AI Learning Buddy – RAG Academic Assistant
Hamza Mooraj
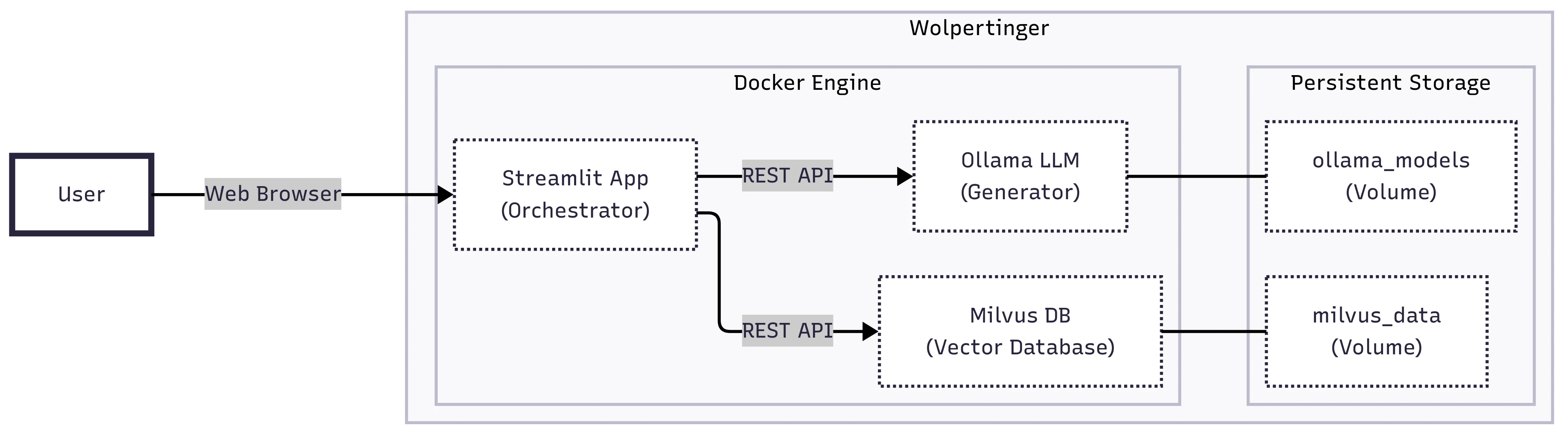
AI Learning Buddy – RAG-Based Academic Assistant (Proof of Concept)
Overview
I designed and implemented a Retrieval-Augmented Generation (RAG) proof-of-concept for an AI-powered “Learning Buddy” intended to support university students by answering course-specific questions grounded in official materials.
The system was developed during an internship and deployed on a university-managed server as a containerized, local-first solution.
Problem
Students often struggle to locate precise information within large volumes of course documentation (lecture slides, handbooks, PDFs).
The goal was to design a privacy-preserving AI assistant capable of providing fast, document-grounded answers without relying on external API services.
System Architecture
Document ingestion pipeline (PDF → Markdown → structured JSON)
Semantic embeddings using BAAI/bge-small-en-v1.5
Vector search via Milvus
Local LLaMA 3 model served through Ollama
Streamlit web interface
Docker Compose orchestration across services
The system was fully containerized to ensure portability and reproducibility.
Engineering Highlights
Designed multi-container architecture with persistent volumes
Implemented course isolation via
course_id filtering in vector databaseBuilt manual ingestion and indexing pipeline for structured retrieval
Eliminated paid API dependencies via local LLM hosting
Conducted manual evaluation using structured test queries
Proposed scalability roadmap (Kubernetes + distributed Milvus)
Features
RAG Architecture: Combines a vector database (Milvus) for information retrieval with a language model (Ollama) for text generation, ensuring responses are factual and relevant to the provided documents.
Course-Specific Queries: Supports multiple courses by isolating data based on a
course_id within the vector database.Local-First Design: Utilizes an open-source LLM (Llama 3) running locally via Ollama, eliminating the need for paid API services and addressing data privacy concerns.
Technologies
LLaMA 3, Milvus, Docker, Streamlit, Hugging Face
Workflow
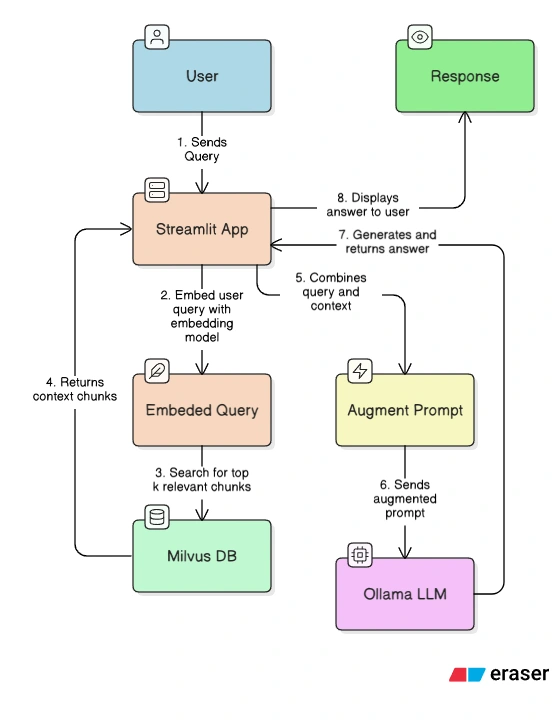
The sequence of events when a user submits a prompt to the RAG-enhanced LLM
Limitations & Future Work
This is a proof of concept with known limitations, primarily in its current single-server, single-user design. Future work would focus on:
Scalability: Migrating to a distributed architecture using Kubernetes and a managed vector database service like Milvus Distributed.
Automated Data Pipeline: Developing an automated system to regularly ingest and update course information from platforms like Canvas using API tokens, eliminating the current manual process.
Enhanced Models: Exploring the use of larger, more powerful embedding models and a transition to cloud-based LLM services for improved performance and reliability.
Personalization: Integrating with student profiles to provide personalized support (e.g., study plans, grade tracking).
Like this project
Posted Feb 20, 2026
Designed and deployed a containerized RAG-based academic assistant using Milvus and local LLaMA to ground answers in course materials.
Likes
0
Views
3
Timeline
Jul 15, 2025 - Sep 15, 2025
Clients
Heriot-Watt University



