High-Performance Global Trade Engine
Bruno Del Monde
Transforming 40 billion rows of raw UN trade data into actionable economic insights using custom C++ database extensions and optimized partitioning.
The Challenge: Wrangling 50 Years of Global Trade
The UN Comtrade dataset is the world’s most comprehensive repository of international trade, but its sheer scale, spanning over 50 years, makes it a significant engineering challenge. For this work, I set out to build a system that could not only store this data but perform complex economic calculations that would typically crash a standard relational setup.
The raw data was a "nightmare" of inconsistency: non-standard country codes, duplicated entries, and incoherent reporting across records. My first task was building a robust data-cleaning pipeline to normalize this information into a reliable source of truth without losing meaningfulness.
Technical Strategy: Building Inside the Engine
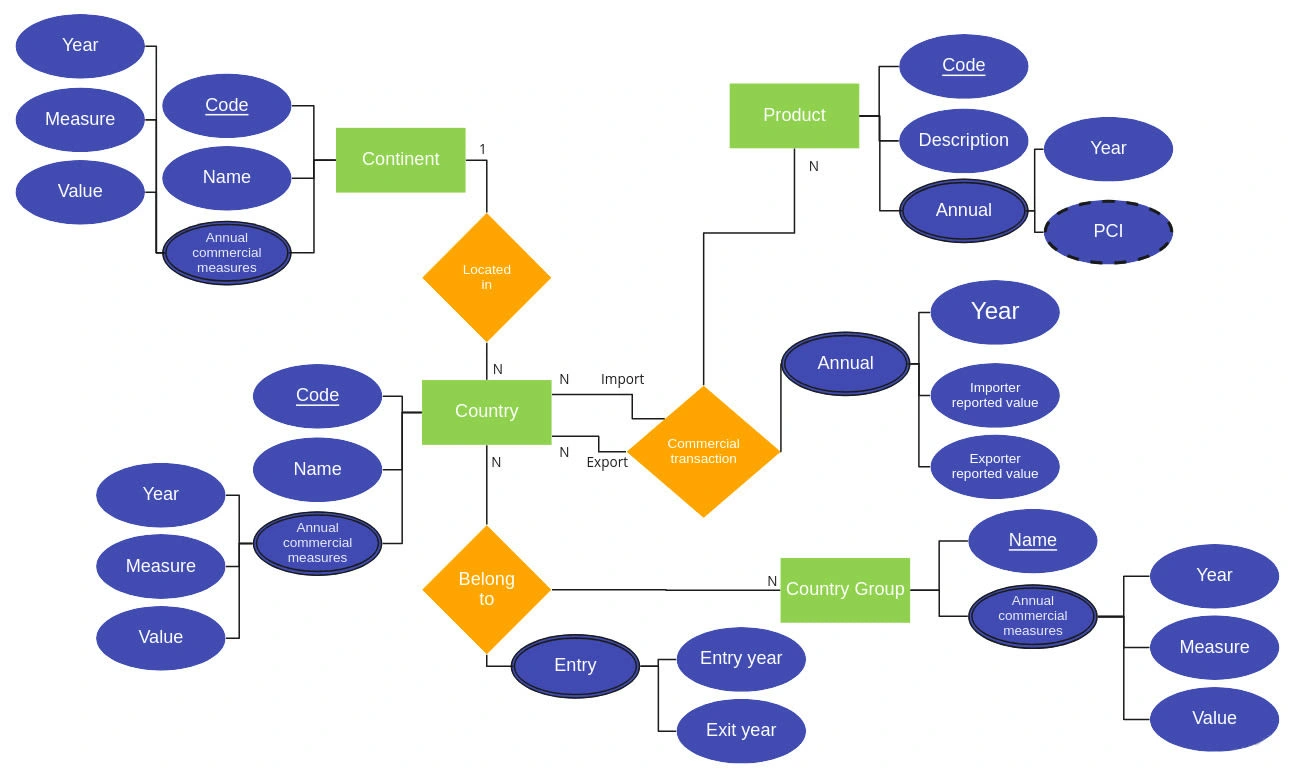
Entity-Relationship Diagram
To achieve the performance required for economic research, I moved away from "external" processing and moved the logic directly into the database.
Time-Series Optimization: I utilized TimescaleDB to implement a "Hypertable" strategy. By automatically partitioning 40 billion rows into manageable time-based chunks, I ensured that indexes remained small and queries stayed fast, regardless of the dataset's growth.
Custom C++ Extensions: Standard SQL isn't built for complex linear algebra. I developed custom functions using the PostgreSQL v1 interface in C++. This allowed the database to perform high-level memory management and heavy math at the binary level.
Parallel Computing: To handle the massive computational load, I integrated OpenMP. This enabled multi-threaded processing, allowing the database to saturate the server’s CPU cores during intensive calculation cycles.
The Breakthrough: Eigenvectors & Economic Complexity
The most demanding part of the project was calculating the Economic Complexity Index (ECI). This requires finding the second eigenvector of a stochastic proximity matrix, a task that is computationally expensive at scale.
By implementing this logic within a C++ extension, I was able to transform raw trade flows into sophisticated economic indicators through a single API call. This effectively turned a massive data lake into a highly efficient "Headless" analytics engine.
Results & Performance
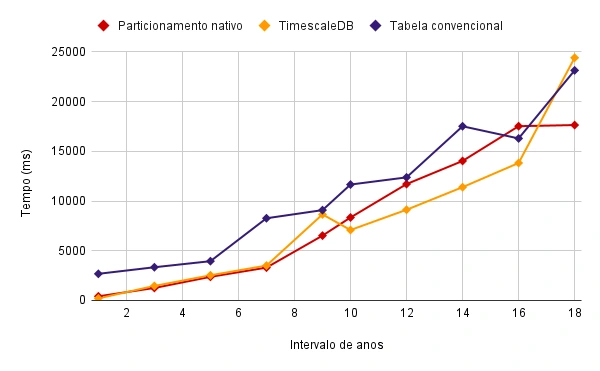
Query Time(ms)/Search Interval(years) Chart
I ran these stress tests on a subset of 62.7 million rows to measure the relative gains of the developed architecture:
34% Performance Gain: Compared to traditional relational models, the partitioning strategy provided a 34% speed increase for standard three-year interval queries.
Versatile & Multi-granular API: The system supports multi-level analysis by implementing a complete set of functions to perform calculations grouped in arbitrary geographical and category granularities with sane presets.
Reproducible Environment: The entire stack was Dockerized, ensuring that researchers could deploy the same high-performance environment on any infrastructure with a single command.
Like this project
Posted Feb 9, 2026
Transforming 40 billion rows of raw UN trade data into actionable economic insights using custom C++ database extensions and optimized partitioning.



