RAG (Retrieval Augmented Generation) Pipeline
Hammad Tahir
Description:
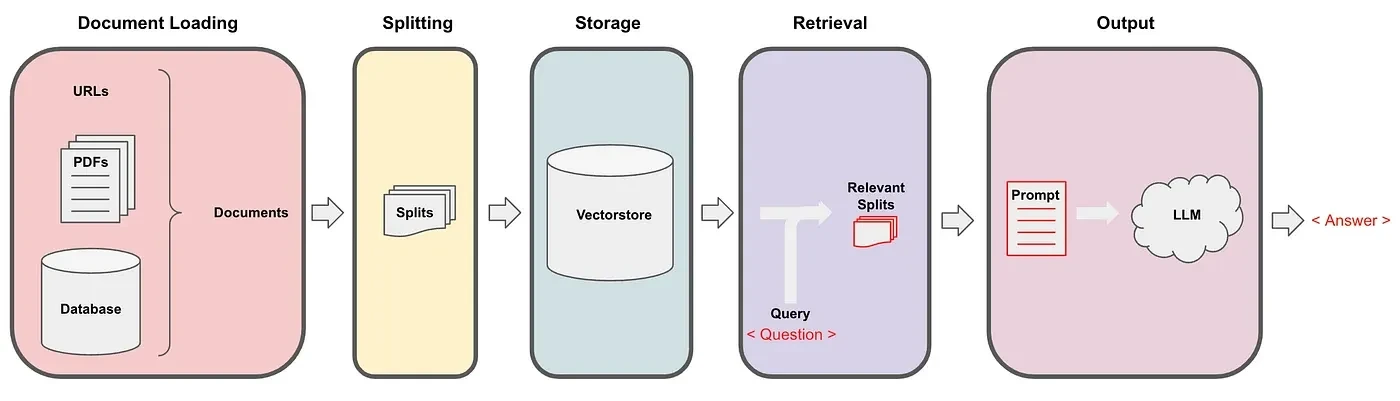
Unlock the full potential of Large Language Models (LLMs) with our innovative RAG Pipeline! This cutting-edge technology enables LLMs to answer questions based on specific documents, revolutionizing information retrieval and generation. Our pipeline seamlessly integrates loading, splitting, storing, retrieving, and generating text, empowering you to:
Load documents from various sources (webpages, PDFs, CSVs, etc.) using LangChain's document loaders
Split text into manageable chunks with LangChain's text splitters
Store and embed data in a vector store (Pinecone)
Retrieve relevant information using similarity search with LangChain's retrievers
Generate answers and engage in conversations using LLMs (OpenAI) with LangChain's chat models
Key Features:
Document loading and splitting with LangChain
Vector store integration (Pinecone)
Retrieval and generation using LLMs (OpenAI) and LangChain
Conversational capabilities with memory storage
Customizable prompts and templates
Benefits:
Enhance LLM capabilities with document-specific knowledge
Streamline information retrieval and generation
Engage in conversational AI with context-aware memory
Unlock new possibilities for AI applications
Frameworks Used:
LangChain (document loading, splitting, retrieval, and generation)
Pinecone (vector store and embedding)
Collaboration Opportunities:
Developers and researchers seeking to advance LLM technology
Businesses looking to integrate AI into their document management
Innovators exploring new AI applications
Like this project
Posted Apr 27, 2024
RAG Pipeline: Revolutionize LLMs with document-specific knowledge! Load, split, store, retrieve & generate text using LLM, LangChain & Pinecone.
Likes
0
Views
33




