Near Real Time Data WareHouse
Sreeram Melarkode
Project Summary
The Bank is looking to upgrade its existing Data Warehouse setup. While the current brief is to introduce caching in the DWH with a view to reduce the turnaround time for data retrieval for frequently queried requests, further changes to the architecture can build new capabilities with the same existing inputs. These include collating data pertaining to different timelines to be brought together to service the same request. Also, the ability to serve real-time or near-real-time data has a significant number of key use cases including real-time alerts for cases of credit card fraud.
Problem Statement
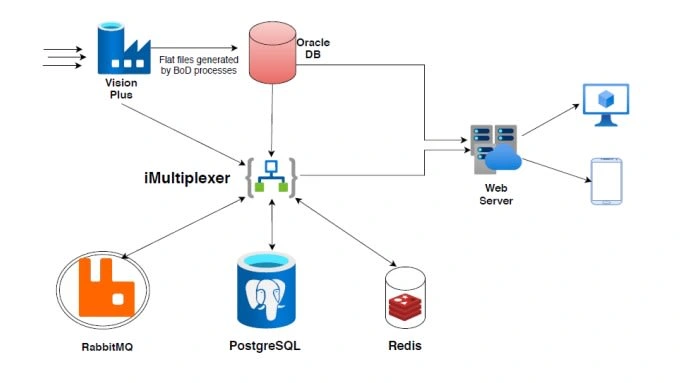
The Bank has an existing DWH solution that caters to credit card data. This is currently built on Oracle where data lies in re-normalised form, accessed through Stored Procedures. Input data is sourced as flat files from the source system and inserted into the Oracle DB through the BOD process. This Data Mart serves multiple customer-facing interfaces such as net banking, mobile banking and IVR through a set of approximately 30 APIs. Some of the tables in the Oracle DB would be accessed across APIs. Queries return usually 1-10 records of 10-15 columns each. All data served is on T-1 basis.
Solution Overview
These queries currently have approximately daily hits ranging from 5 lac calls a day to 20 lac calls a day. These tuned queries – at peak – have an execution time of less than 100ms. The first objective of the exercise is to implement Redis as a Caching DB and integrate it into the solution with a view to store frequently queried data onto cache and hence decrease the data retrieval time.
Further steps involved:
Implement Redis as a Key Value Database.
Write appropriate compression / fine-tuning / optimization logic involving in-memory data structures like list, set, hash-set or
sorted set, etc.
Run jobs to populate appropriate key values to Redis.
Introduce a persistence database like PostgreSQL.
Create a conduit using Kafka or RabbitMQ (depending upon volumes involved).
Modify APIs to incorporate cache retrieval.
Results
By bringing together T-1 data along with data from OLTP systems on a Near Real Time (NRT) basis, the bank was able to juxtapose past behaviour of their clients alongside fresh activity. This resulted in immediate identification of potential fraud cases as and when credit cards were used.
Like this project
Posted Apr 10, 2023
Architected a Near Real Time Data WareHouse for a large bank using In Memory and Key Value Database technologies.