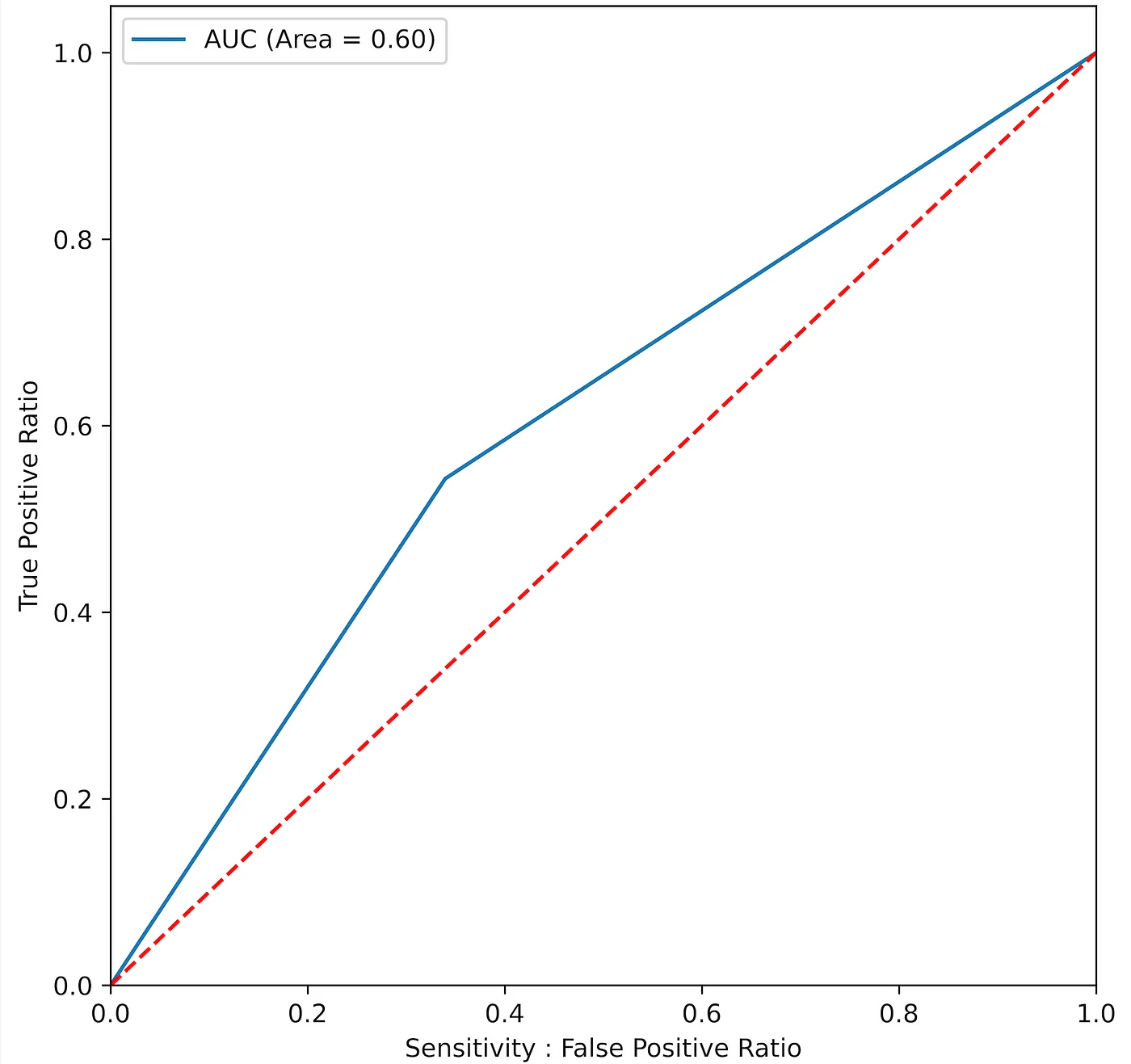
The main thing here is to minimize false negatives, leads that converted but predicted to not convert, as having more false negatives would mean missing out on key leads that can potentially make the company profit.
Feature Importance
Every lead has different characteristics, where they are based, the device they use, the time they registered, etc. Still, there’s a pattern in which leads that converted or leads that did not take, so in coming up with the predictions, the model identified that some of the features were more important than others in predicting if leads would convert or not, below we can see the feature importance.
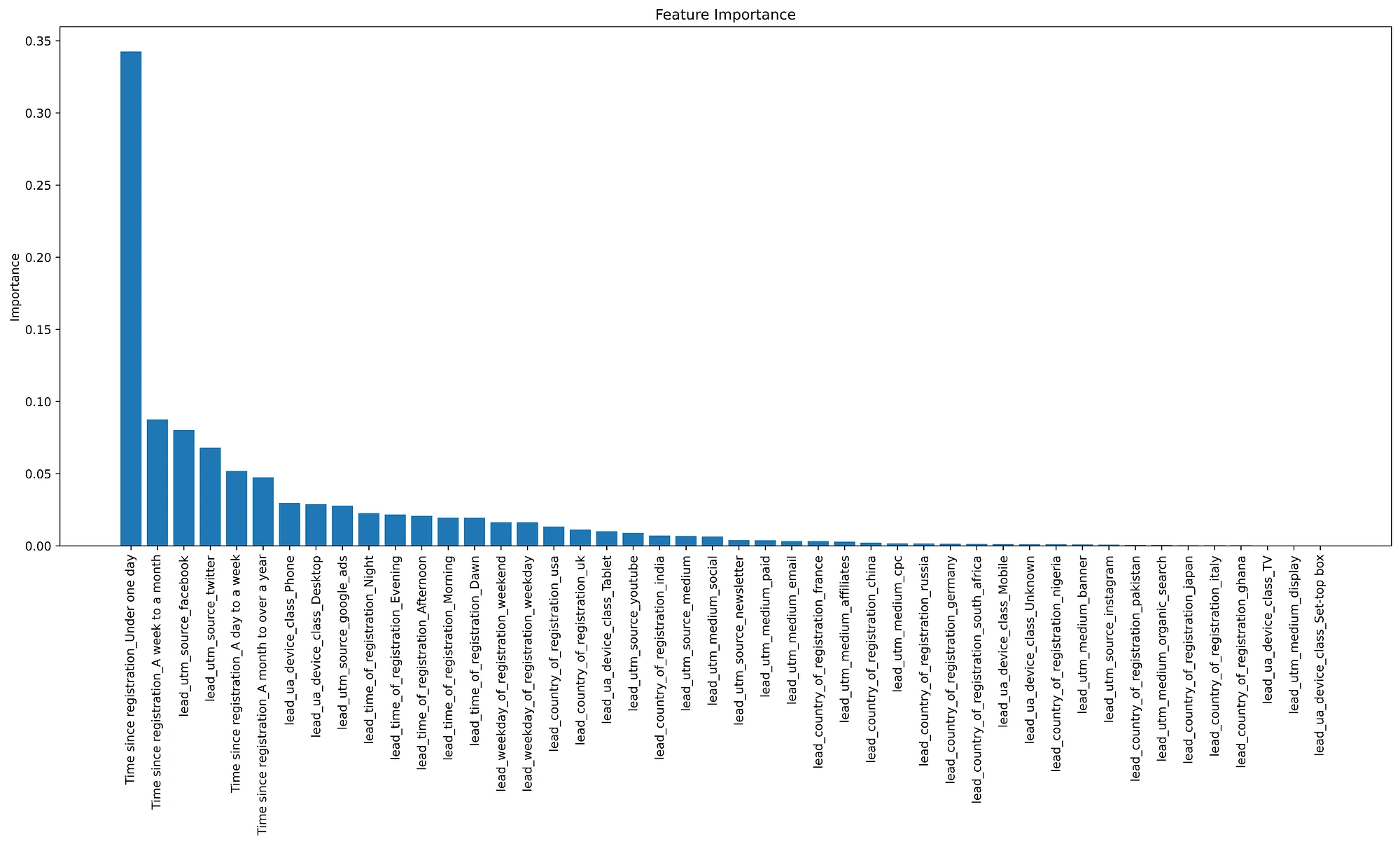
The most important feature in predicting lead conversion is if the lead visited the app twice on the same day, which makes sense as those leads have the highest interest in the app. Generally, the length of time between registering and subscribing is the most important in predicting leads that would convert.
The country where the lead is based does not seem to be a very distinguishing feature, as no country makes the top 15 important features, but it still is important to predict lead conversion. The feature that was the least important is if the lead uses a set-top box to access the app, as it is an outmoded device.
CI/CD & TESTING
GitHub Actions, which is my go-to CI/CD tool, was used here to automate the building, testing, and release. For this project, a very simple pipeline was built, which just installs dependencies, runs flake8 to make sure the code is readable and conforms to standards, and runs the testing to make sure the app is robust and would not break when deployed.
Pytest which is my preferred testing tool was used to build and run the unit tests, to make sure the app is behaving the way I expect it to. Very simple tests were written, such as:
Test to check if no null values are present
Test to check if the data is now balanced
Test to check if both training and testing data have the same number of records for both features and target
Test to check if predictions and testing data have the same number of records
MODEL DEPLOYMENT
Fast API was used to create a robust and scalable API for serving the predictive model, which takes the trained model and outputs a prediction, and streamlit was used as the front-end, to display the results in a nice UI that company leaders can use to access their leads.
The whole app was containerized using docker, so we can ensure that it runs consistently in any environment, regardless of the underlying system. Docker compose was also used to define the different services required for the application, which are the FastAPI and the streamlit, and run them all together in a single environment, as it allows you to easily manage and scale your services as needed.
How data is gathered from users for real-time scoring
To capture user data for real-time prediction by the ML models, these are some of the techniques used:
Track user interactions by capturing the local time of their device
Monitor the referral source to determine how users are coming to the app
Extract country information from their IP address
Calculate whether interactions occur on weekdays or weekends using timestamps
Store and analyze the time difference between a user’s first app session and subsequent visits or time converted.
Retrieve device-related data such as device type and operating system using user-agent strings
This data is obtained from each user as they interact with the app, and the data goes through the pipeline of cleaning, and feature engineering to a useable format and is passed to the web app(that would be shown in the next section) for real-time prediction to help understand which users are more likely to convert into customers.
WebApp Demo
Below is a demo of how the app works,
So as you can see from the simple demo above, based on the user's activities on the app, the model can predict if this lead would convert or not, so based on that, recommended actions would be taken.
The web app is only available to the mobile company and not for the users, as ideally the data is automatically populated as explained in the previous section, but here, I made it a choice so we can mimic user details being captured, so the company heads can make informed decisions.
Recommendations from predictions
When a lead is predicted to convert, it’s crucial to capitalize on its potential.

Firstly, craft personalized messaging that speaks directly to their interests and needs. Tailoring your communication and marketing efforts can significantly increase the chances of conversion.
Secondly, take proactive steps by providing timely follow-up actions. This can involve sending targeted emails, offering additional resources or demos, and providing incentives to encourage the desired action.
Thirdly, ensure your sales team is aware of these high-converting leads so they can prioritize their outreach efforts and deliver personalized attention.
On the other hand, when a lead is predicted to not convert, it’s essential to employ effective re-engagement strategies.

Begin by implementing targeted re-engagement campaigns such as personalized emails, offers, or relevant content to reignite their interest.
Next, focus on lead nurturing by placing non-converting leads into a nurturing workflow. Provide them with valuable information, educational content, and updates to stay on their radar and build trust over time.
Lastly, collect feedback from non-converting leads to gain insights into their reasons for not converting and use that feedback to inform future optimizations.
Additional Features to make the prediction more robust
Certain user information can be added to make the predictions more robust, and to better predict leads likely to convert. These additional features have a great potential to even increase the accuracy and hence convert more leads into potential customers.
Some of these features are:
Previous Interactions: Tracking and analyzing the past interactions of leads, such as previous purchases, inquiries, or engagement with specific content, can indicate their level of interest and propensity to convert.
Engagement Metrics: Monitoring user engagement metrics, such as the number of sessions, time spent on specific pages, click-through rates, or engagement with specific features, can help identify highly engaged leads who are more likely to convert.
CONCLUSION
Predicting the leads that are likely to convert is of utmost importance to companies, and to this mobile company as well. Many leads start the process and fall by the way, so being able to identify such promising leads that have a high possibility of becoming paying customers is crucial, so certain incentives can be afforded them to help them complete the process. People's minds can change at any time, but with the company’s intervention obtained from the knowledge gained from this project, knowing those that are likely to convert, can become paying customers to keep the business afloat and make the company profits.
Some key MLOPS principles were followed to develop this application and also some analysis to further understand the data to help build a more robust predictive model. This can be further worked on to become a usable app or integrated into an existing system to derive value to help reduce losses at a company and increase profit. Engineers can follow some of these principles to begin building apps that are robust and can create value.
Code used in this project can be found here → https://github.com/JoAmps/Lead_conversion_prediction_for_a_mobile_app_company
Like this project
Posted Mar 25, 2024
Built ML models to predict and optimise leads that are likely to convert in order to maximise a company's profit margin